CVPR 2019视频描述(video caption)相关论文总结
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者:
来源:
此文已经作者授权,未经许可不得二次转载
前几年的video caption论文总结如下:
https://blog.csdn.net/sinat_35177634/article/details/88568491
Streamlined Dense Video Captioning
这篇论文严格来讲是属于video caption的一个分支dense video caption(DVC),如图,在一个长视频中存在很多event,DVC的任务就是先找出这些events,然后对每一个event生成对应的caption。
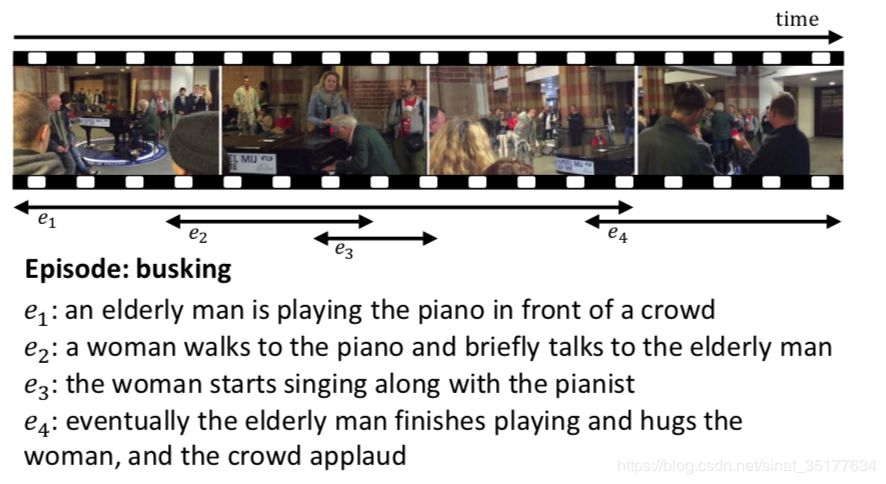
DVC这个任务从2017CVPR开始被提出,前两年的方法主要将这个任务分成两个模块,proposal和caption,也就是先提取event proposal,再对event进行描述,之前的方法主要集中于如何提高proposal的精度,如何得到更好的能表达event并且融合了上下文的特征。还有的方法集中于如何将这两个模块连接起来,实现端到端的训练或者联合训练,以期利用caption的结果来提高proposal的效果。这些方法都取得了比较好的效果。
这篇文章的作者提到DVC的关键还是再于event之间的关联性,并且提出在生成event对应的caption时考虑的上下文信息不仅要考虑visual的特征还要考虑caption的特征。同时为了达到这个目标需要对proposal进行排序,同时之前的方法在proposal阶段提到的proposal太多了,成百甚至上千,而在数据集activitynet上每个video平均有3.85个event,所以使用这个sequence模块也可以极大的减少proposal的数量,并且在之后的实验中也证明了更接近数据集的proposal数量可以得到更好的效果。
总的来说,论文具体的贡献有三点:对proposal进行排序得到一个episode,并且减少了输入到caption模块的proposal;在caption模块生成序列的caption,也就是不仅考虑前文的visual特征还要考虑caption的特征,得到更加连贯的caption;同时还使用了强化学习的训练方法,reward同样也从event即单独的caption,和episode即连贯整体的caption来考虑。
和之前方法对比示意图如下:
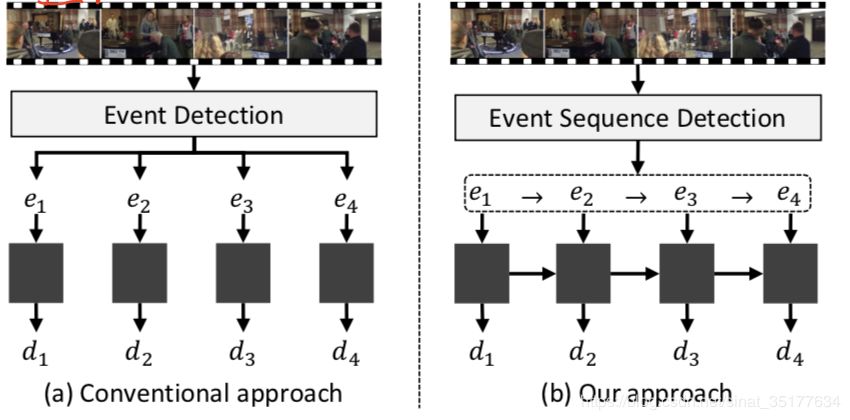
之前的方法独立的提取event,并且独立的对每个event特征生成caption。文章提出的方法,对提取的event进行排序,并且生成序列的caption,加强caption之间的关联。
具体的流程图如下:
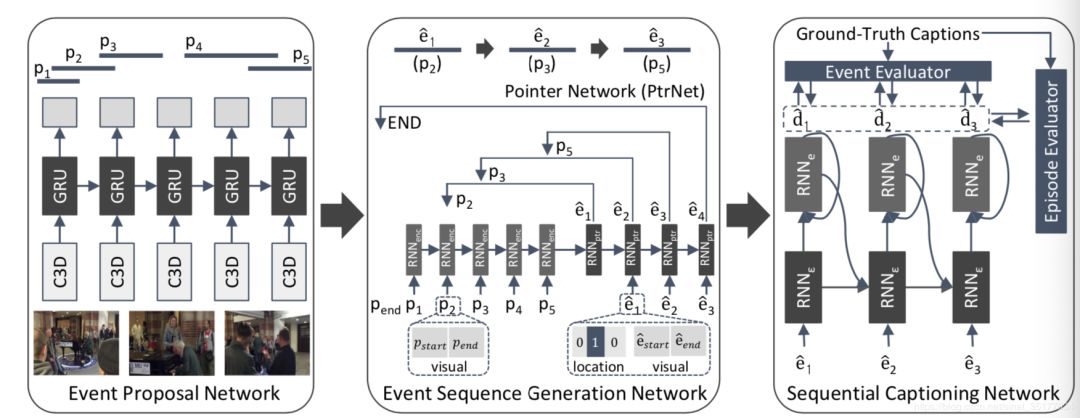
EPN模块提取event,使用的是2017 CVPR的SST方法,ESGN模块来对event排序,并且选择event,具体方法使用RNN模型先将候选集中的proposal按照开始的时间顺序排序输入到RNN中,在之后的每步生成对候选集中每个proposal的一个概率,选择概率最大的为当前时间的event,直到输出end event。
在SCN阶段,使用双层RNN模型以event序列做为输入,生成序列的caption,每步不仅要考虑当前event的特征,还要考虑之前的特征,不仅包括visual特征还有caption的特征。并且使用强化学习的方法训练。
EPN的损失函数,使用的是SST方法标准的损失函数:
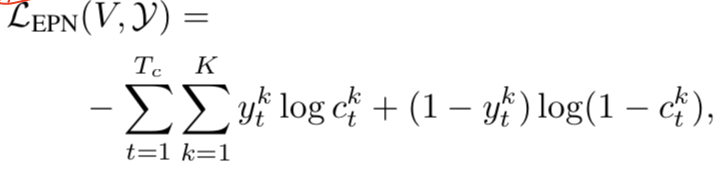
ESGN损失函数:
a当前第m个proposal为认为是GT序列第n个proposal的概率,这里使用了类似二分交叉上损失。
SCN损失函数:
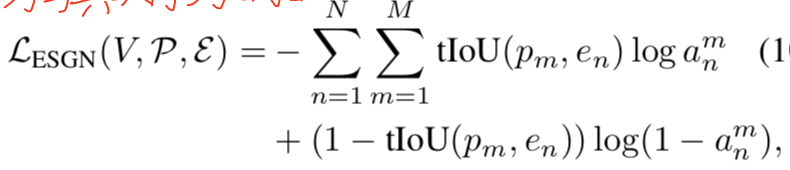
使用的是强化学习的损失,d为第n个event生成的caption,其中的R为:
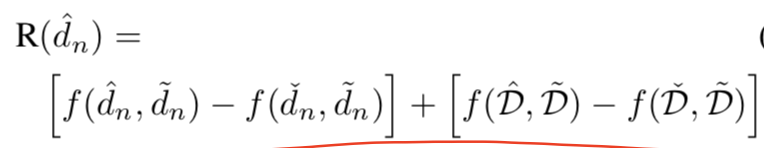
包含两个部分:对当前event caption的评价,和整个episode的captions的评价,考虑到了整个caption序列的连贯性。
实验结果如图:
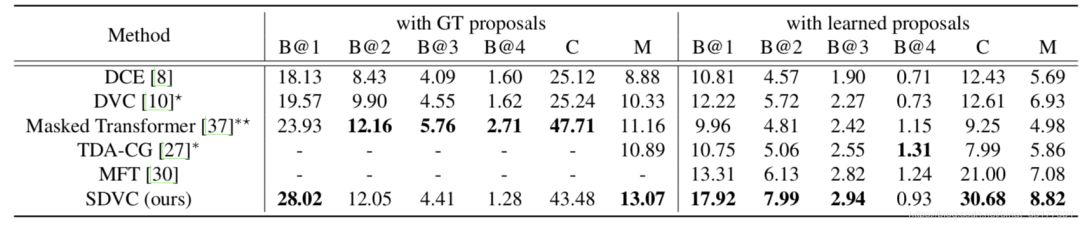
可以看到在使用GT和learnt proposal两方面均有比较大的提升,尤其是GT proposal,这说明生成序列的caption并且使用RL训练是非常有效的。同时也证明了生成序列的proposal不仅减少了proposal的数量,减少了冗余,并且可以得到更接近GTproposal的数量和event。
这篇文章加了event sequence的模块,但是为了训练这个模块需要手动生成GT的event序列,这无疑是费时费力的。同时文章也提到了在生成caption时只使用了之前的上下文特征,因此可以考虑使用双向的RNN来生成caption,因为我们直到当前event不仅于之前的event有关还和之后的有关,并且也可以使用双向SST来提取proposal。
论文链接:https://arxiv.org/pdf/1904.03870.pdf
Spatio-Temporal Dynamics and Semantic Attribute Enriched Visual Encoding for Video Captioning
这篇文章是传统的video caption任务,输入的是视频片段,仅包含一个动作,可以使用单个句子来描述。在之前的方法中也是使用encoder decoder模型,先对视频进行编码再decoder得到caption。但在之前的方法中视频编码阶段做的比较粗糙,使用2D/3D CNN模型来处理视频,处理得到的特征序列之间使用mean pooling这样就失去了视频的时序信息,也有使用softattention的方法,还有使用LSTM来得到时序信息的方法,但作者认为这些方法都太粗糙了,于是提出使用层级的快速傅立叶变换来得到视频的时序信息,并且作者也考虑到了高层的语义信息,主要考虑两个方面:空间的语义信息,也就是视频中的object信息;还有视频的action信息,加入这两个语义信息,从而丰富视频特征。具体的流程如下:
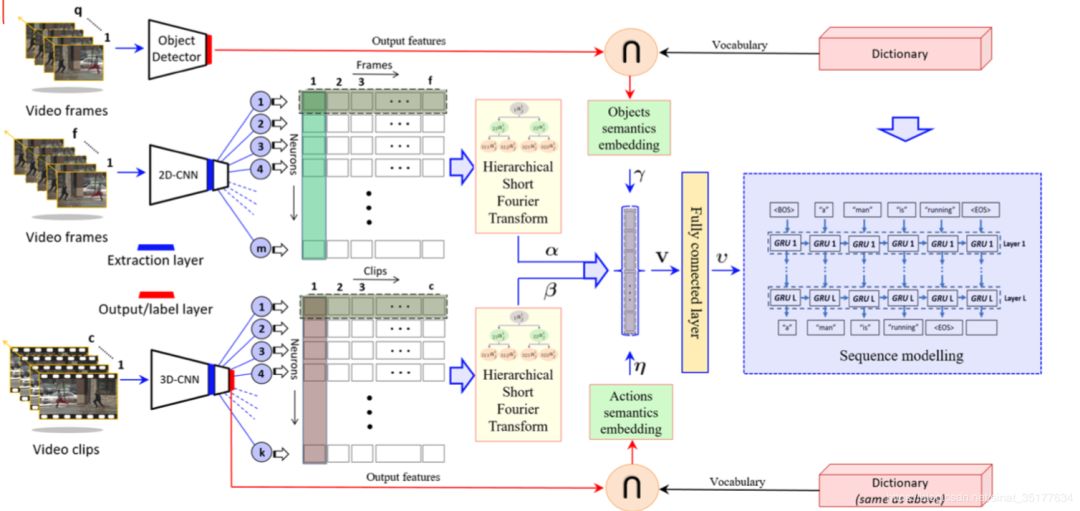
先对视频进行特征的提取,即使用2D CNN模型也使用3D CNN模型,再对每个神经元的输出使用层级的SFT如图,先对整个维度处理,再对维度二分处理,在二分在处理。再将这些处理后的特征融合,得到视频的时序特征信息。
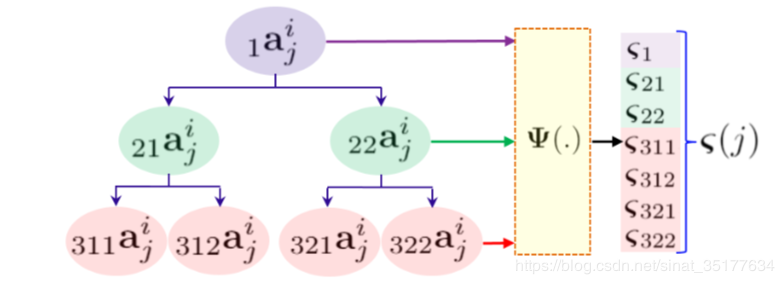
在提取空间的高层语义信息阶段,使用目标检测YOLO,再将检测的结果和词典取交集,得到最终的object,再对这些object编码:
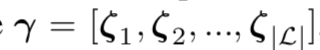
一共L个object,对每个object编码:
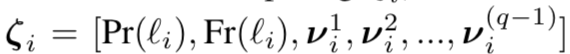
其中对每个object采样有q帧,Pr代表概率,Fr代表object在采样集中出现的频率,v代表object在帧序列中的偏移。
在得到action的语义信息阶段,先对3D CNN模型得到对action的预测,再和D取交集,得到最终的action,特征表示:
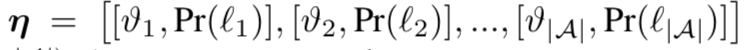
v为是否预测了这个action,Pr为预测的概率。
最终串联这四个特征作为输入到caption model的特征,实验的结果如下:
在MSVD数据集的结果:
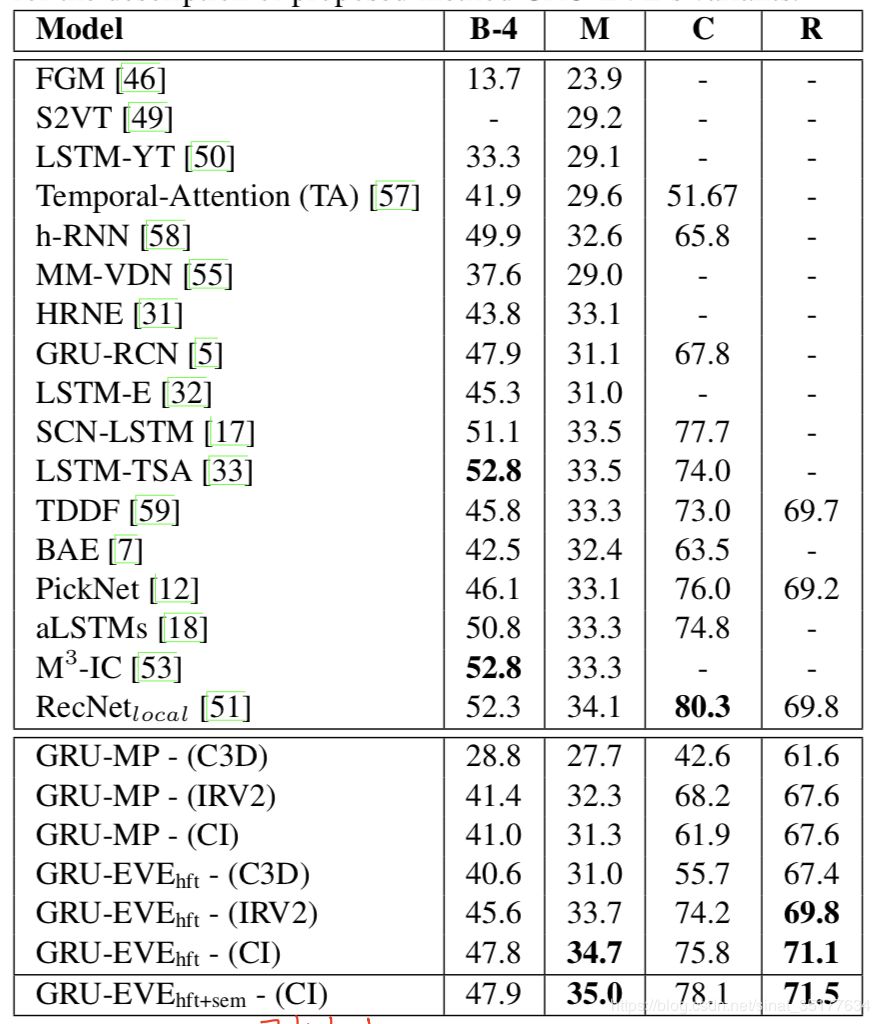
可以发现提升的结果不是很多,作者认为是在caption model的方法比较简单,只是双层的GRU网络。
在MSR-VTT的结果:
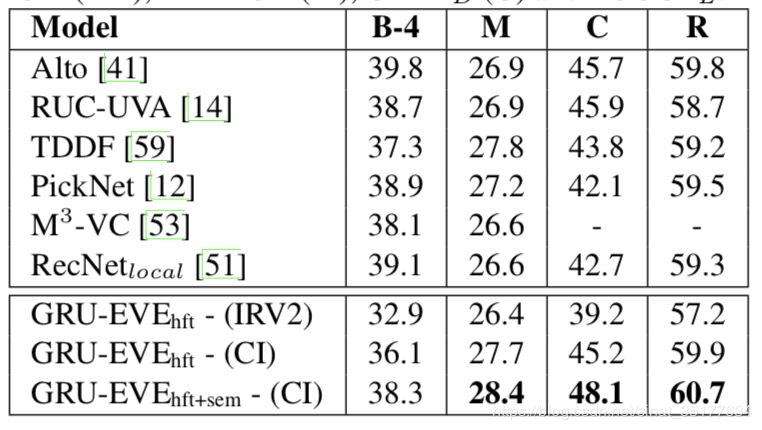
发现结果提升的还不错。说明使用HFT来提取视频的时序信息和加入两种语义信息都是有效的。
对于这篇文章可以考虑使用别的方法而不是HFT方法来得到时序信息,可以尝试使用LSTM。并且加入这两种语义信息,虽然有效果的提升,但是毕竟借助了字典和两种辅助的方法:目标检测和action 预测。可以说是三种方法的融合才达到了这种效果。再训练时也不能得到端到端的训练,训练的时候可能会比较的麻烦。
论文链接:https://arxiv.org/pdf/1902.10322.pdf
Grounded Video Description
这篇文章的主要贡献在于提出了一个新的密集事件描述数据集activitynet-entities,在activitynet的基础上加入box的区域标签。由于视频数据集的数据量较大,文章采用了稀疏标注的方法,先对video切分为多个segment,在每个segment中,标注box以及对应的类别,并且每一类在segment中只标注一个。使用activitynet-entities来生成描述,来使caption中的NP(名词短语)和video中的object对应起来,使生成的caption更加具体和精准,如图:

生成的caption中的名词可以对应到视频中的具体object中来,而之前的方法生成的caption并不具体。
activitynet-entities数据集标注的例子如图:

再使用activitynet-entities数据集来训练caption生成的模型,模型的具体流程如下:
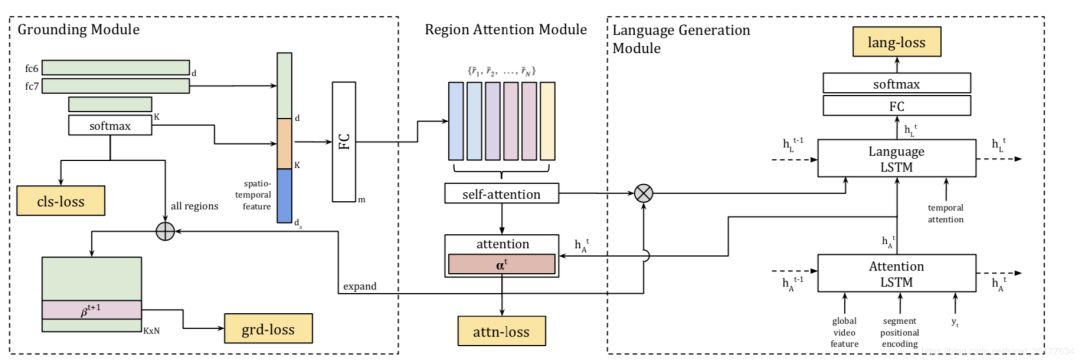
模型分为三个部分:grounding、attention和language generate
在grounding模块,对帧的特征map来进行box detection,并且和GT box计算IoU,筛选出IoU高于阈值的box,并且对box中的object进行分类,将box的位置信息和类别信息融合,作为region的特征。
在attention模块,使用self-attention对这个视频所有筛选出的region特征进行attention,最终得到这个视频的表示,再输入到language generate模块,使用LSTM网络来生成最终的caption。
模型的总体损失如下:
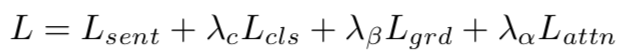
Lsent为生成caption的损失,Lcls为对区域内目标分类的损失,Lgrd为对区域位置的损失,Lattn为对region进行attention时的损失。同时在生成caption时还使用了temporal attention。
实验的结果如下:
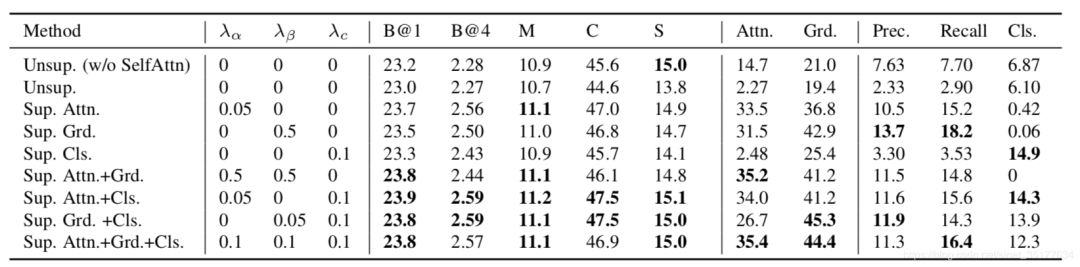
Unsup为没有使用数据集中box的标注信息,可以看到使用box的区域信息对结果还是有提升的,但是在具体各个模块的作用上没有较大的区别。
与之前的方法比较:

和2018年的使用activitynet数据集的方法相比有一定的提升,但是并不明显,可以考虑可能是在检测box的时候并不精确,准确率和召回率只有11.3%和15.9%,并且比较没有使用box标注的模型,这两项也只提升了4%和8%。
可以看出提出activitynet-entities数据集是文章的主要贡献,但是在生成caption的方法上还是有待提升的。
论文链接:https://arxiv.org/pdf/1812.06587.pdf
Object-aware Aggregation with Bidirectional Temporal Graph for Video Captioning
这篇文章是针对短视频的描述,即每个视频仅使用一句话描述。文章的创新点在于提取出了视频的关键object,并且对它们构建双向时序图,再根据双向时序图来提取这些object的特征,再融合使用整个视频提取出的全局特征来生成描述,实验证明对结果有显著的提高。
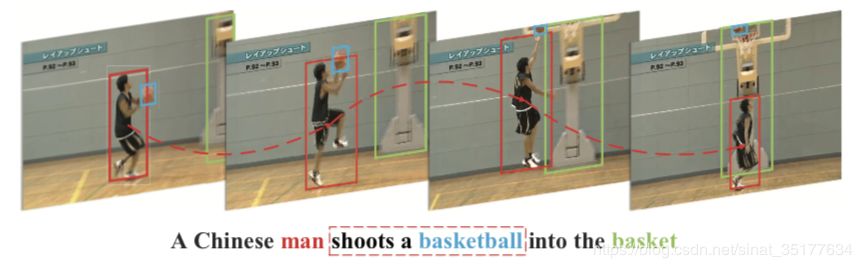
如图在一段视频的关键帧上找到同一个object,构成了时序图,再通过时序图生成描述,更能抓住object的动作信息,比如途中的投篮动作。
主要流程如图:
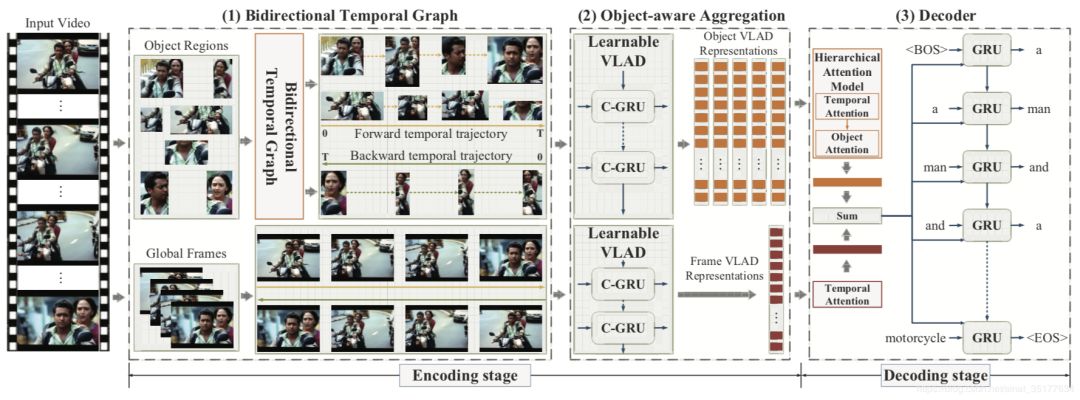
模型主要分为三个部分,双向时序图的构建,对区域特征和全局特征的编码,和对描述的生成。
在双向时序图构建模块,先使用目标检测处理视频的关键帧,提取出N个object区域,再利用相似性度量来构建一个object在整个视频中的时序图,而相似性度量的anchor就是第一帧的object(在正序中),在逆序中anchor为最后一帧的object,相似性度量的公式如下:
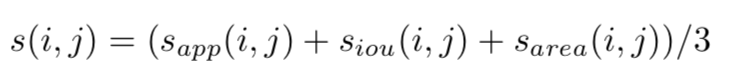
其中的三部分分别是对区域特征的相似性度量、区域IoU的计算和区域之间面积尺寸的差距。在两帧之间,计算相似性最大的两个区域,最终构成了双向object的时序图。
在特征编码模块使用了VLAD模型,VLAD模型以C-GRU为单元,C-GRU是GRU网络的变种,和卷积神经网络结合,公式如下:
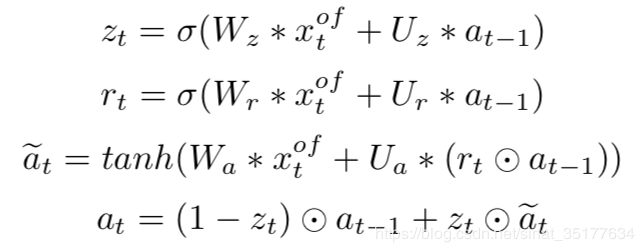
其中x为区域的特征,a为C-GRU的隐层变量,W U为2D卷积核,使用以上公式来一步一步更新隐层特征。
同时VLAD模型设置了K个聚类中心,使用视觉词汇c表示,并且对这些局部特征x使用最近邻的策略来归类到某一个聚类,用如下公式来编码区域的特征:
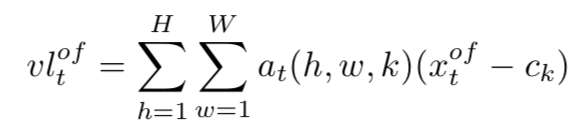
其中ck为x被归到的聚类中心,H W为x区域的高和宽,最终得到了区域序列的特征表示,这种表示a包含了区域序列的时序信息,又将object归到某一个类别中,包含了区域的时空信息。再用这种VLAD模型对逆序的区域序列和全局帧的正逆序列处理,得到了四组特征序列。
在decoder模块,先使用attention模型对上一步生成的区域序列特征和全局区域特征来整合,以正序的为例,对区域序列特征使用时空attention,对全局的序列特征进行时序上的attention,最终输入到GRU模型中来生成描述:
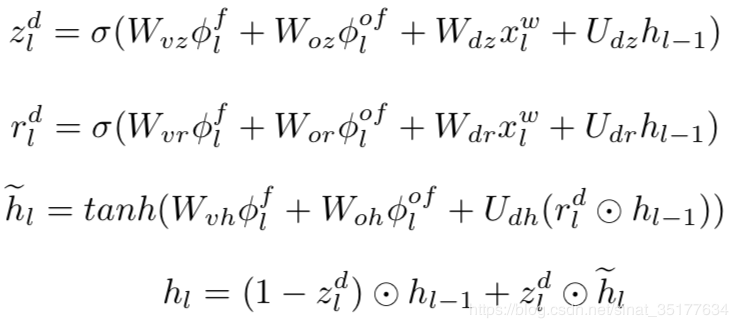
得到每步预测单词的分数后,再融合逆序的特征得到的预测单词的分数,来生成最终的word。
文章在MSVD和MSR-VTT数据集上均进行了验证,结果如下:
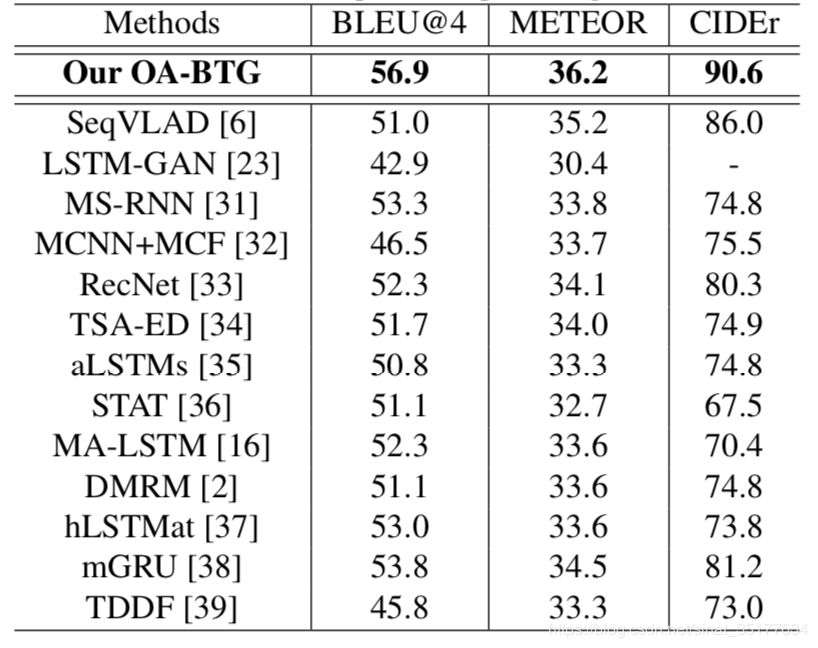
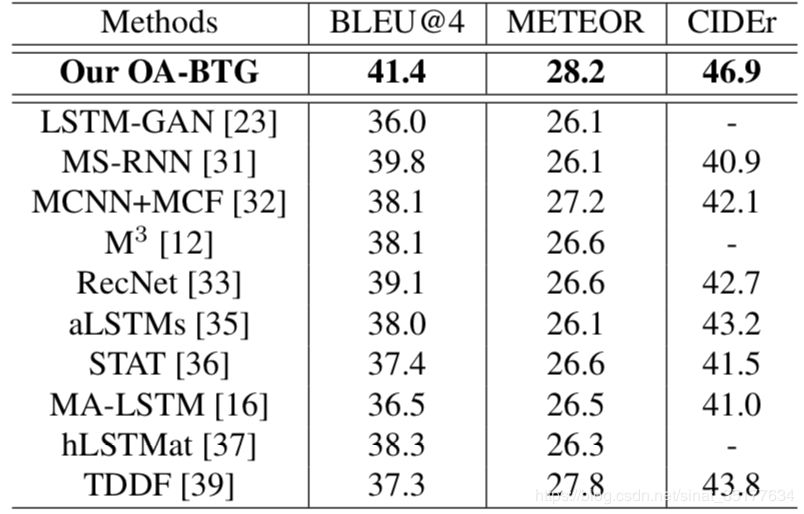
可以看到结果均有较大的提高。
但同时文章提出了这个方法的问题,不能很好的处理object之间的交互信息,仅仅对object序列进行独立的处理,因此生成的描述质量有待提高。
论文链接:https://arxiv.org/pdf/1906.04375.pdf
Memory-Attended Recurrent Network for Video Captioning
这篇文章也是针对短视频的描述,在传统的encoder-decoder基础上加入attended memory decoder模块,用于辅助基本的decoder来解码生成描述,称其为MARN。而attended memory decoder的基本思想是想寻找候选词汇和包含它的所有视频的特征的关系。文章认为之前的方法在生成描述时仅仅针对单一的视频而没有使用其他的视频信息。其实一个词汇和多个视频都有关系,因此文章希望找出这些关系,用来帮助decoder模型更好的生成描述,如图所示:

MARN模型在生成的描述比传统的encoder-decoder模型用词更加精确,而正是由于找到了词汇和其他视频的关联关系,生成描述时融合了其他视频的特征。
MARN模型的流程图如下:
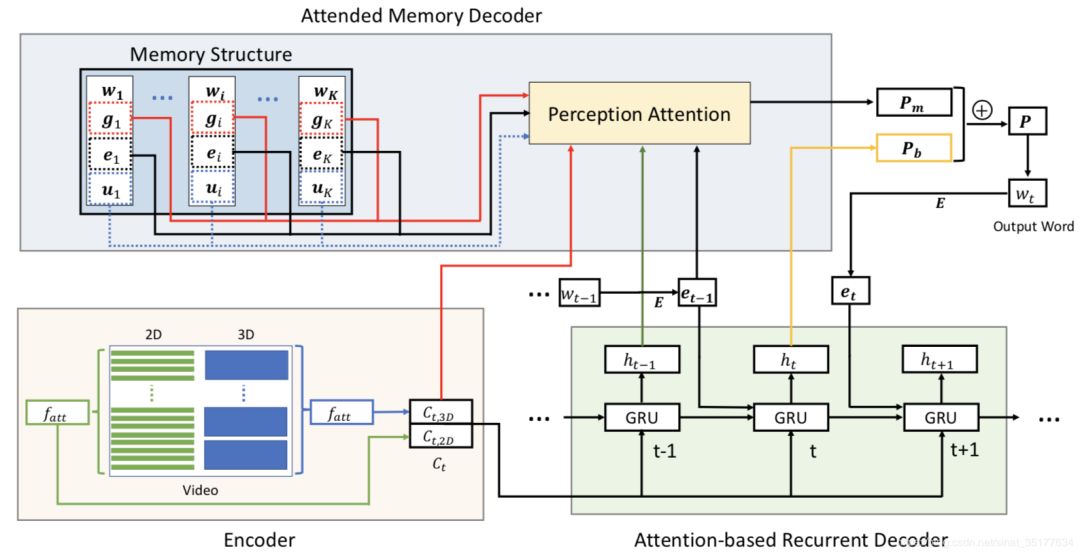
共三个部分,encoder、传统的decoder模型和attended memory decoder模块。
在encoder中使用了attention机制,先对视频进行2D和3D特征的提取,并且对他们分别进行attention的处理,再将attention后的特征串联为最终的这个视频的特征表示。
在传统的decoder中,使用GRU模型来生成描述,预测单词的的概率公式如下:
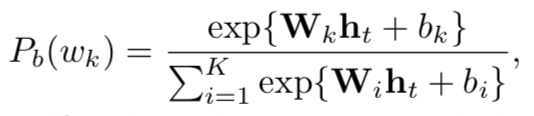
其中ht为每步生成的隐层特征,公式如下:
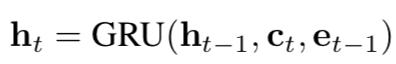
其中ht-1为上一步的隐层特征,ct为之前的视频编码特征,et-1为输入的上一步词汇的表示。
在attended memory decoder模块,主要是生成词汇和对应特征的映射,如下:
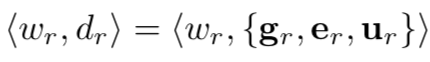
其中w为词汇,gr为和其有关的视频的特征,er为其词向量表示,ur为辅助的特征,在本文中ur是对应视频的类别信息。
生成gr的图示和公式如下:
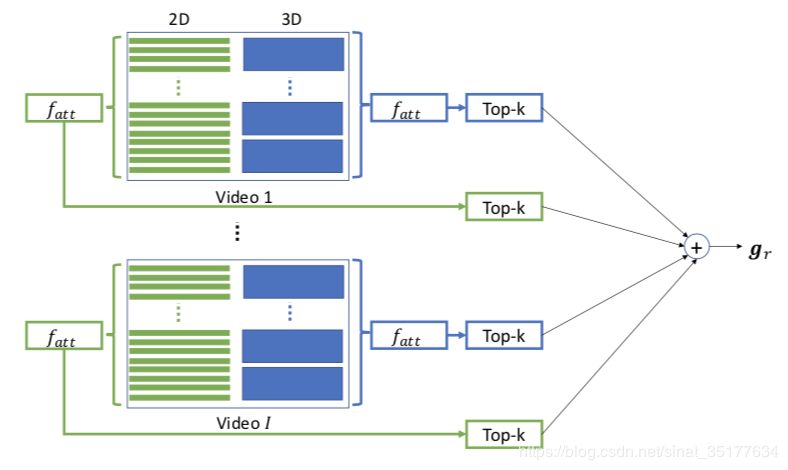
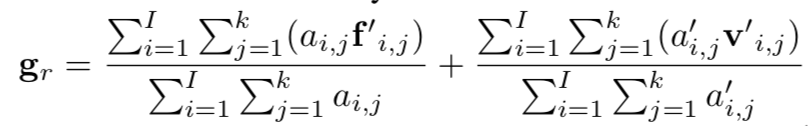
对于和词汇r相关的所有视频,分别对他们提取2D和3D的特征,在对他们进行attention处理,进行标准化再加和就是gr。但是文章并没有提到如何选择和词汇r相关的视频,可能是手动选择。
使用attended memory decoder模块预测下一个单词的概率公式如下:
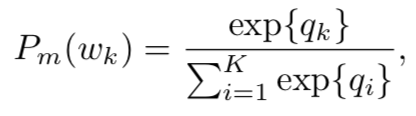
其中得到q的公式如下:
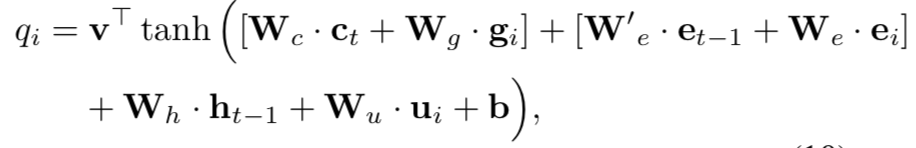
ct为对应视频的特征,gi为词汇对应的全频谱特征、et-1为上一步的词汇的词向量、ei为词汇的词向量,ht-1为上一步的隐层特征,ui为辅助特征,其他为带训练的参数。
再融合这两个概率为最终的概率:
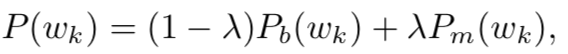
在损失函数方面,除了传统的交叉熵损失,文章还提出一个attention-coherent loss,文章认为在对2D特征进行attention时,相邻的两帧的权重应该是相近的,即权重应该是平滑的,AC loss的公式如下:
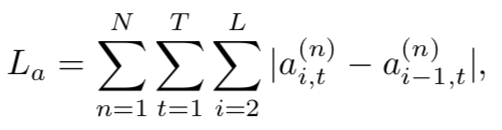
在训练阶段,先训练传统的encoder-decoder两个模块,使用训练好的视频的2D 3D特征和attention机制的权重来应用到attended memory decoder模块中,在训练整个模型,得到最终的视频描述。
实验的结果如下:
在MSVD的结果:
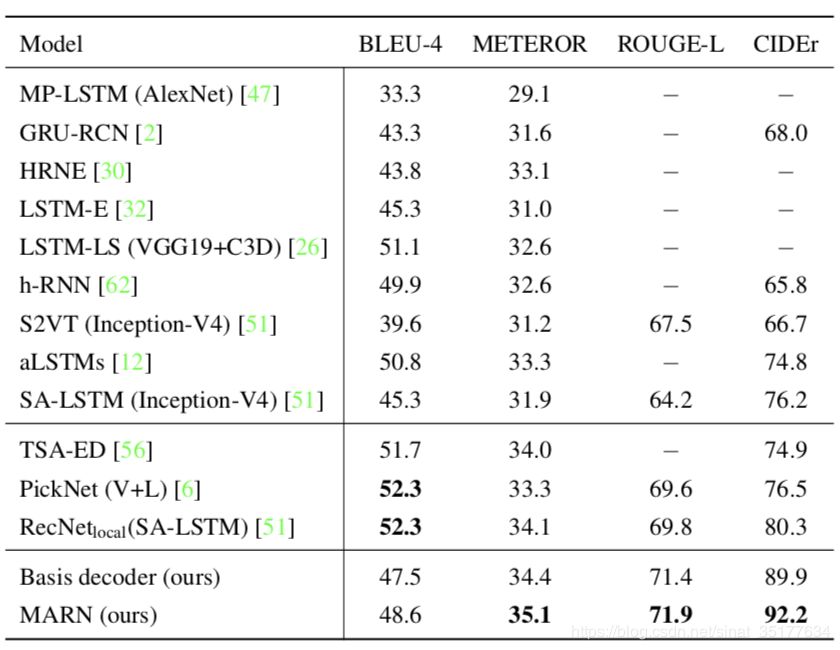
在MSR-VTT上的结果:
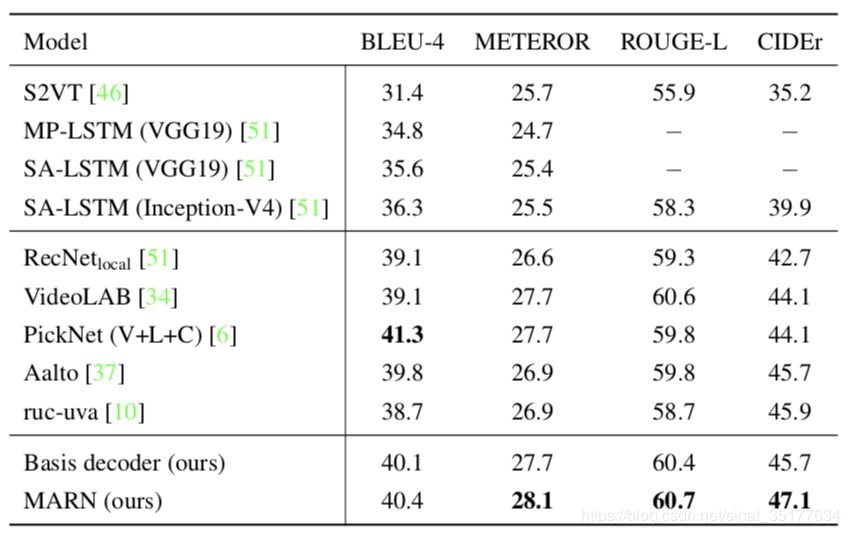
可以发现除了BLEU-4,其他的评价标准均有较好的提升。
这篇文章主要是加入一个decoder模块来辅助生成描述,这个模块包含了所有和对应词汇相关的视频信息,因此特征更全面于是有较好的结果。但是可不可以考虑直接使用这个attended memory decoder来直接最为解码的模块,而不使用传统的decoder模块,因为这两个decoder和一定的冗余,可能导致性能的下降。
论文链接:https://arxiv.org/pdf/1905.03966.pdf
Adversarial Inference for Multi-Sentence Video Description
这篇文章所要解决的问题是针对长视频生成多句描述,使用的数据集是DEC。在之前的方法中在处理DEC数据集时分成两个阶段,segment proposal和caption generation,先将长视频分为多个event,再提取视频的特征来生成针对event的单个描述,最终整合为整个长视频的描述。但是这篇文章指出,这种方法生成的描述虽然单个event看来生成的较好,但是从整个长视频来看,这些描述之间和冗余并且不连贯,同时缺乏多样性。因此,这篇文章提出方法来生成针对整个长视频的多句描述,并且使这段描述不仅准确而且多样连贯,句子之间没有冗余,使用的数据集同样是DEC,但是文章假设segment已经给出。如图所示,红色加粗为不准确的词组,蓝色为冗余的信息,之前的方法这种冗余较多,而文章提出的方法较少。

文章提出方法的基本流程如下:
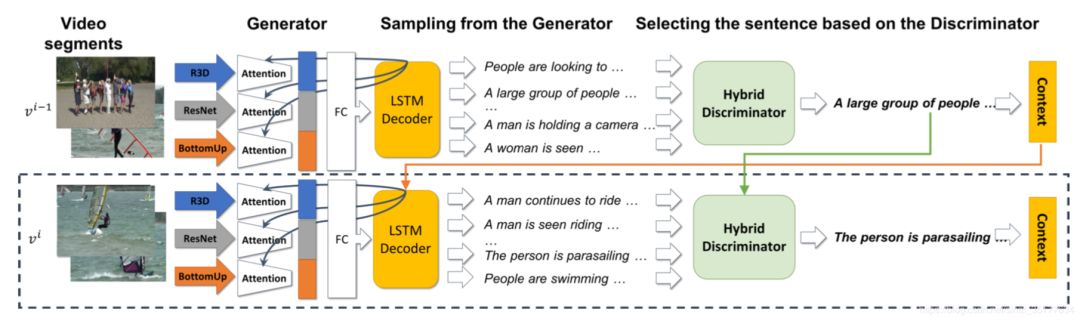
模型使用了对抗学习的思想,设置一个生成器G和一个判别器D,G生成多个针对event候选的句子,在使用D来选择最优的句子,同时为了保证生成句子的连贯性,生成的句子信息将加入到生成下一个句子的特征中来。
生成器G的公式如下:
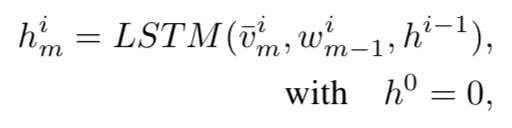
在生成的第m步,使用LSTM网络来生成代表event的隐层表示,再使用这个隐层表示和softmax来预测最优的单词。v代表视频的特征,由三部分组成分别是针对帧级的特征,使用3D卷积的特征和提取区域的特征,并且在事件维度上均使用了attention,再将三个特征整合起来,再使用FC来得到最终的特征。w为生成的上一个单词的词向量表示,h为生成上一个句子的隐层表示。
在之前的使用对抗网络的方法中,D的公式如下:
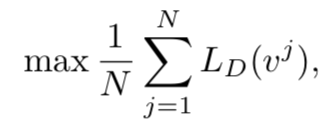
其中LD的公式如下:
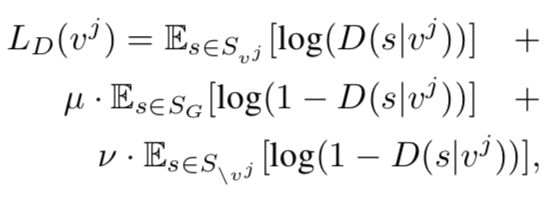
其中Svj为针对event j真实的描述,SG为针对event j生成的描述,其他的s为其他event的描述,以此来训练D,从而提高G的生成能力,并且使用强化学习的方法来训练,在测试时使用G生成的句子为描述。
而本文使用的D如下图所示:
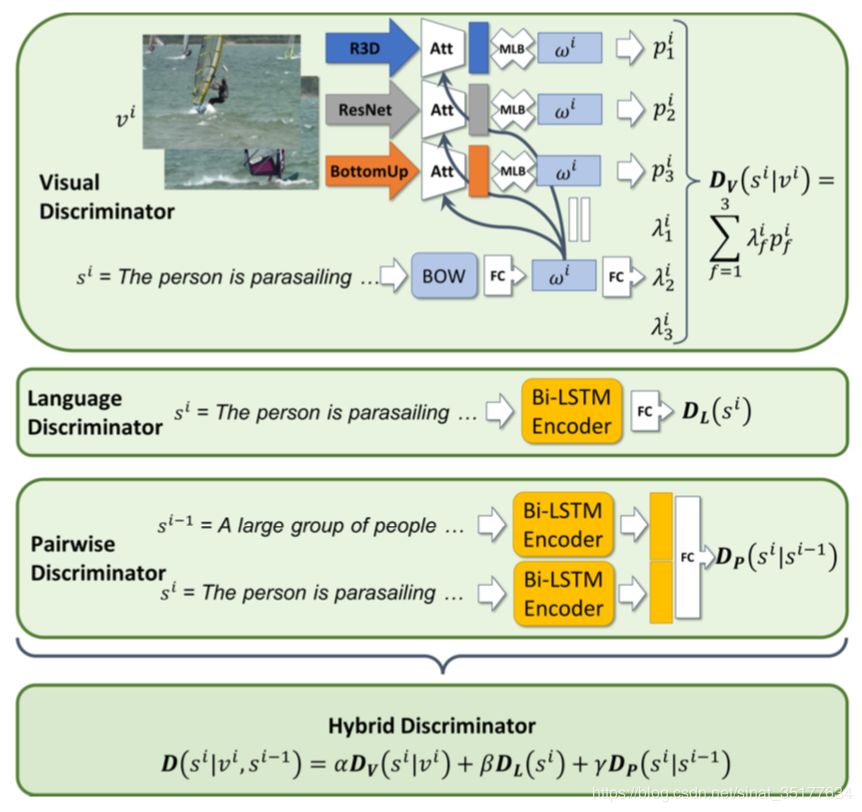
使用Dv来判别句子和对应event的关联程度。DL来判别句子的结构和语义信息,Dp来判别句子之间的关联性。
Dv同样提取了三种的视觉特征,同样使用attention,但是和句子相结合,而句子的特征为了不提取出语义结构等信息,使用BOW词袋特征来表示。并且这三种特征分别得到一个分数,公式如下:
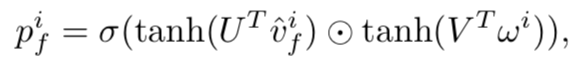
U V分别的参数,再使用单词的特征w生成三个对应的权重,加权得到最终的分数。
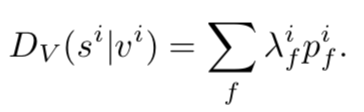
而DL直接使用LSTM模型来得到句子的隐层表示,再使用线性回归得到分数:
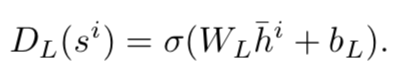
Dp是找到两个相邻句子的关系,因此使用双向LSTM来提取两个句子的特征,再使用线性回归得到分数:
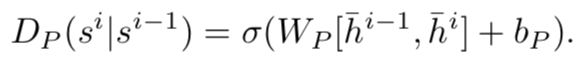
最终将这三个分数加权整合为一个最终的分数:
再在候选的句子中选择分数最高的为最优的描述该event的句子
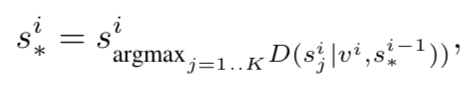
实验的结果如下:
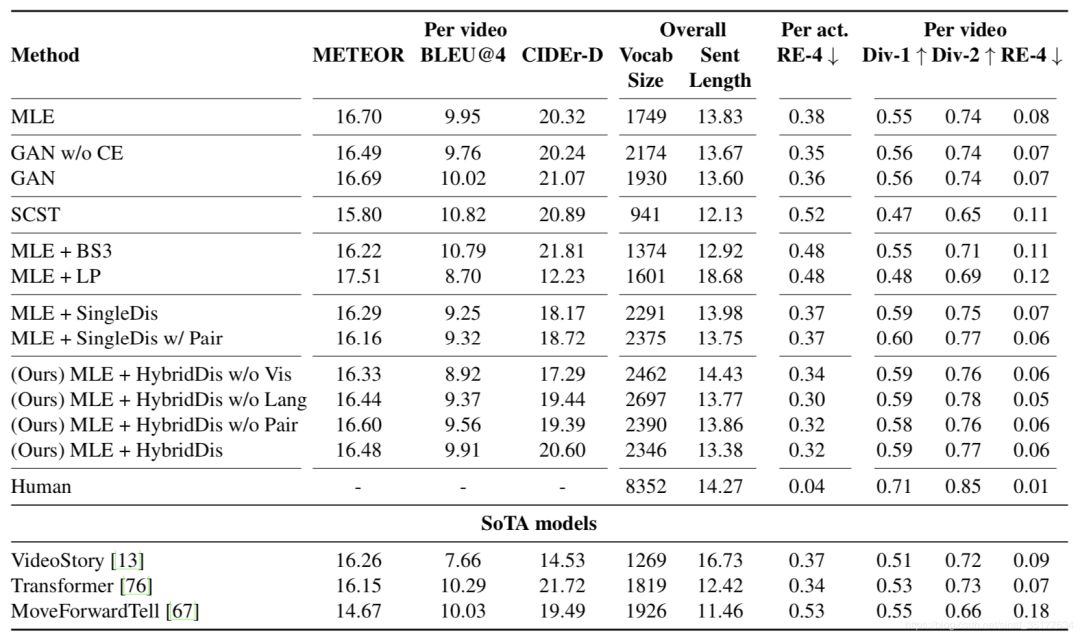
发现其实结果并不理想,自动评价指标并不是最优的,但在多样性和流畅度上有一定提高。
人工评价结果如下:
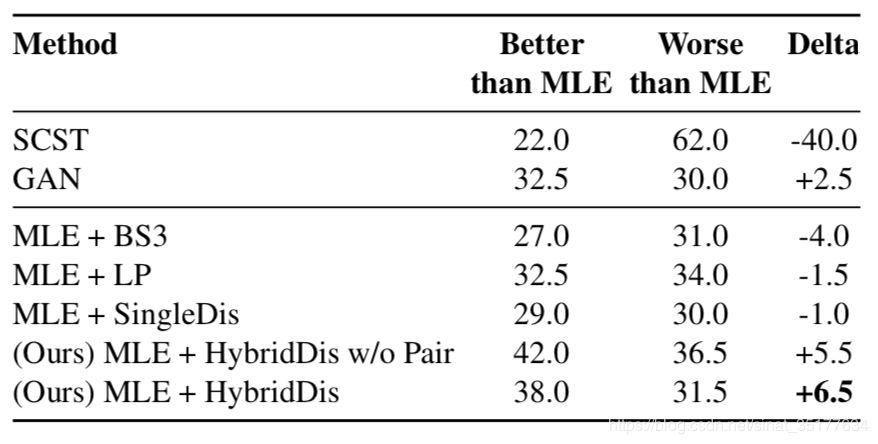
在人工评价上结果较好,说明该方法生成的结果更符合人的思维和理解。
总之这篇文章给我们提取最优的句子新的思路,使用对抗的方法综合考虑准确、多样和连贯三个方面来选择句子,从整个长视频整体上来描述,而不是针对单一的event来描述。
论文链接:https://arxiv.org/pdf/1812.05634.pdf
-End-
*延伸阅读
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~




