ActivityNet Challenge 2017 冠军方案分享
CVPR 2017 这几天开始在夏威夷火热举行,CVPR’17 上举行的各类challenge在近期也纷纷落下帷幕。在过去的两个多月时间里,我在赵旭老师和@Showthem 寿政学长的指导下,参加了CVPR‘17 上举办的 ActivityNet Large Scale Activity Recognition Challenge 中的 Temporal Action Proposal 和 Temporal Action Localization 两项时序动作检测相关的任务,并获得了这两项任务上的冠军。本篇文章主要对ActivityNet Challenge以及我们今年所采用的方案进行介绍。我们的竞赛报告近期会挂到arXiv上,目前可以在我的个人主页上查看:https://wzmsltw.github.io/ 。
任务介绍
此前我写过 Temporal Action Detection(时序行为检测)介绍一文介绍过 temporal action localization 方向(也可以叫做temporal action detection)。简单来说,temporal action localization是要在视频序列中确定动作发生的时间区间(包括开始时间与结束时间)以及动作的类别。这个问题与二维图像中的目标检测问题有很多相似之处。相关算法的算法内容一般可以分为两个部分:(1) temporal action proposal: 即进行时序动作提名,产生候选的视频时序片段,即相当于Faster-RCNN中的RPN网络的作用;(2) action classification: 即判断候选视频时序片段的动作类别。两个部分结合在一起,即实现了视频中的时序动作检测。
在今年的ActivityNet Challenge中,proposal 被单独作为了一项竞赛内容,因此我今年参与了proposal和localization两项任务。
ActivityNet Challenge 介绍
数据集
ActivityNet 听名字与ImageNet十分相似,是目前视频动作分析方向最大的数据集。 目前的ActivityNet dataset版本为1.3,包括20000个Youtube 视频(训练集包含约10000个视频,验证集和测试集各包含约5000个视频),共计约700小时的视频,平均每个视频上有1.5个动作标注(action instance)。
在ActivityNet Challenge 2016中,有 untrimmed video classification 以及 temporal action localization 两项任务,今年则扩充到了五项任务,其中Kinetics 和ActivityNet Captioning为今年新增的两个数据集。
untrimmed video classification (ActivityNet dataset ),
trimmed video classification (Kinetics dataset),
temporal action proposal (ActivityNet dataset),
temporal action localization (ActivityNet dataset),
dense video captioning (ActivityNet Captioning dataset).
下面对ActivityNet Challenge 17中的localization 以及 proposal两项任务的测评方式进行介绍。
测评方式-Temporal Action Localization
在 时序动作检测问题中,mean Average Precision (mAP) 是最常用的评估指标。此次竞赛计算0.5到0.95, 以0.05为步长的多个IoU阈值下的mAP,称为 Average mAP,作为最终的测评以及排名指标。相较于使用mAP@0.5 作为测评指标,Average mAP 更看重在较严格IoU阈值下的检测精度。
测评方式- Temporal Action Proposal
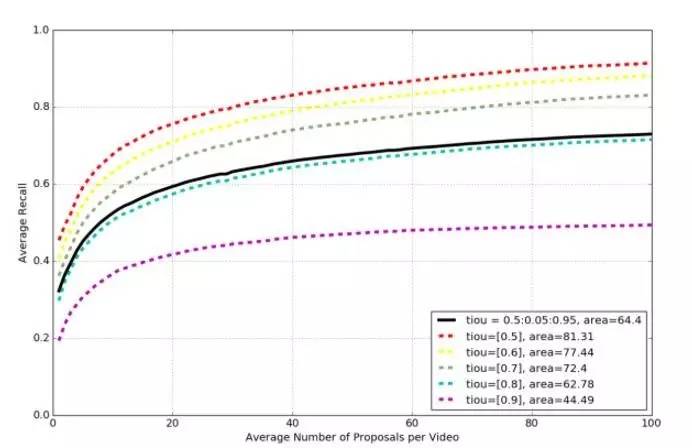
Proposal任务由于无需对时序片段进行分类,所以通常使用average recall (AR) 来进行评估。在此次竞赛中,Average Recall vs. Average Number of Proposals per Video (AR-AN) 曲线下的面积被作为最终的评测指标。举个例子,AN=50 时的AR分数 可以理解为对于每个视频,使用proposal set中分数最高的前50个proposal时,所能达到的召回率。下图为官方提供的baseline方法的AR-AN曲线。
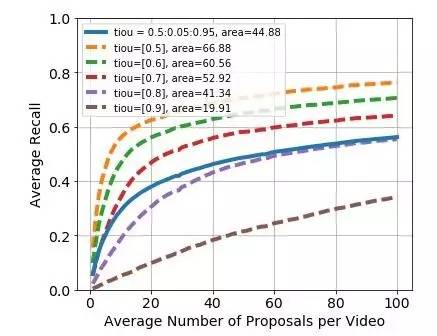
在图中,虚线为不同阈值下的AR-AN曲线,实线为平均的AR-AN曲线,area=44.88即为实线下的面积,也是此任务的最终测评指标。
任务分析
如上所述,temporal action localization任务主要可以分为(1) temporal action proposal和 (2) action classification 两个部分。后者也就是action recognition方向,最近一两年时间,该方向的准确率已经被做到非常高了,我认为已经接近image classification的水平了。在ActivityNet 的untrimmed video classification 任务中,去年最高的Top-1 Accu 大概在88%,今年的第一名则提高到了95%左右。 然而,时序动作检测方向的检测效果较之 目标检测方向 依旧很低,各个数据集中,0.5 IoU阈值下的mAP都还没有超过 50%。基于上述的情况,我们认为问题的关键在于提高temporal action proposal 环节的效果,因此,此次竞赛我们主要专注于temporal action proposal 任务。
方案介绍
此次竞赛我们主要对我们此前投稿在ACM Multimedia的 SSAD [1] 模型 ( Single Shot Temporal Action Detection 论文介绍 )进行了改进。具体的方法介绍可以见竞赛算法报告(链接见开头)。算法的整体框架如下图所示。下面分别对各个部分进行简要的介绍。
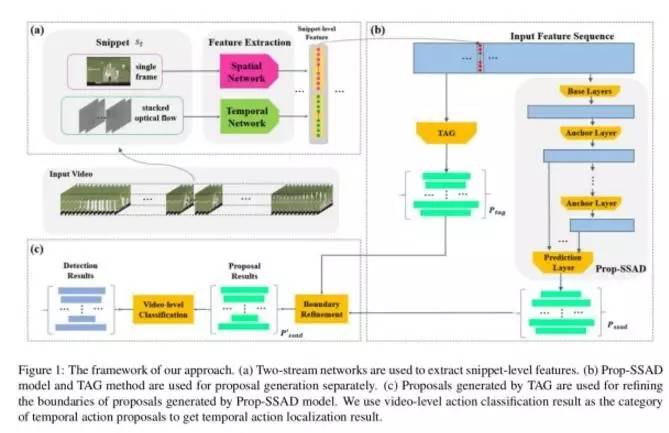
特征提取
在特征提取阶段,我们主要将视频切分成16帧不重叠的单元,然后采用 two-stream network 提取特征。对于spatial network, 我们使用每个单元的中心帧提取特征;对于temporal network,我们则使用每个单元的中心6帧图像计算得到的光流图像提取特征。之后将两部分特征拼合即得到了最终的特征。此处之所以如此稀疏地提取特征,主要是因为ActivityNet数据集太大了,即便如此稀疏依旧花 了我十几天来提取特征(单块1080).
proposal 生成与修正
在该阶段,我们对SSAD模型进行了改进,改进的细节可见算法报告,改进后的模型称为Prop-SSAD。使用Prop-SSAD模型,对每个视频我们可以生成一个proposal 集合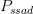
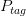
边界修正的规则也比较简单,对于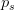
因此,经过proposal 生成 和边界修正两个步骤,我们就可以获得一个video上的 时序动作提名集合。该结果即为此次竞赛Temporal Action Proposal 任务的提交结果
temporal action localization
在获得了proposal后,我们还需要对其进行分类从而得到最终的localization结果。由于ActivityNet上大部分视频中只有一类动作,因此我们直接使用了video-level的分类结果作为对应视频所有proposal的类别。
实验结果
temporal action proposal
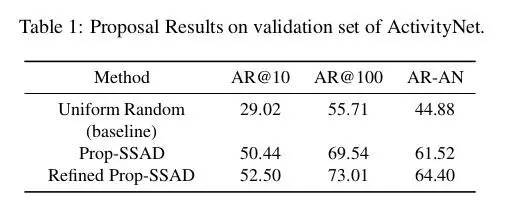
对于该任务,由于在测试集上只能看到最终的AR-AN面积指标,所以实验部分我们给出的是验证集上的结果。下表中是proposal 任务的基线方法,Prop-SSAD方法和 修正的Prop-SSAD方法的性能,可以看出边界的修正对于Proposal的召回率有进一步的提高效果。
对于修正的Prop-SSAD方法,使用官方提供的测试代码,我们还可以得到AR-AN曲线,如下图所示。
temporal action localization
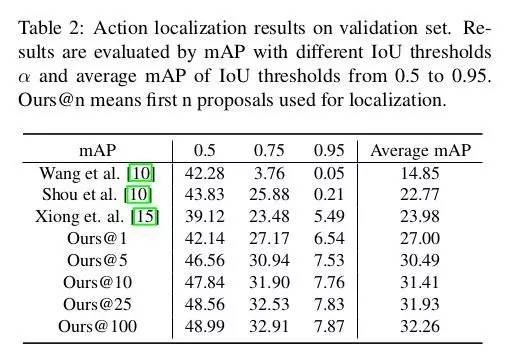
如下表所示是我们的temporal action localization方法在 验证集上的效果。其中Ours@n 代表每个视频使用proposal 集合中的前n个proposal。从表中可以看出,proposal 集合中分数最靠前的一小部分proposal 贡献了大部分的localization mAP。
如下表所示是我们的方法在测试集上的效果,对照方法为此前该数据集上论文的效果,不包括此次竞赛的方法。可以看出,我们的方法比起此前的state-of-the-art方法提高了大约5%的mAP。

总结
基于上述的讨论与实验结果,我们主要有以下几点收获:
proposal的质量对后续localization的效果有很大的影响, 目前改进temporal action localization的重点在于提高proposal的质量
proposal 中最靠前的一小部分proposal 贡献大部分的localization mAP
时序卷积以及 anchor 机制在时序动作提名与检测任务中能起到很好的效果
在后续的工作中我们会对此次的方案进行进一步的改进与优化,希望大家能关注我们的工作~
参考文献
[1] T. Lin, X. Zhao, and Z. Shou. Single shot temporal action detection. 25nd ACM international conference on Multimedia, 2017.
[2] Y. Xiong, Y. Zhao, L. Wang, D. Lin, and X. Tang. A pursuit of temporal accuracy in general activity detection. arXiv preprint arXiv:1703.02716, 2017.
本文经授权转自知乎专栏CV论文笔记及其它,点击阅读原文查看全文。
**线上分享推荐**
7月27日(本周四晚8点到9点半)我们邀请了发表了ICCV2017论文《Unlabeled Samples Generatedby GAN Improve the Person Re-identification Baseline in vitro》的郑哲东为我们分享他在行人再识别的技术干货,欢迎大家参加。关注本公众号回复“19”即可获取直播链接。如有想加入极市专业CV开发者微信群,请填写申请表(链接:http://cn.mikecrm.com/wcotd9)申请入群。





