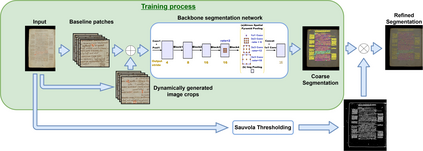
Layout analysis is a task of uttermost importance in ancient handwritten document analysis and represents a fundamental step toward the simplification of subsequent tasks such as optical character recognition and automatic transcription. However, many of the approaches adopted to solve this problem rely on a fully supervised learning paradigm. While these systems achieve very good performance on this task, the drawback is that pixel-precise text labeling of the entire training set is a very time-consuming process, which makes this type of information rarely available in a real-world scenario. In the present paper, we address this problem by proposing an efficient few-shot learning framework that achieves performances comparable to current state-of-the-art fully supervised methods on the publicly available DIVA-HisDB dataset.
翻译:在古老的手写文件分析中,布局分析是一项极为重要的任务,是朝着简化随后的任务,例如光学字符识别和自动抄录等任务迈出的重要一步。然而,为解决这一问题而采取的许多方法都依赖于一个完全受监督的学习模式。虽然这些系统在这项任务上取得了非常良好的表现,但缺点是整个培训组的像素拼图标记是一个非常耗时的过程,这使得这种信息很少在现实世界的情景下提供。在本文件中,我们提出一个高效的、能取得与公开提供的DIVA-HisDB数据集中目前最先进的全面监督方法相类似的性能的微小学习框架来解决这个问题。