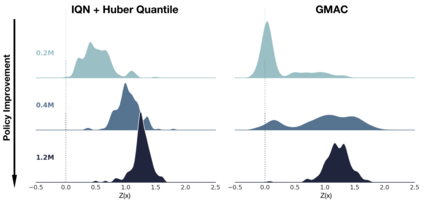
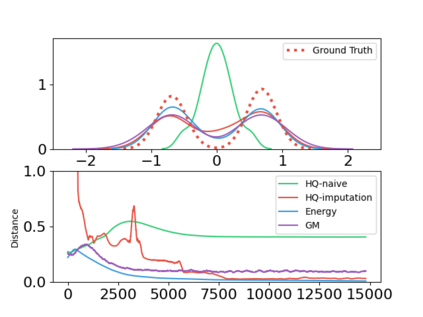
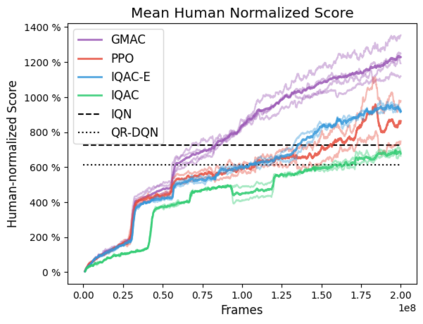
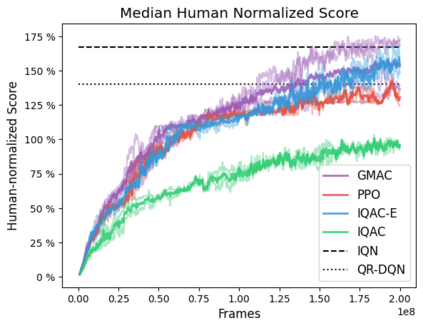
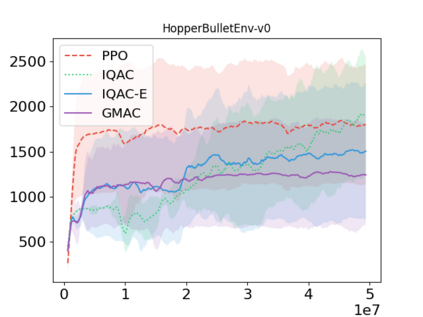
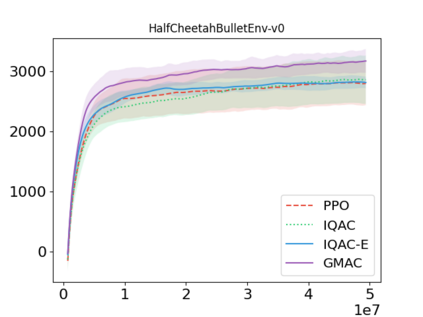
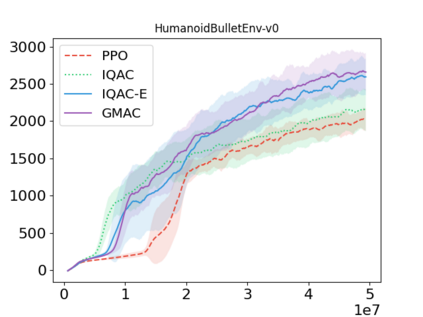
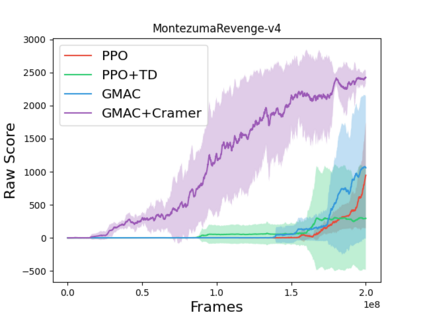
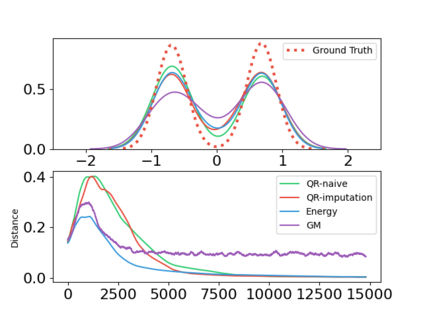
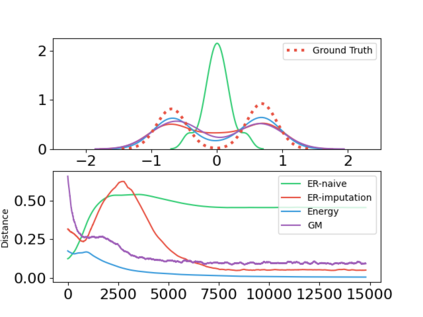
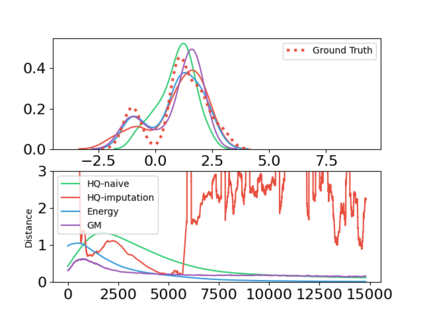
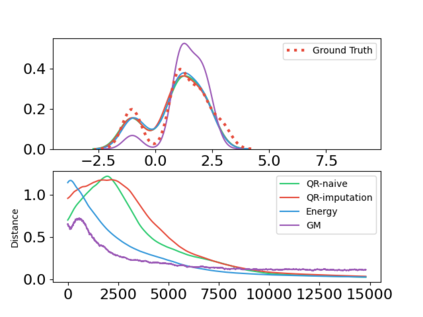
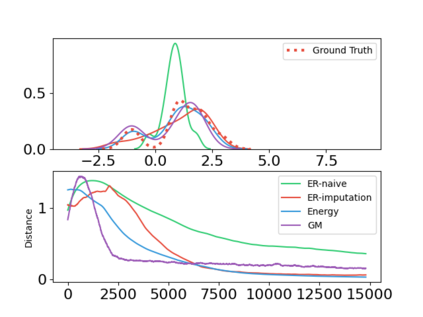
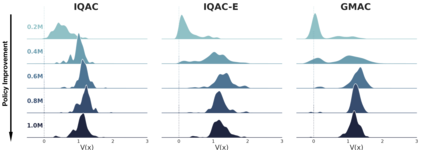
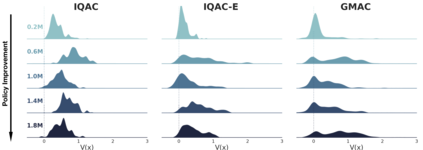
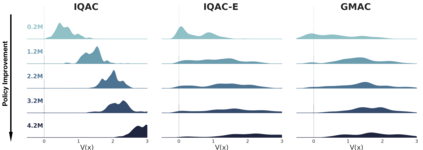
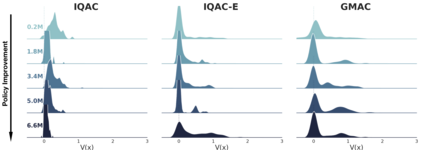
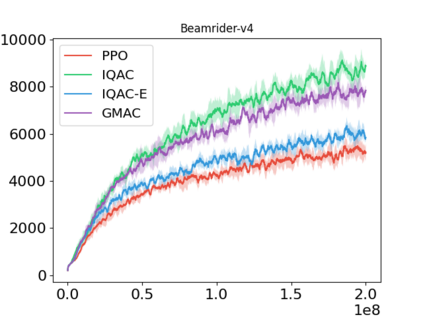
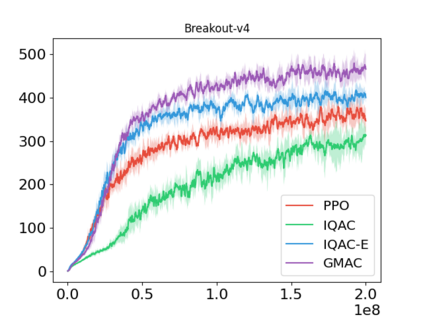
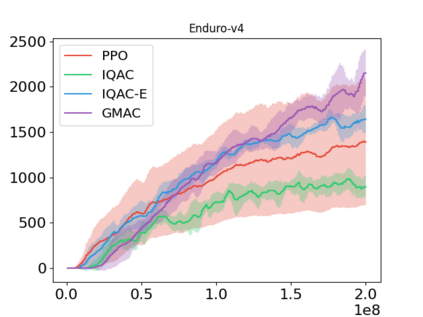
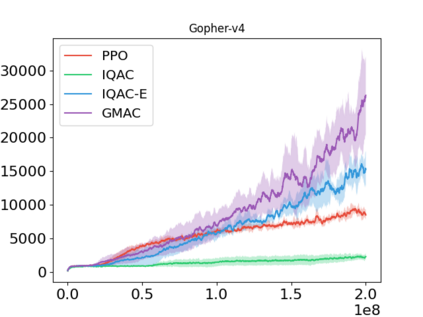
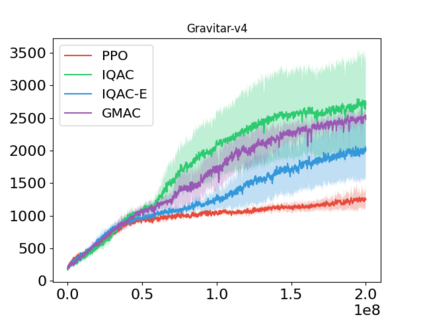
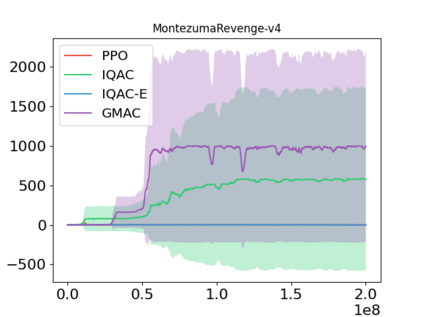
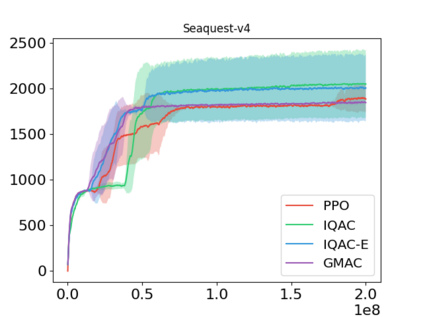
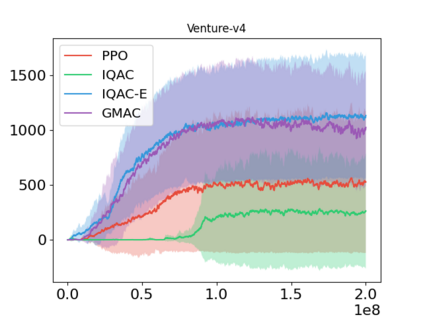
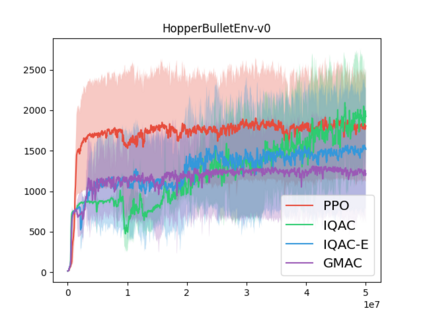
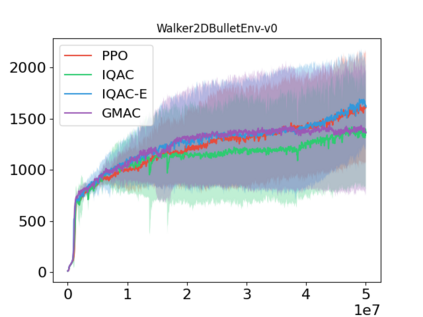
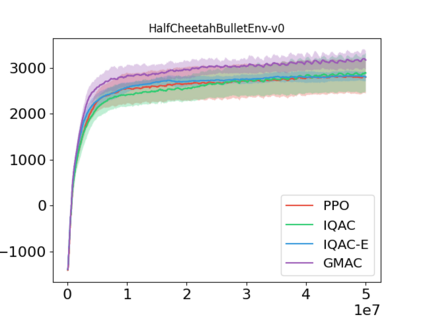
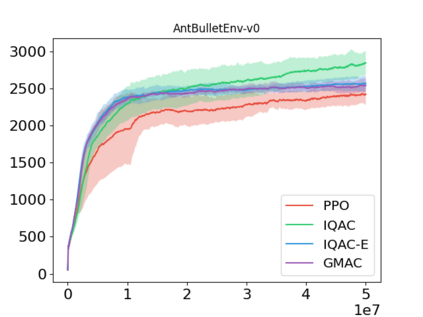
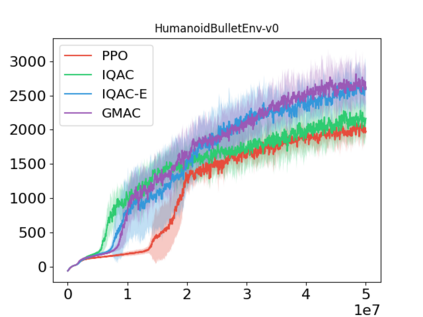
In this paper, we devise a distributional framework on actor-critic as a solution to distributional instability, action type restriction, and conflation between samples and statistics. We propose a new method that minimizes the Cram\'er distance with the multi-step Bellman target distribution generated from a novel Sample-Replacement algorithm denoted SR($\lambda$), which learns the correct value distribution under multiple Bellman operations. Parameterizing a value distribution with Gaussian Mixture Model further improves the efficiency and the performance of the method, which we name GMAC. We empirically show that GMAC captures the correct representation of value distributions and improves the performance of a conventional actor-critic method with low computational cost, in both discrete and continuous action spaces using Arcade Learning Environment (ALE) and PyBullet environment.
翻译:在本文中,我们设计了一个关于行为者-批评的分布框架,作为分配不稳定、行动类型限制以及将样本和统计数据混为一谈的一种解决办法。我们提出了一种新的方法,以最大限度地减少从一种新型的样样替换算法中生成的多步Bellman目标分布的Cram\'er距离,代之以SR($\lambda$),该算法在多个Bellman操作中学习正确的价值分布。与Gausian Mixture模型的值分配参数进一步提高了该方法(我们称之为GMAC)的效率和性能。我们从经验上表明,GMAC在使用Arcade学习环境(ALE)和PyBullet环境的离散和连续行动空间中,都掌握了价值分配的正确代表性,并改进了低计算成本的常规行为者-批评方法的性能。