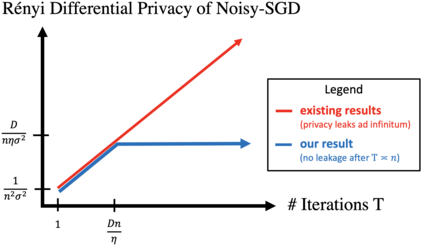
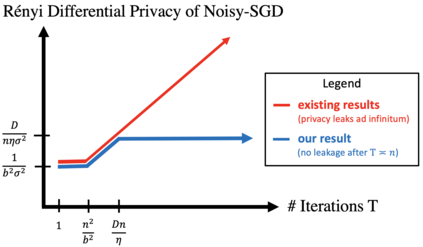
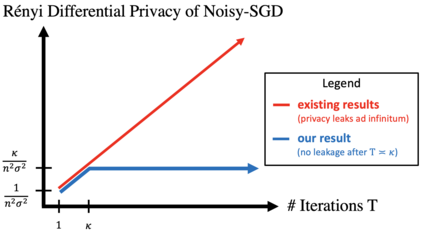
A central issue in machine learning is how to train models on sensitive user data. Industry has widely adopted a simple algorithm: Stochastic Gradient Descent with noise (a.k.a. Stochastic Gradient Langevin Dynamics). However, foundational theoretical questions about this algorithm's privacy loss remain open -- even in the seemingly simple setting of smooth convex losses over a bounded domain. Our main result resolves these questions: for a large range of parameters, we characterize the differential privacy up to a constant factor. This result reveals that all previous analyses for this setting have the wrong qualitative behavior. Specifically, while previous privacy analyses increase ad infinitum in the number of iterations, we show that after a small burn-in period, running SGD longer leaks no further privacy. Our analysis departs from previous approaches based on fast mixing, instead using techniques based on optimal transport (namely, Privacy Amplification by Iteration) and the Sampled Gaussian Mechanism (namely, Privacy Amplification by Sampling). Our techniques readily extend to other settings, e.g., strongly convex losses, non-uniform stepsizes, arbitrary batch sizes, and random or cyclic choice of batches.
翻译:机器学习的中心问题是如何培训敏感用户数据模型。 产业界已经广泛采用了简单的算法: 有噪音的Stochatistic 梯度源(a.k.a.tochatic Gratic Gradient Langevin Dynamics) 。 但是,关于算法的隐私损失的基础理论问题仍然开放 -- -- 甚至在一个封闭域上光滑的 convex 损失的表面简单设置中也是如此。 我们的主要结果解决了这些问题: 对于一系列广泛的参数, 我们将差异隐私定性特性描述为一个不变因素。 这个结果显示, 之前对这个设置的所有分析都有错误的质量行为。 具体地说, 尽管以前的隐私分析增加了迭代数的无限值, 我们显示, 经过一个小的燃烧期后, SGD 运行的泄漏时间更长。 我们的分析偏离了以前基于快速混合的方法, 而不是使用基于最佳运输的技术( 透镜) 和抽样高斯机制( 缩写的隐私缩写 ) 。 我们的技术很容易扩展到其他环境, 例如, 强烈的等等等拼写损失的拼写、 任意级步骤或任意级步骤。</s>