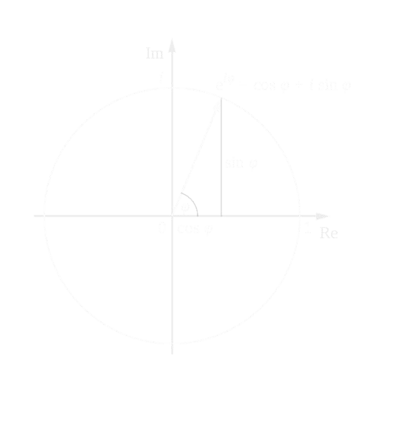
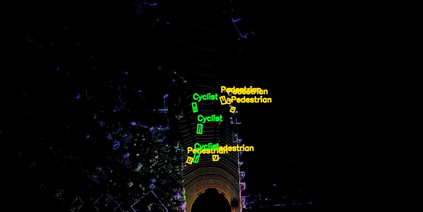
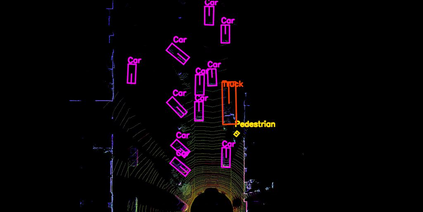
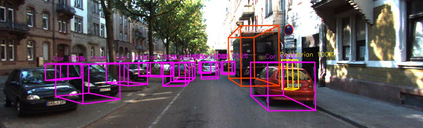
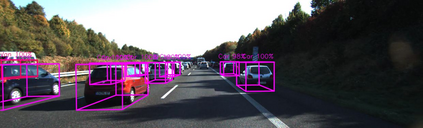
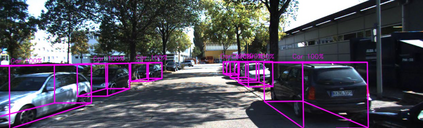
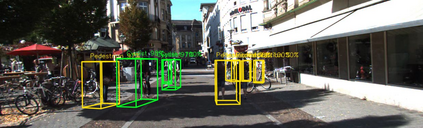
Lidar based 3D object detection is inevitable for autonomous driving, because it directly links to environmental understanding and therefore builds the base for prediction and motion planning. The capacity of inferencing highly sparse 3D data in real-time is an ill-posed problem for lots of other application areas besides automated vehicles, e.g. augmented reality, personal robotics or industrial automation. We introduce Complex-YOLO, a state of the art real-time 3D object detection network on point clouds only. In this work, we describe a network that expands YOLOv2, a fast 2D standard object detector for RGB images, by a specific complex regression strategy to estimate multi-class 3D boxes in Cartesian space. Thus, we propose a specific Euler-Region-Proposal Network (E-RPN) to estimate the pose of the object by adding an imaginary and a real fraction to the regression network. This ends up in a closed complex space and avoids singularities, which occur by single angle estimations. The E-RPN supports to generalize well during training. Our experiments on the KITTI benchmark suite show that we outperform current leading methods for 3D object detection specifically in terms of efficiency. We achieve state of the art results for cars, pedestrians and cyclists by being more than five times faster than the fastest competitor. Further, our model is capable of estimating all eight KITTI-classes, including Vans, Trucks or sitting pedestrians simultaneously with high accuracy.
翻译:以 3D 为基础的利达尔 3D 对象探测是自动驾驶所不可避免的, 因为它直接与环境理解相关, 从而建立了预测和运动规划的基础。 实时对高度稀少的 3D 数据进行推断的能力对于除自动化车辆以外的许多其他应用领域来说是一个不恰当的问题, 例如, 增强现实、 个人机器人或工业自动化。 我们引入了 Complex- YOLO, 这是一种仅对点云进行实时 3D 物体探测的先进技术。 我们在此工作中描述了一个扩大 YOLOv2 的网络, 一个用于RGB 图像的快速 2D 标准物体探测器, 这是一种特殊的复杂回归战略, 以估计Cartesian 空间的多级 3D 框。 因此, 我们提出一个具体的 Euler- Region-Proposal 网络(E- RPN), 来评估该物体的外形形形形形形形形形像, 是一个封闭的复杂空间, 避免模型的奇特性, 。 E- RPN 支持在训练期间实现通用 。 我们在 KITTI 图像 的精准性 基准 的实验, 3 级基准套中, 显示我们比当前 速度 高 的 速度 的 的 的,, 直径 直径, 直径 直径, 直径 直径 直径 直径 直径 直径 直径 直 直 直径 直径 直径 直 直 直 直 直 直 直 直 直 直 直 。