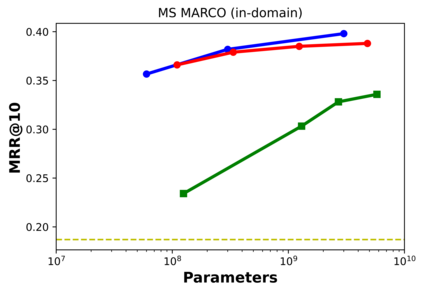
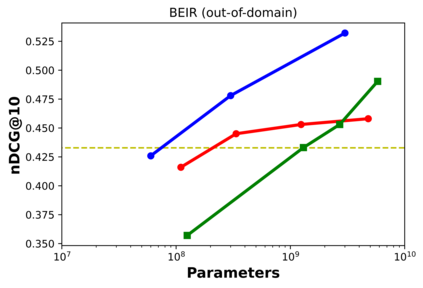
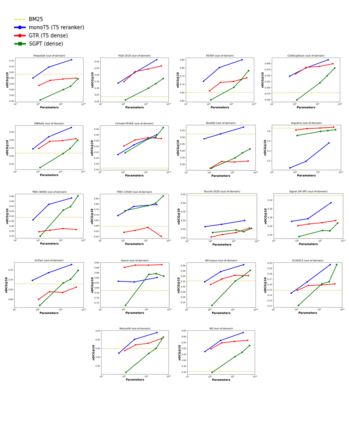
Bi-encoders and cross-encoders are widely used in many state-of-the-art retrieval pipelines. In this work we study the generalization ability of these two types of architectures on a wide range of parameter count on both in-domain and out-of-domain scenarios. We find that the number of parameters and early query-document interactions of cross-encoders play a significant role in the generalization ability of retrieval models. Our experiments show that increasing model size results in marginal gains on in-domain test sets, but much larger gains in new domains never seen during fine-tuning. Furthermore, we show that cross-encoders largely outperform bi-encoders of similar size in several tasks. In the BEIR benchmark, our largest cross-encoder surpasses a state-of-the-art bi-encoder by more than 4 average points. Finally, we show that using bi-encoders as first-stage retrievers provides no gains in comparison to a simpler retriever such as BM25 on out-of-domain tasks. The code is available at https://github.com/guilhermemr04/scaling-zero-shot-retrieval.git
翻译:在这项工作中,我们研究了这两类建筑在一系列参数上的普及能力,这两类建筑的普及能力,这些参数既取决于内部和外部的假设情况。我们发现,跨编码者的参数和早期查询文档互动数量在检索模型的普及能力中起着重要作用。我们的实验表明,日益扩大的模型规模导致在现场测试组中取得边际收益,但在微调期间从未看到过的新领域获得的更大收益。此外,我们还表明,跨编码器在多项任务中基本上优于类似规模的双编码器。在BEIR基准中,我们最大的交叉编码超过一个最先进的双编码器,平均超过4个点。最后,我们表明,使用双编码器作为第一阶段检索器,与像BM25这样的较简单的检索器相比,在外部任务上没有取得任何收益。该代码可在 https://githrub.comm/guilling https://gistrireireub.