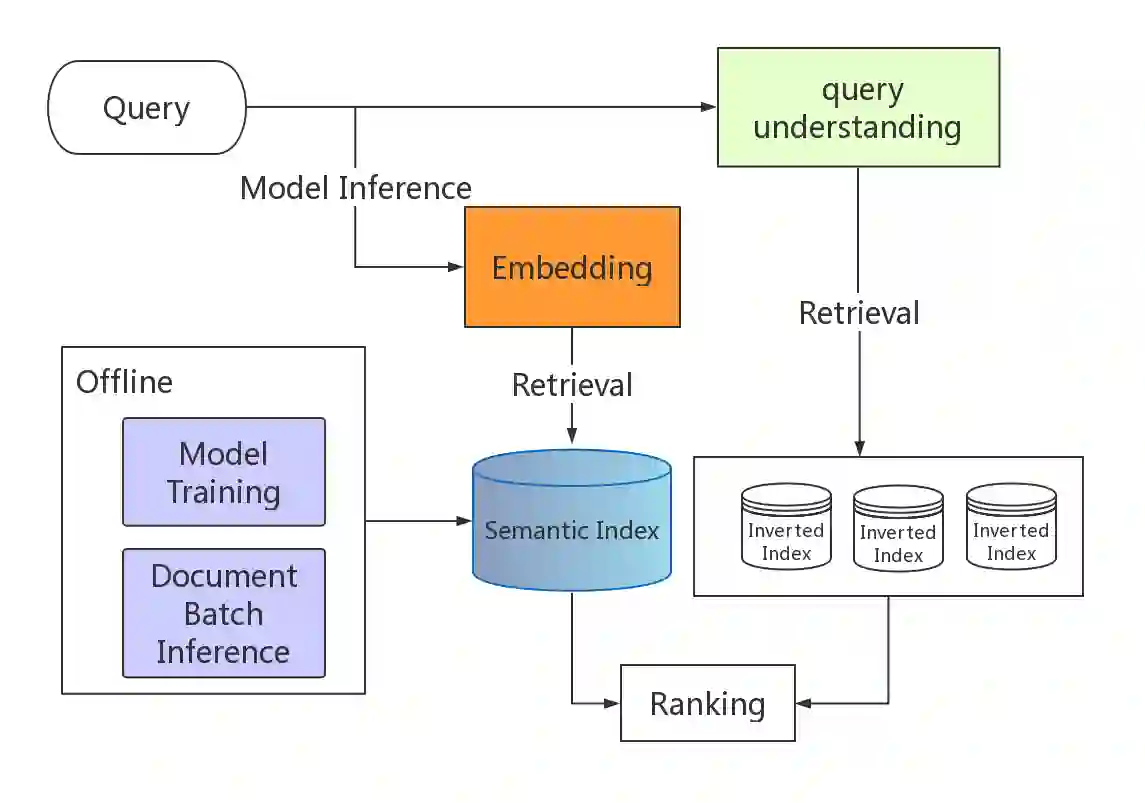
Search engine has become a fundamental component in various web and mobile applications. Retrieving relevant documents from the massive datasets is challenging for a search engine system, especially when faced with verbose or tail queries. In this paper, we explore a vector space search framework for document retrieval. Specifically, we trained a deep semantic matching model so that each query and document can be encoded as a low dimensional embedding. Our model was trained based on BERT architecture. We deployed a fast k-nearest-neighbor index service for online serving. Both offline and online metrics demonstrate that our method improved retrieval performance and search quality considerably, particularly for tail
翻译:搜索引擎已成为各种网络和移动应用程序的基本组成部分。从大型数据集中获取相关文件对搜索引擎系统来说是一项挑战性的工作,特别是当遇到verbose或尾部查询时。在本文件中,我们探索了一个用于文件检索的矢量空间搜索框架。具体地说,我们训练了一个深层次的语义匹配模型,以便每个查询和文件都能够以低维嵌入方式编码。我们的模型是建立在 BERT 结构基础上的培训。我们为在线服务安装了一个快速的 k- nearest- nearbearbor 索引服务。 离线和在线测量都表明,我们的方法大大改进了检索性能和搜索质量,特别是对尾部而言。