
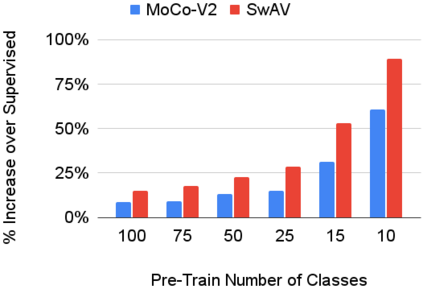
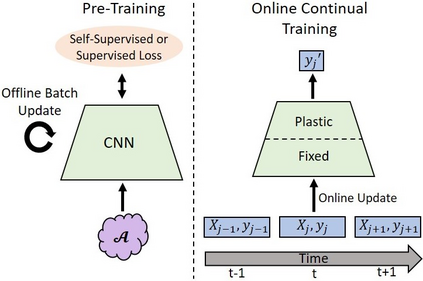
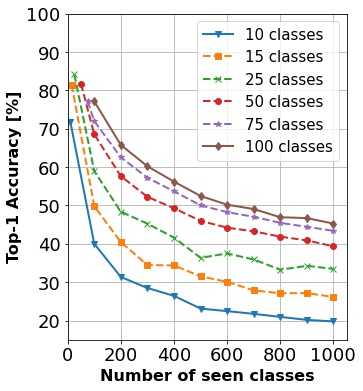
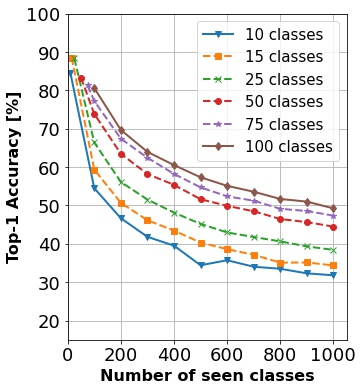
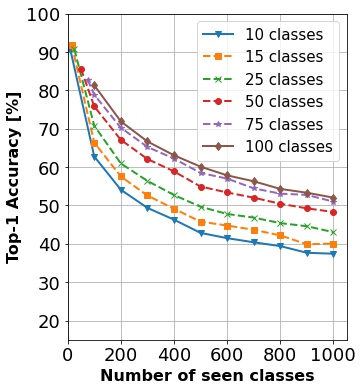
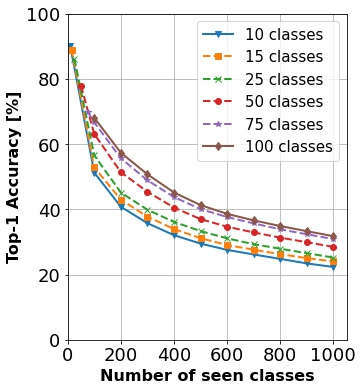
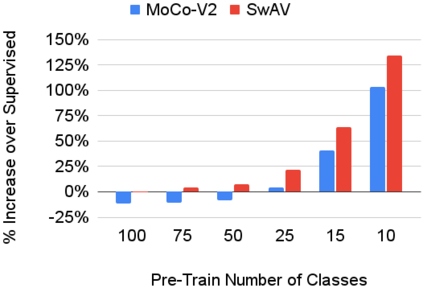
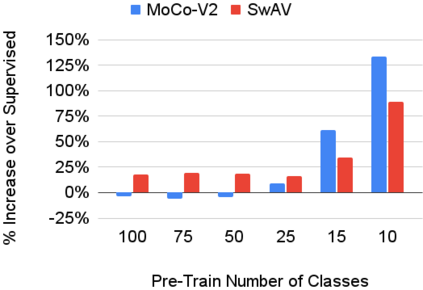
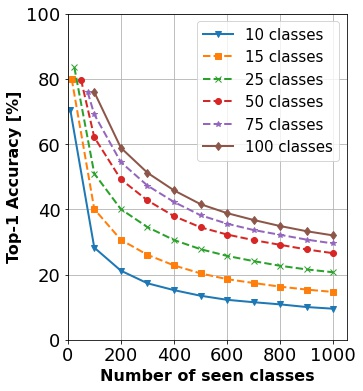
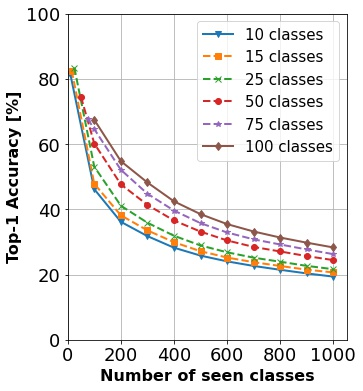
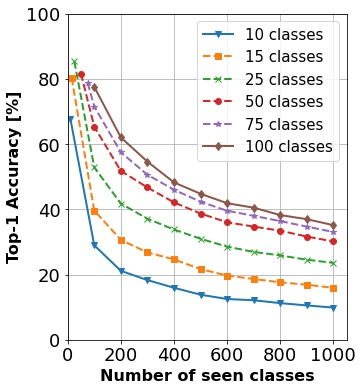
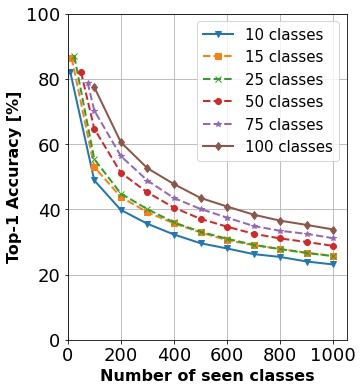
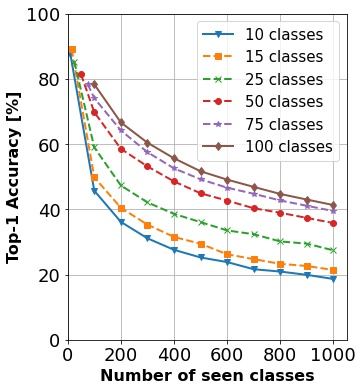
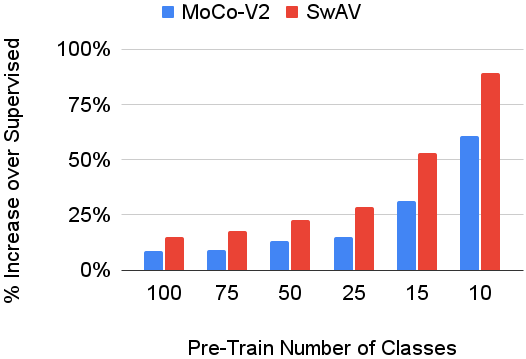
In continual learning, a system must incrementally learn from a non-stationary data stream without catastrophic forgetting. Recently, multiple methods have been devised for incrementally learning classes on large-scale image classification tasks, such as ImageNet. State-of-the-art continual learning methods use an initial supervised pre-training phase, in which the first 10% - 50% of the classes in a dataset are used to learn representations in an offline manner before continual learning of new classes begins. We hypothesize that self-supervised pre-training could yield features that generalize better than supervised learning, especially when the number of samples used for pre-training is small. We test this hypothesis using the self-supervised MoCo-V2 and SwAV algorithms. On ImageNet, we find that both outperform supervised pre-training considerably for online continual learning, and the gains are larger when fewer samples are available. Our findings are consistent across three continual learning algorithms. Our best system achieves a 14.95% relative increase in top-1 accuracy on class incremental ImageNet over the prior state of the art for online continual learning.
翻译:在持续学习中,一个系统必须从非静止的数据流中逐步学习,而不会忘记灾难性的遗忘。最近,已经设计了多种方法,用于大规模图像分类任务(如图像网络)的渐进学习班,例如图像网络。最先进的持续学习方法使用初步监督的训练前阶段,在连续学习新课程之前,将数据集中前10%-50%的班级用于以离线方式学习演示。我们假设,自我监督的训练前阶段可以产生比监督的学习更好的特征,特别是在培训前使用的样本数量很小的时候。我们使用自我监督的MOCo-V2和SWAVAV算法来测试这一假设。在图像网络中,我们发现,在网上持续学习的预培训中,两者都大大超过受监督的预培训,而在有较少的样本时,收益更大。我们在三个持续学习算法中得出了一致的研究结果。我们的最佳系统在班级级递增图像网络上,在前一年级递增的精度上实现了14.95%的相对增长率,高于前一等艺术在网上不断学习的状态。
相关内容

Source: Apple - iOS 8


