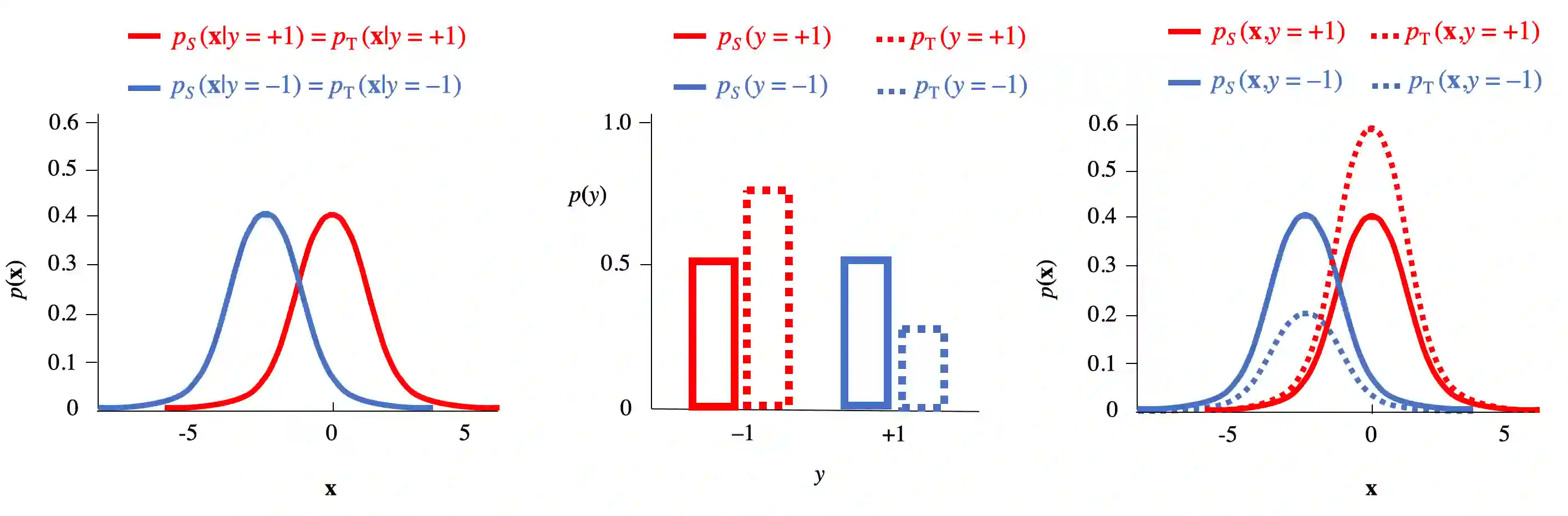
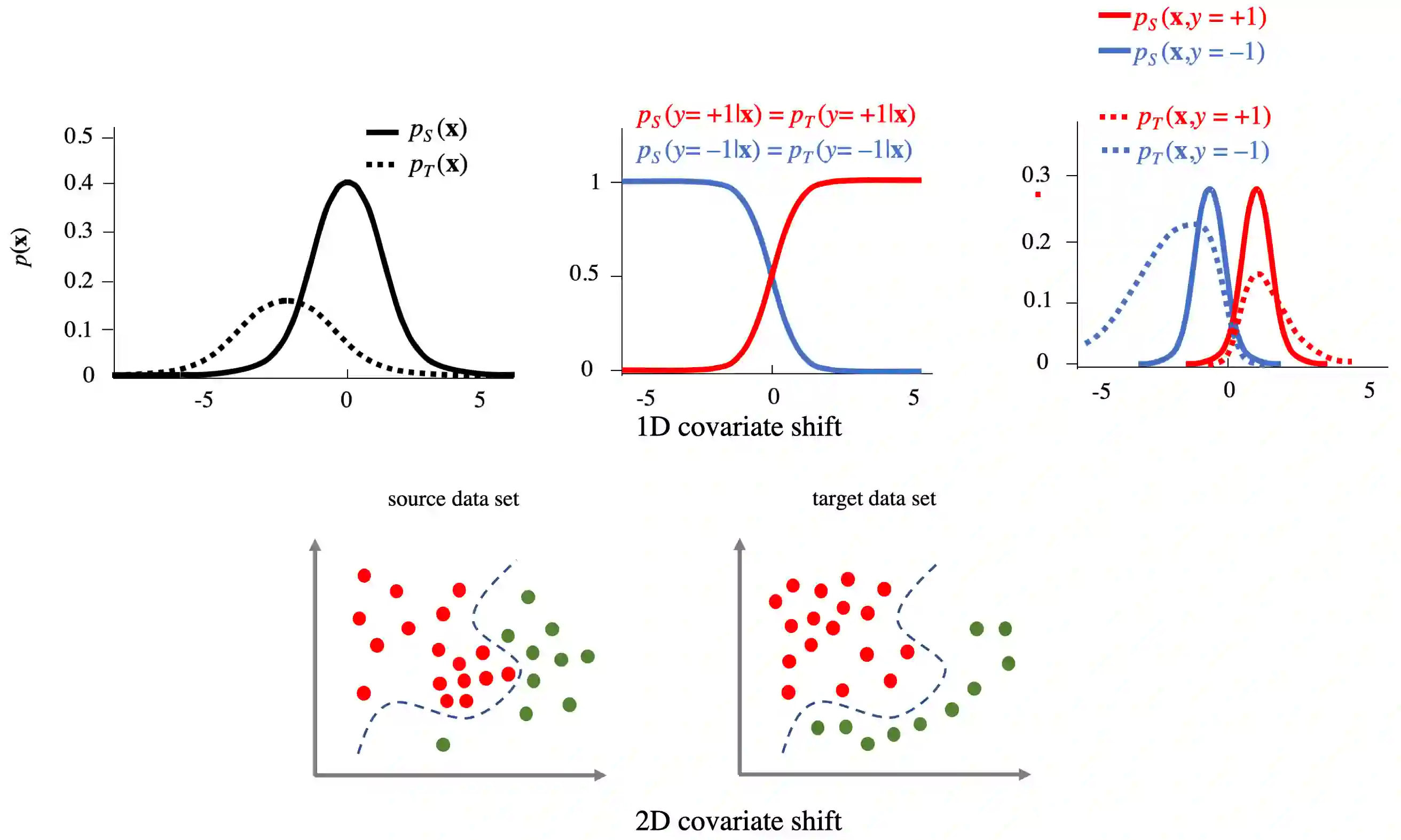
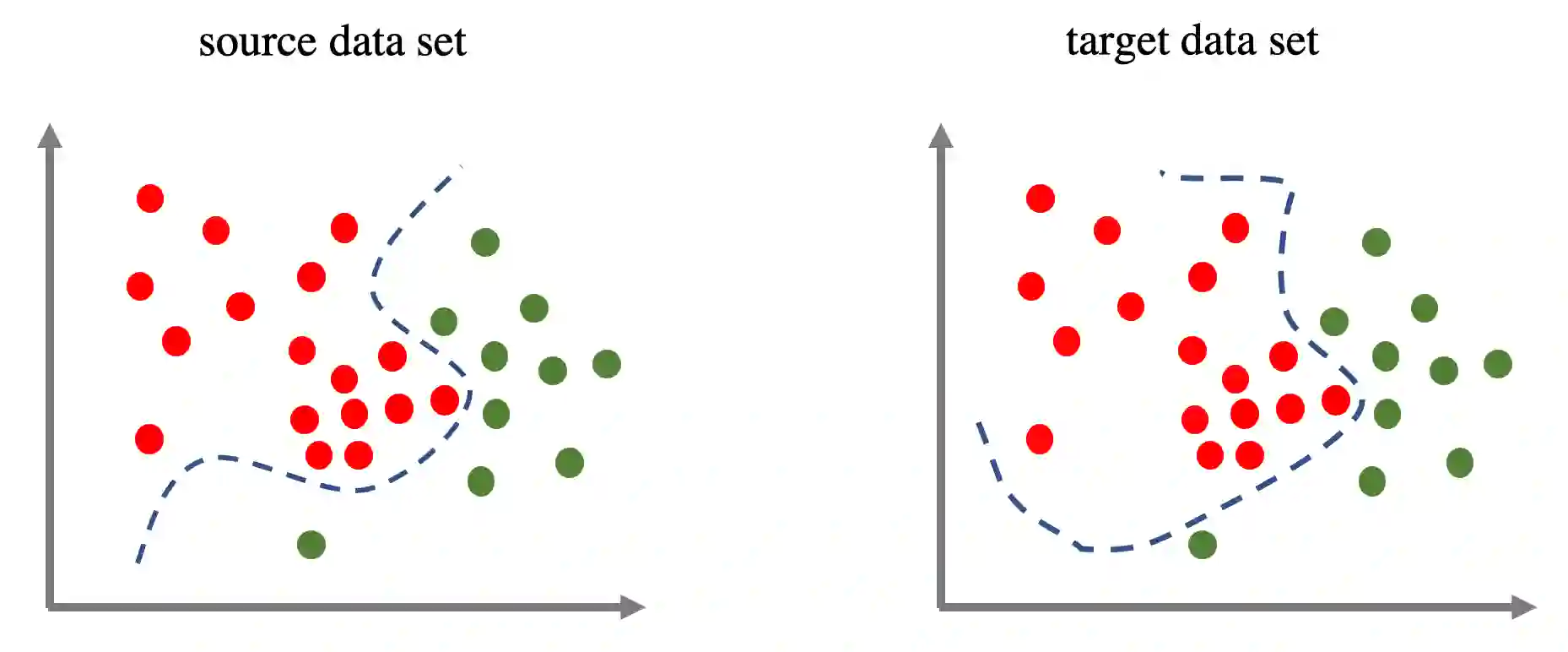
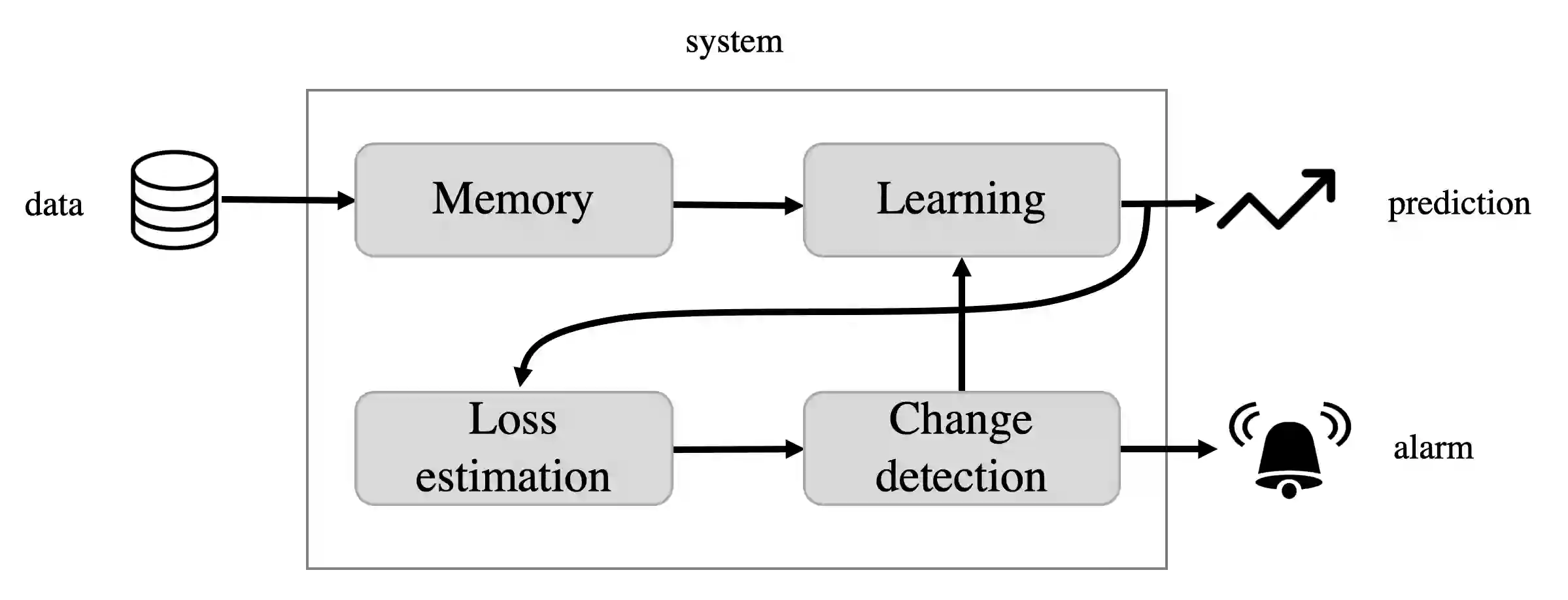
Standard supervised machine learning assumes that the distribution of the source samples used to train an algorithm is the same as the one of the target samples on which it is supposed to make predictions. However, as any data scientist will confirm, this is hardly ever the case in practice. The set of statistical and numerical methods that deal with such situations is known as domain adaptation, a field with a long and rich history. The myriad of methods available and the unfortunate lack of a clear and universally accepted terminology can however make the topic rather daunting for the newcomer. Therefore, rather than aiming at completeness, which leads to exhibiting a tedious catalog of methods, this pedagogical review aims at a coherent presentation of four important special cases: (1) prior shift, a situation in which training samples were selected according to their labels without any knowledge of their actual distribution in the target, (2) covariate shift which deals with a situation where training examples were picked according to their features but with some selection bias, (3) concept shift where the dependence of the labels on the features defers between the source and the target, and last but not least (4) subspace mapping which deals with a situation where features in the target have been subjected to an unknown distortion with respect to the source features. In each case we first build an intuition, next we provide the appropriate mathematical framework and eventually we describe a practical application.
翻译:标准监督的机器学习假设,用于培训算法的源样本的分布与用来预测算法的目标样本的分布相同,然而,正如任何数据科学家都能够证实的那样,实际情况并非如此。处理这种情况的一套统计和数字方法被称为领域适应,这是一个具有长期和丰富历史的领域。现有的各种方法和不幸缺乏一个明确和普遍接受的术语,但使新来者对该专题感到困难。因此,这种教学审查的目的不是要达到完整性,而是要展示一个令人厌烦的方法目录,而是要对四个重要的特殊案例进行连贯的介绍:(1) 先前的轮班,即根据标签选择培训样品的情况,而没有了解这些样品在目标中的实际分布情况;(2) 交替式变化,涉及根据培训范例的特征挑选,但有一些选择偏差;(3) 概念转变,即标签对特征的依赖在来源和目标之间,以及最后但并非最不重要的次空间绘图,涉及目标特征在下一个目标中的位置,我们最终要有一个未知的精确度,我们每个数据源。