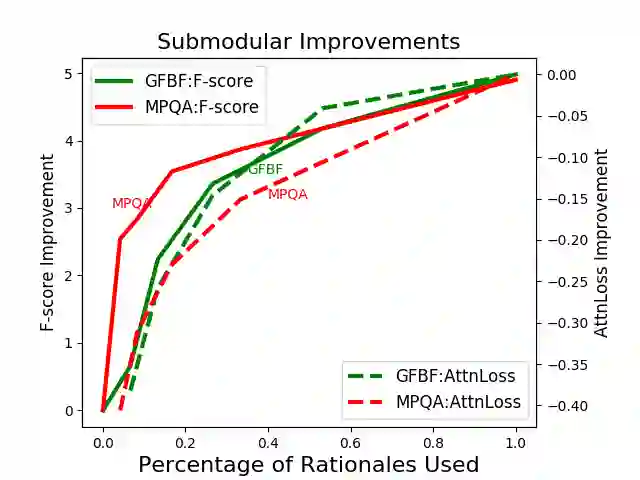
While the general task of textual sentiment classification has been widely studied, much less research looks specifically at sentiment between a specified source and target. To tackle this problem, we experimented with a state-of-the-art relation extraction model. Surprisingly, we found that despite reasonable performance, the model's attention was often systematically misaligned with the words that contribute to sentiment. Thus, we directly trained the model's attention with human rationales and improved our model performance by a robust 4~8 points on all tasks we defined on our data sets. We also present a rigorous analysis of the model's attention, both trained and untrained, using novel and intuitive metrics. Our results show that untrained attention does not provide faithful explanations; however, trained attention with concisely annotated human rationales not only increases performance, but also brings faithful explanations. Encouragingly, a small amount of annotated human rationales suffice to correct the attention in our task.
翻译:虽然对文字情绪分类的一般任务进行了广泛研究,但研究更没有具体地审视特定来源和目标之间的情绪。为了解决这一问题,我们试验了一种最先进的提取关系模型。令人惊讶的是,我们发现,尽管表现合理,但模型的注意力往往系统地与有助于情感的词语不相符。因此,我们直接用人的理由来训练模型的注意力,并用我们确定的所有数据组任务4~8点来改进我们的模型性能。我们还用新颖和直观的衡量尺度对模型的注意力进行了严格分析,既经过训练,又未经训练。我们的结果显示,未经训练的注意力并不能提供忠实的解释;然而,经过训练的注意力不仅简要地说明人的理由,不仅提高了业绩,而且还带来了忠实的解释。令人鼓舞的是,少量附加说明的人类理由足以纠正我们任务中的注意力。