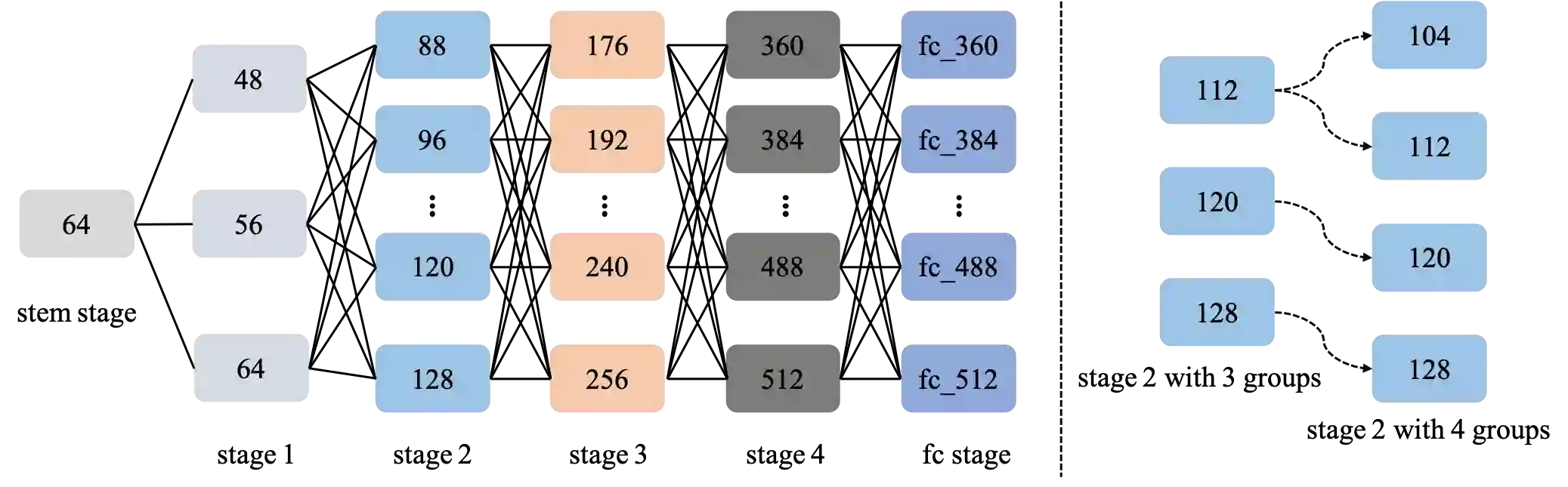
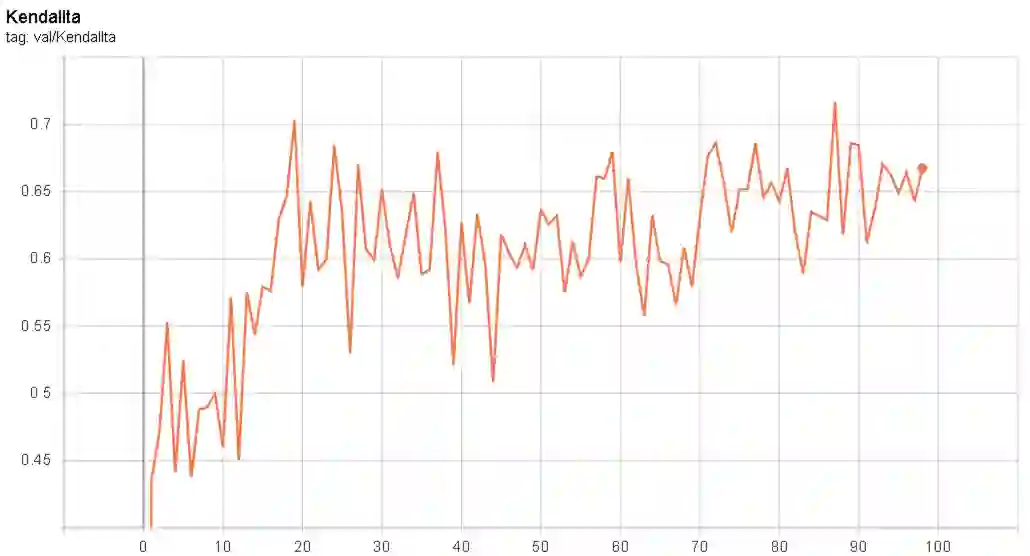
The algorithms of one-shot neural architecture search(NAS) have been widely used to reduce computation consumption. However, because of the interference among the subnets in which weights are shared, the subnets inherited from these super-net trained by those algorithms have poor consistency in precision ranking. To address this problem, we propose a step-by-step training super-net scheme from one-shot NAS to few-shot NAS. In the training scheme, we firstly train super-net in a one-shot way, and then we disentangle the weights of super-net by splitting them into multi-subnets and training them gradually. Finally, our method ranks 4th place in the CVPR2022 3rd Lightweight NAS Challenge Track1. Our code is available at https://github.com/liujiawei2333/CVPR2022-NAS-competition-Track-1-4th-solution.
翻译:单发神经结构搜索(NAS)的算法被广泛用于减少计算消耗。然而,由于共享权重的子网之间的干扰,这些由这些算法所培训的超级网络所继承的子网在精确排序方面缺乏一致性。为解决这一问题,我们建议从一发NAS到几发NAS逐步培训超级网计划。在培训计划中,我们首先以一发方式培训超级网,然后通过将超级网分成多个子网并逐步培训它们来分解超级网的重量。最后,我们的方法在CVPR2022第3次轻度NAS挑战轨道1中排名第四。 我们的代码可在https://githubub.com/liujiawei2333/CVPR2022-NAS-competition-Tracy-1-4Solution上查到。