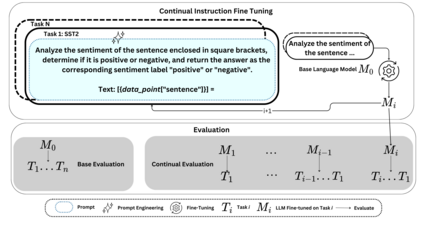
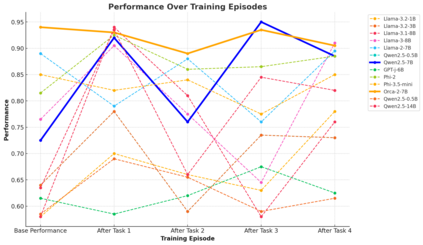
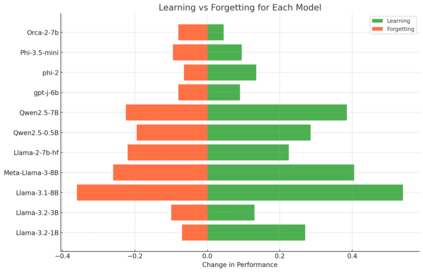
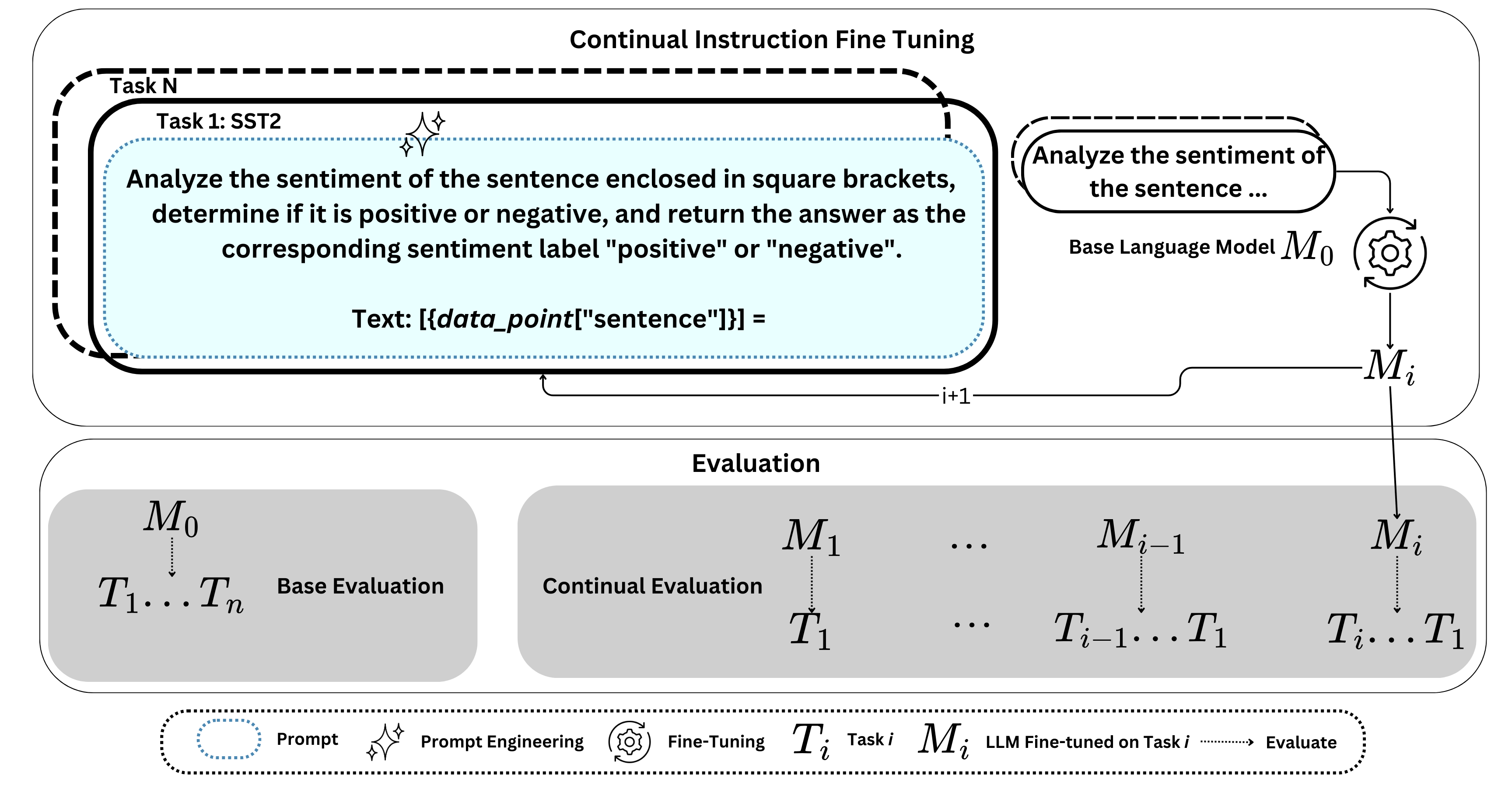
Large Language Models (LLMs) have significantly advanced Natural Language Processing (NLP), particularly in Natural Language Understanding (NLU) tasks. As we progress toward an agentic world where LLM-based agents autonomously handle specialized tasks, it becomes crucial for these models to adapt to new tasks without forgetting previously learned information - a challenge known as catastrophic forgetting. This study evaluates the continual fine-tuning of various open-source LLMs with different parameter sizes (specifically models under 10 billion parameters) on key NLU tasks from the GLUE benchmark, including SST-2, MRPC, CoLA, and MNLI. By employing prompt engineering and task-specific adjustments, we assess and compare the models' abilities to retain prior knowledge while learning new tasks. Our results indicate that models such as Phi-3.5-mini exhibit minimal forgetting while maintaining strong learning capabilities, making them well-suited for continual learning environments. Additionally, models like Orca-2-7b and Qwen2.5-7B demonstrate impressive learning abilities and overall performance after fine-tuning. This work contributes to understanding catastrophic forgetting in LLMs and highlights prompting engineering to optimize model performance for continual learning scenarios.
翻译:暂无翻译