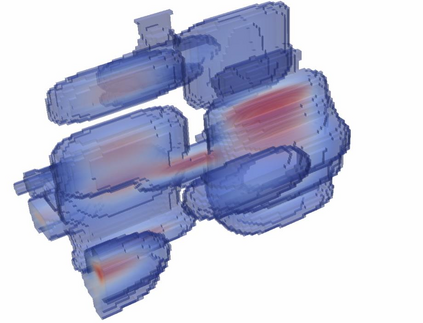
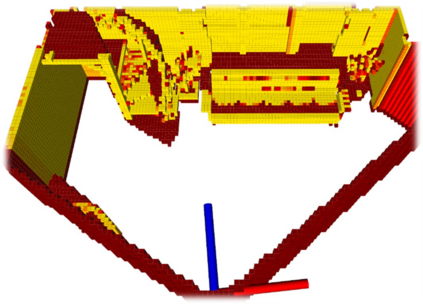
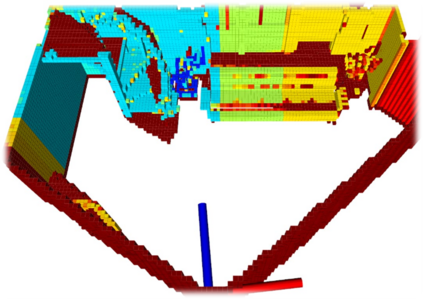
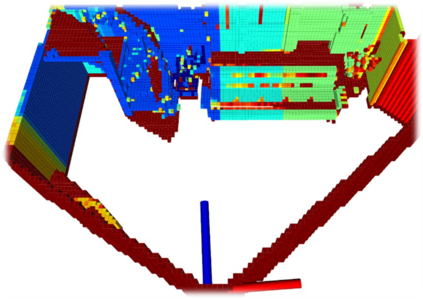
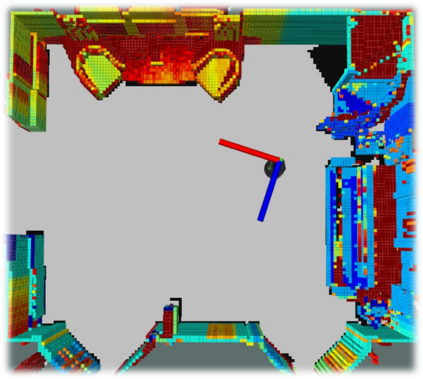
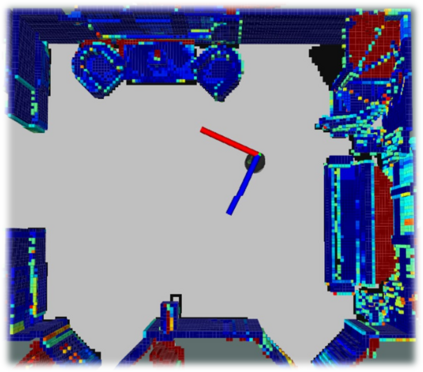
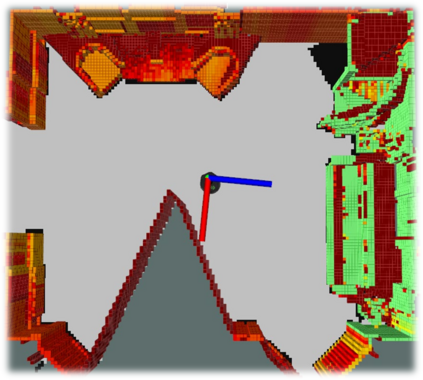
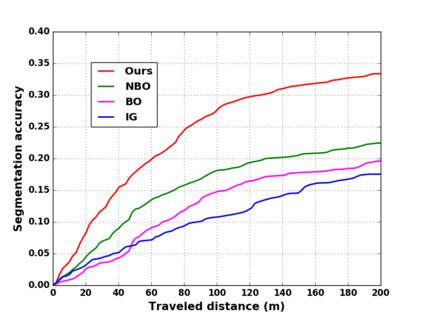
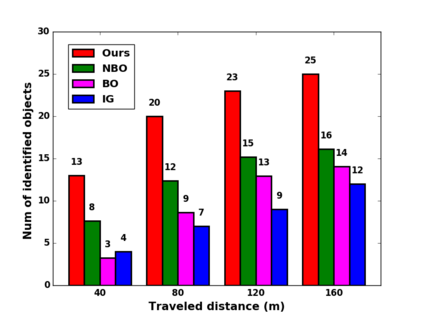
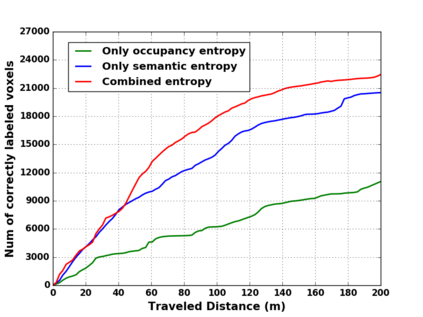
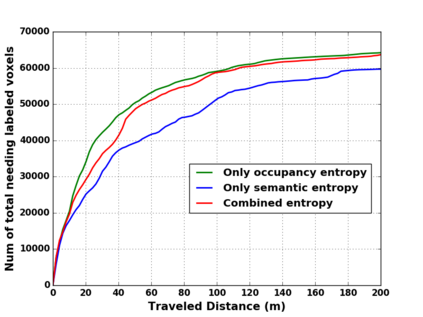
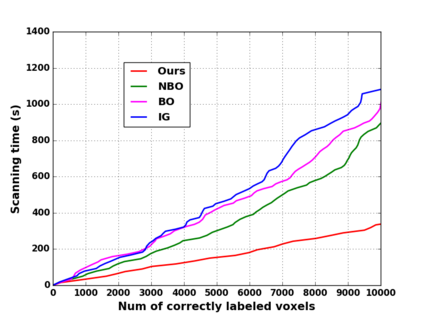
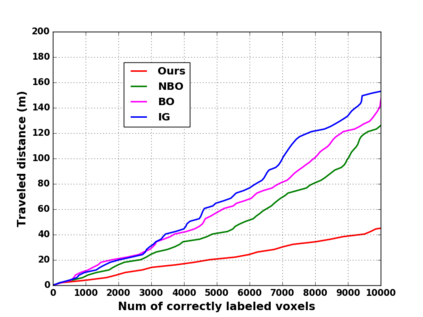
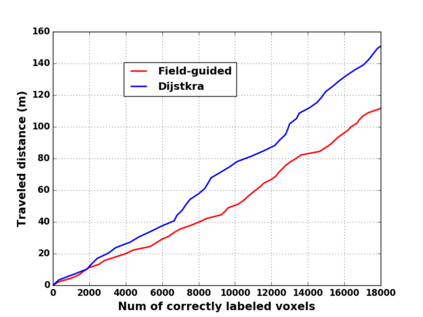
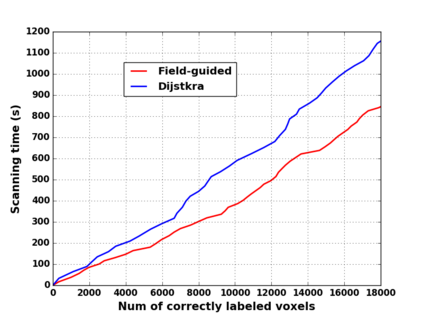
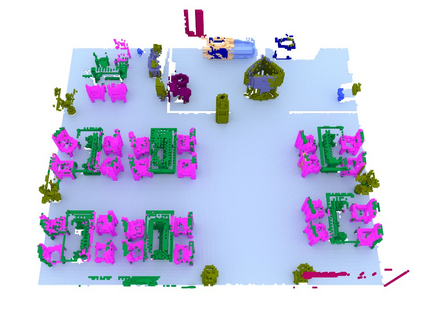
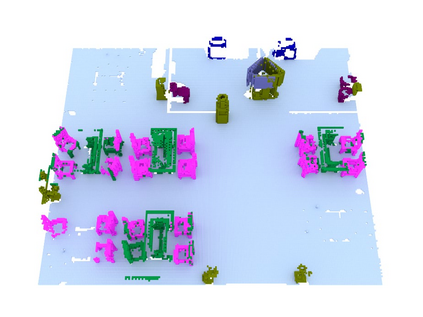
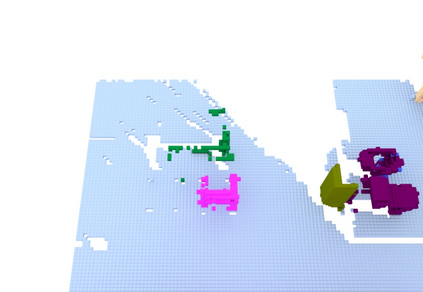
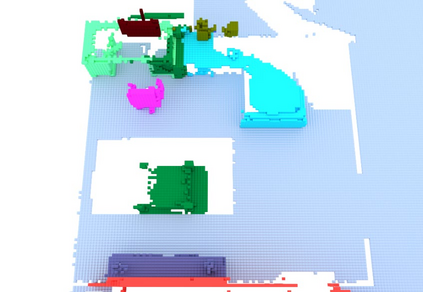
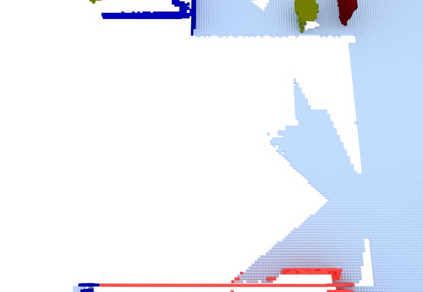
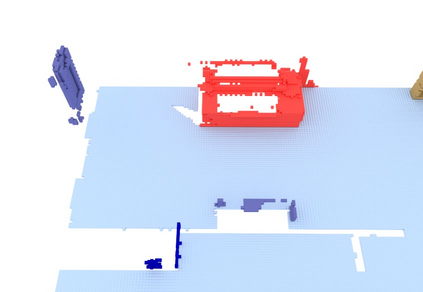
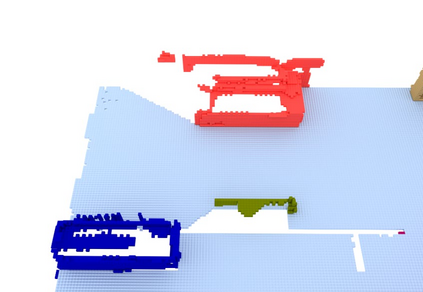
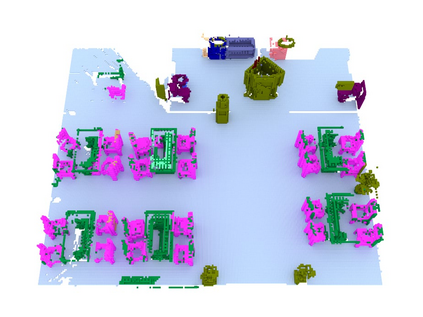
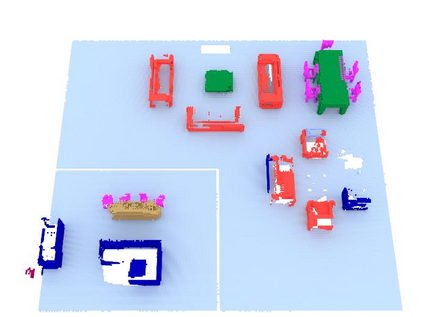
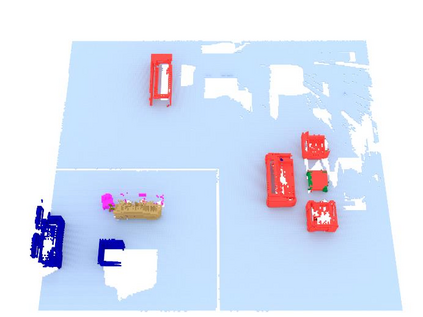
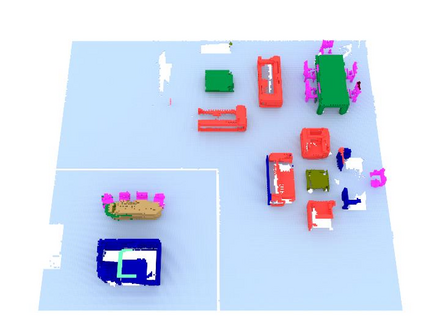
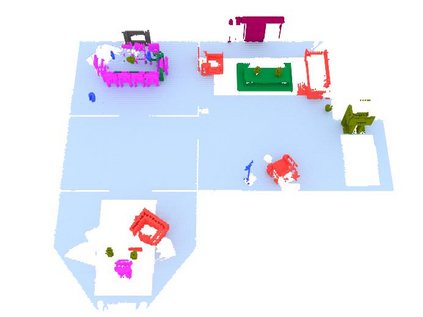
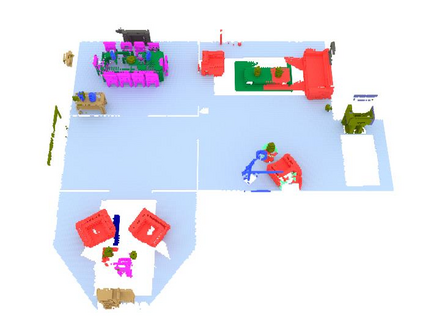
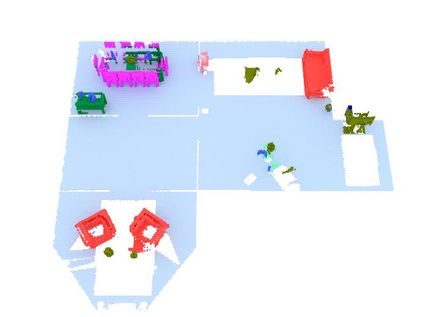
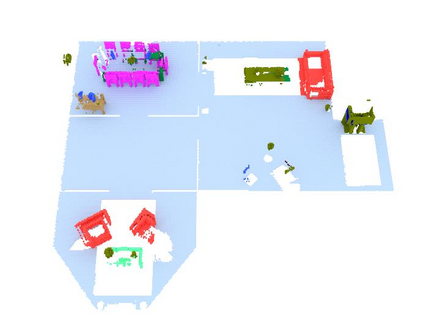
We propose a novel approach to robot-operated active understanding of unknown indoor scenes, based on online RGBD reconstruction with semantic segmentation. In our method, the exploratory robot scanning is both driven by and targeting at the recognition and segmentation of semantic objects from the scene. Our algorithm is built on top of the volumetric depth fusion framework (e.g., KinectFusion) and performs real-time voxel-based semantic labeling over the online reconstructed volume. The robot is guided by an online estimated discrete viewing score field (VSF) parameterized over the 3D space of 2D location and azimuth rotation. VSF stores for each grid the score of the corresponding view, which measures how much it reduces the uncertainty (entropy) of both geometric reconstruction and semantic labeling. Based on VSF, we select the next best views (NBV) as the target for each time step. We then jointly optimize the traverse path and camera trajectory between two adjacent NBVs, through maximizing the integral viewing score (information gain) along path and trajectory. Through extensive evaluation, we show that our method achieves efficient and accurate online scene parsing during exploratory scanning.
翻译:我们建议一种新颖的方法,在网上 RGBD 重建 RGBD 以语义分隔法为基础,积极理解未知室内场景。 在我们的方法中,探索性机器人扫描由来自现场的语义物体的识别和分化驱动,并以这些物体的分数为目标。我们的算法建在体积深度聚合框架(如KinectFusion)的顶部,对在线重建的体积进行基于oxel 的实时文体标贴。机器人以在线估计离散查看分评分场参数为指导,在2D 位置和方位旋转的 3D 空间上设定参数。每个网格的 VSF 储存相应视图的分数,用来衡量它如何减少几何重整和语义标记的不确定性( entropyy) 。 我们根据VSF, 选择下一个最佳视图( NBVV) 作为每个时间步骤的目标。 然后我们共同优化两个相邻的 NBVV 之间的轨迹和摄像轨迹轨迹, 通过尽可能扩大统一浏览分数( 信息获得) 和扫描轨道。通过广泛的评估,我们的方法在网上的轨道上找到。