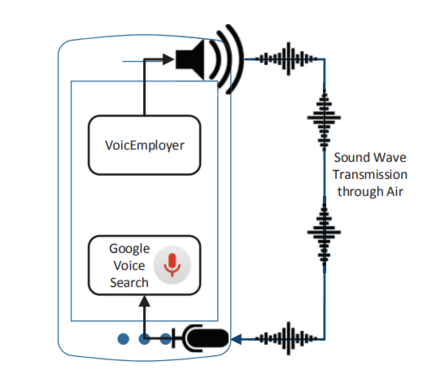
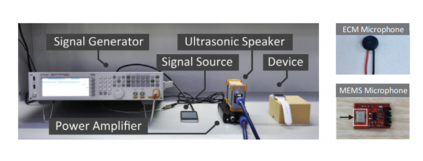
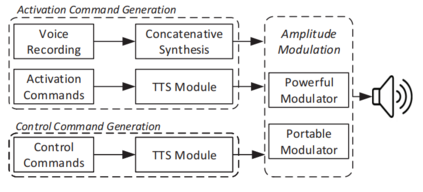
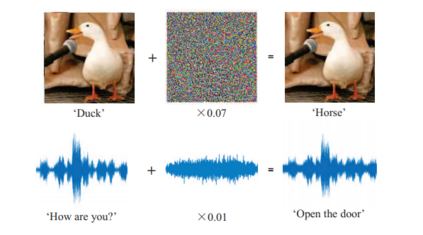
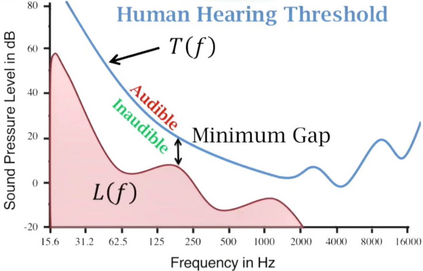
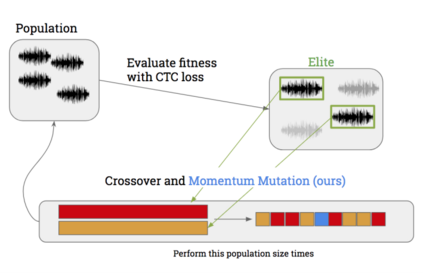
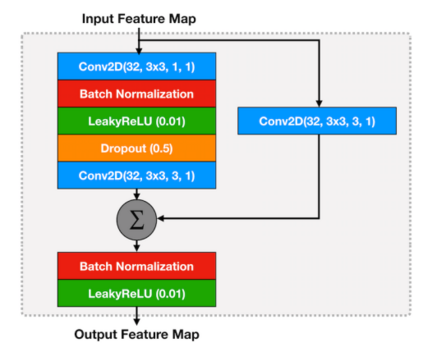
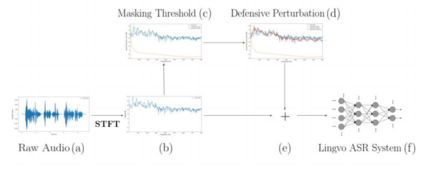
In contemporary society, voice-controlled devices, such as smartphones and home assistants, have become pervasive due to their advanced capabilities and functionality. The always-on nature of their microphones offers users the convenience of readily accessing these devices. However, recent research and events have revealed that such voice-controlled devices are prone to various forms of malicious attacks, hence making it a growing concern for both users and researchers to safeguard against such attacks. Despite the numerous studies that have investigated adversarial attacks and privacy preservation for images, a conclusive study of this nature has not been conducted for the audio domain. Therefore, this paper aims to examine existing approaches for privacy-preserving and privacy-attacking strategies for audio and speech. To achieve this goal, we classify the attack and defense scenarios into several categories and provide detailed analysis of each approach. We also interpret the dissimilarities between the various approaches, highlight their contributions, and examine their limitations. Our investigation reveals that voice-controlled devices based on neural networks are inherently susceptible to specific types of attacks. Although it is possible to enhance the robustness of such models to certain forms of attack, more sophisticated approaches are required to comprehensively safeguard user privacy.
翻译:暂无翻译