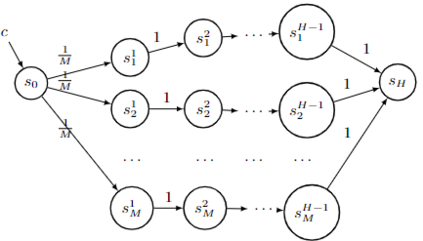
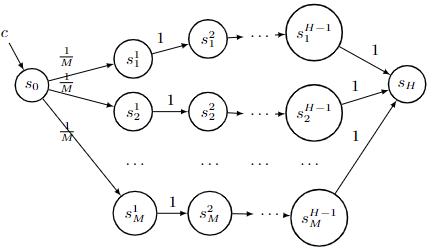
We present regret minimization algorithms for stochastic contextual MDPs under minimum reachability assumption, using an access to an offline least square regression oracle. We analyze three different settings: where the dynamics is known, where the dynamics is unknown but independent of the context and the most challenging setting where the dynamics is unknown and context-dependent. For the latter, our algorithm obtains $ \tilde{O}\left( \max\{H,{1}/{p_{min}}\}H|S|^{3/2}\sqrt{|A|T\log(\max\{|\mathcal{F}|,|\mathcal{P}|\}/\delta)} \right)$ regret bound, with probability $1-\delta$, where $\mathcal{P}$ and $\mathcal{F}$ are finite and realizable function classes used to approximate the dynamics and rewards respectively, $p_{min}$ is the minimum reachability parameter, $S$ is the set of states, $A$ the set of actions, $H$ the horizon, and $T$ the number of episodes. To our knowledge, our approach is the first optimistic approach applied to contextual MDPs with general function approximation (i.e., without additional knowledge regarding the function class, such as it being linear and etc.). In addition, we present a lower bound of $\Omega(\sqrt{T H |S| |A| \ln(|\mathcal{F}|/|S|)/\ln(|A|)})$, on the expected regret which holds even in the case of known dynamics.
翻译:在最小可达性假设下,我们为背景的微调 MDP 提供了最小最小值算法 。 我们分析了三种不同的设置 : 当动态为已知的, 动态为未知的, 但独立于上下文和最具挑战性的环境, 动态为未知且取决于上下文 。 对于后者, 我们的算法获得了 $\ tdelde{ O\ left( max ⁇ H, {1} / p ⁇ }H ⁇ 3/2 ⁇ sqrt}A ⁇ T\log (\maxmaxal{F}, mathcal{ P ⁇ / delta}\right) $( mathcal{ {P} ) 时, 我们的算法是最小值和可实现的函数。 $\\\\\\\\\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \