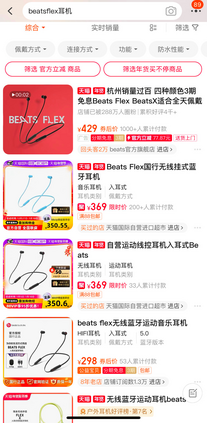
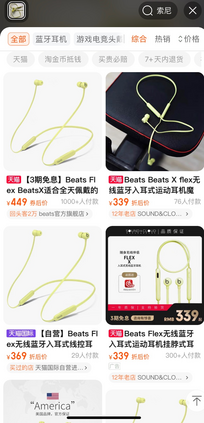
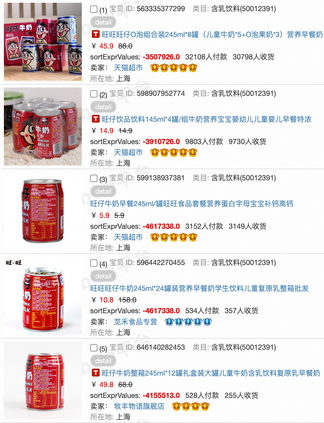
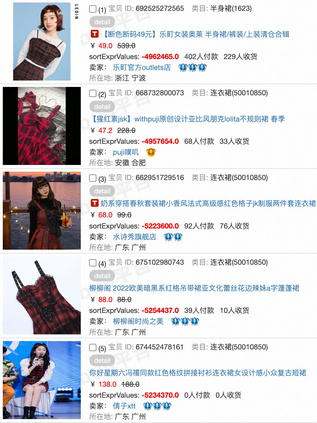
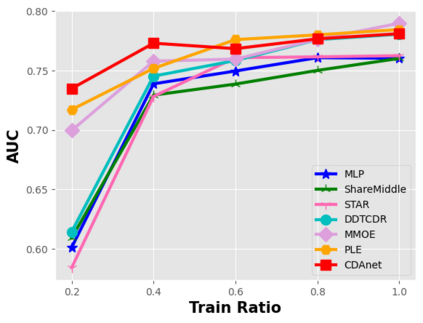
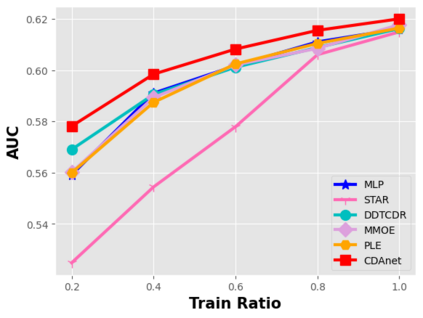
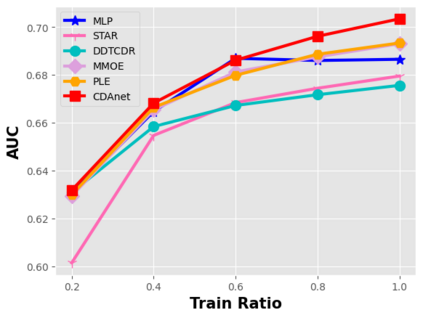
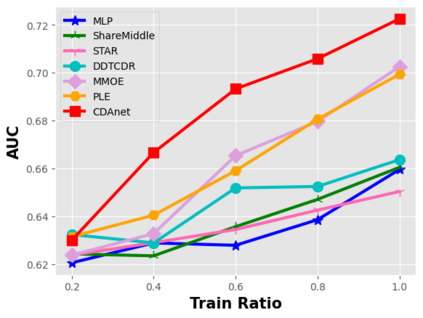
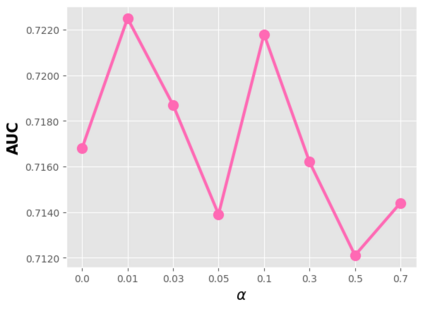
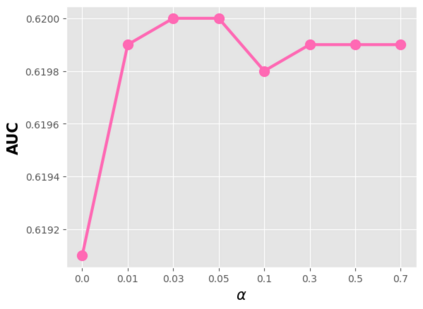
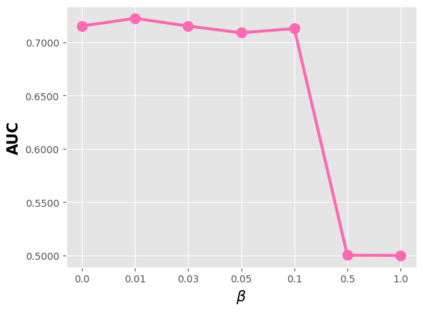
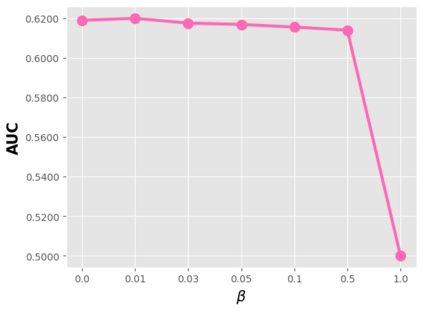
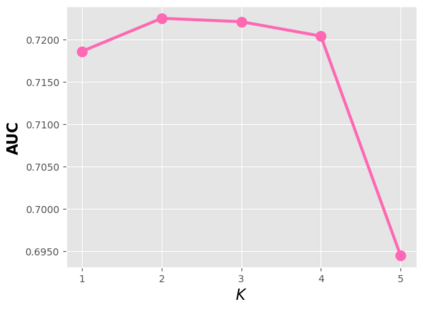
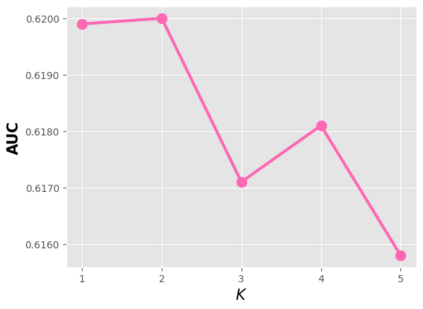
Data sparsity is an important issue for click-through rate (CTR) prediction, particularly when user-item interactions is too sparse to learn a reliable model. Recently, many works on cross-domain CTR (CDCTR) prediction have been developed in an effort to leverage meaningful data from a related domain. However, most existing CDCTR works have an impractical limitation that requires homogeneous inputs (\textit{i.e.} shared feature fields) across domains, and CDCTR with heterogeneous inputs (\textit{i.e.} varying feature fields) across domains has not been widely explored but is an urgent and important research problem. In this work, we propose a cross-domain augmentation network (CDAnet) being able to perform knowledge transfer between two domains with \textit{heterogeneous inputs}. Specifically, CDAnet contains a designed translation network and an augmentation network which are trained sequentially. The translation network is able to compute features from two domains with heterogeneous inputs separately by designing two independent branches, and then learn meaningful cross-domain knowledge using a designed cross-supervised feature translator. Later the augmentation network encodes the learned cross-domain knowledge via feature translation performed in the latent space and fine-tune the model for final CTR prediction. Through extensive experiments on two public benchmarks and one industrial production dataset, we show CDAnet can learn meaningful translated features and largely improve the performance of CTR prediction. CDAnet has been conducted online A/B test in image2product retrieval at Taobao app over 20days, bringing an absolute \textbf{0.11 point} CTR improvement and a relative \textbf{1.26\%} GMV increase.
翻译:暂无翻译