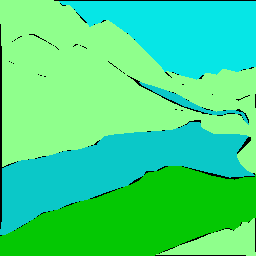
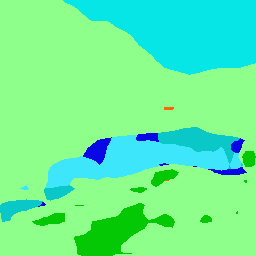
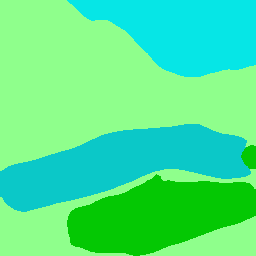
Recent works have widely explored the contextual dependencies to achieve more accurate segmentation results. However, most approaches rarely distinguish different types of contextual dependencies, which may pollute the scene understanding. In this work, we directly supervise the feature aggregation to distinguish the intra-class and inter-class context clearly. Specifically, we develop a Context Prior with the supervision of the Affinity Loss. Given an input image and corresponding ground truth, Affinity Loss constructs an ideal affinity map to supervise the learning of Context Prior. The learned Context Prior extracts the pixels belonging to the same category, while the reversed prior focuses on the pixels of different classes. Embedded into a conventional deep CNN, the proposed Context Prior Layer can selectively capture the intra-class and inter-class contextual dependencies, leading to robust feature representation. To validate the effectiveness, we design an effective Context Prior Network (CPNet). Extensive quantitative and qualitative evaluations demonstrate that the proposed model performs favorably against state-of-the-art semantic segmentation approaches. More specifically, our algorithm achieves 46.3% mIoU on ADE20K, 53.9% mIoU on PASCAL-Context, and 81.3% mIoU on Cityscapes. Code is available at https://git.io/ContextPrior.
翻译:最近的工作广泛探索了背景依赖性,以取得更准确的分化结果。然而,大多数方法很少区分不同类型的背景依赖性,这可能会污染现场理解。在这项工作中,我们直接监督特征聚合,以明确区分阶级内部和阶级间背景。具体地说,我们开发了“亲系损失前”监督框架。根据输入图像和相应的地面真相,“亲系损失”构建了理想的亲近性地图,以监督对背景的学习。学习过的“前背景”提取属于同一类别的像素,而先前的偏移则侧重于不同类别的像素。在传统的深层次CNN中,拟议的“背景前层”可有选择地捕捉到阶级内部和阶级间背景依赖性,从而形成强有力的特征代表。为了验证有效性,我们设计了一个有效的“背景前网络”(CPNet) 。广泛的定量和定性评估表明,拟议的模型对州-艺术的语系分化方法起到了有利的作用。更具体地说,我们的算法在ADE20K、53.9% mI在城市代码上实现了46.ASCASC-CLtext。