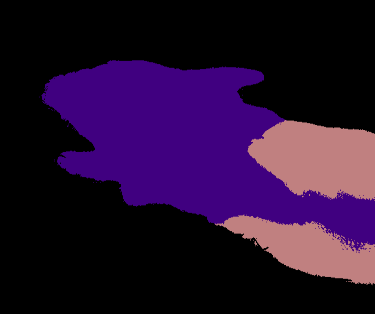
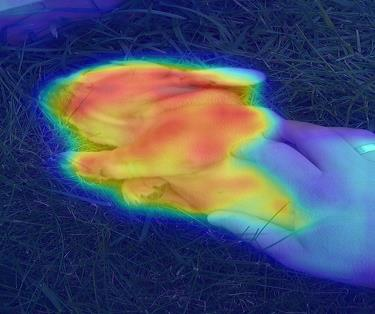
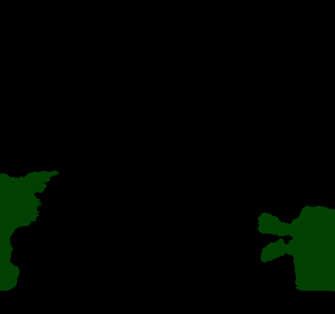
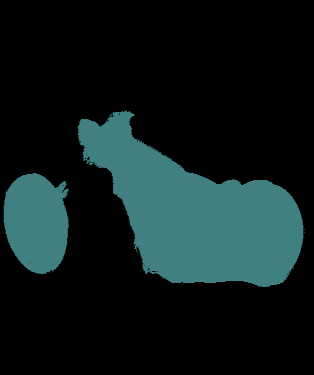
Compared to conventional semantic segmentation with pixel-level supervision, Weakly Supervised Semantic Segmentation (WSSS) with image-level labels poses the challenge that it always focuses on the most discriminative regions, resulting in a disparity between fully supervised conditions. A typical manifestation is the diminished precision on the object boundaries, leading to a deteriorated accuracy of WSSS. To alleviate this issue, we propose to adaptively partition the image content into deterministic regions (e.g., confident foreground and background) and uncertain regions (e.g., object boundaries and misclassified categories) for separate processing. For uncertain cues, we employ an activation-based masking strategy and seek to recover the local information with self-distilled knowledge. We further assume that the unmasked confident regions should be robust enough to preserve the global semantics. Building upon this, we introduce a complementary self-enhancement method that constrains the semantic consistency between these confident regions and an augmented image with the same class labels. Extensive experiments conducted on PASCAL VOC 2012 and MS COCO 2014 demonstrate that our proposed single-stage approach for WSSS not only outperforms state-of-the-art benchmarks remarkably but also surpasses multi-stage methodologies that trade complexity for accuracy. The code can be found at \url{https://github.com/Jessie459/feature-self-reinforcement}.
翻译:暂无翻译