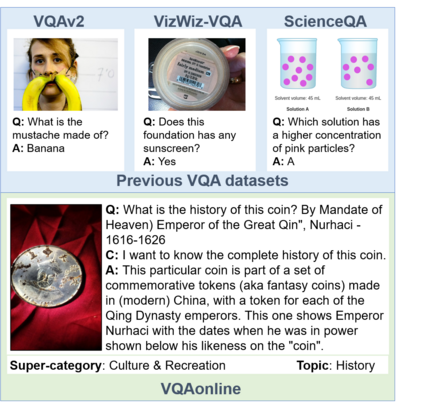
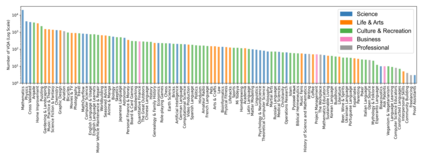
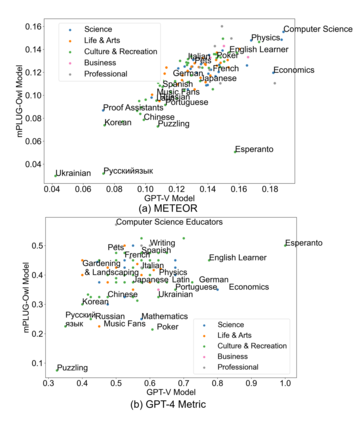
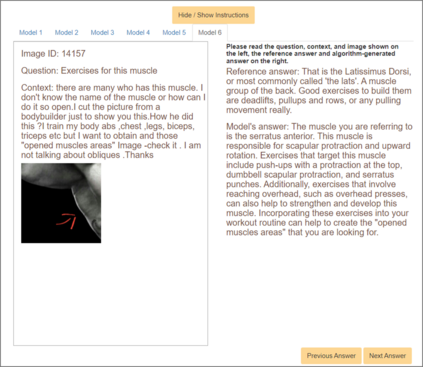
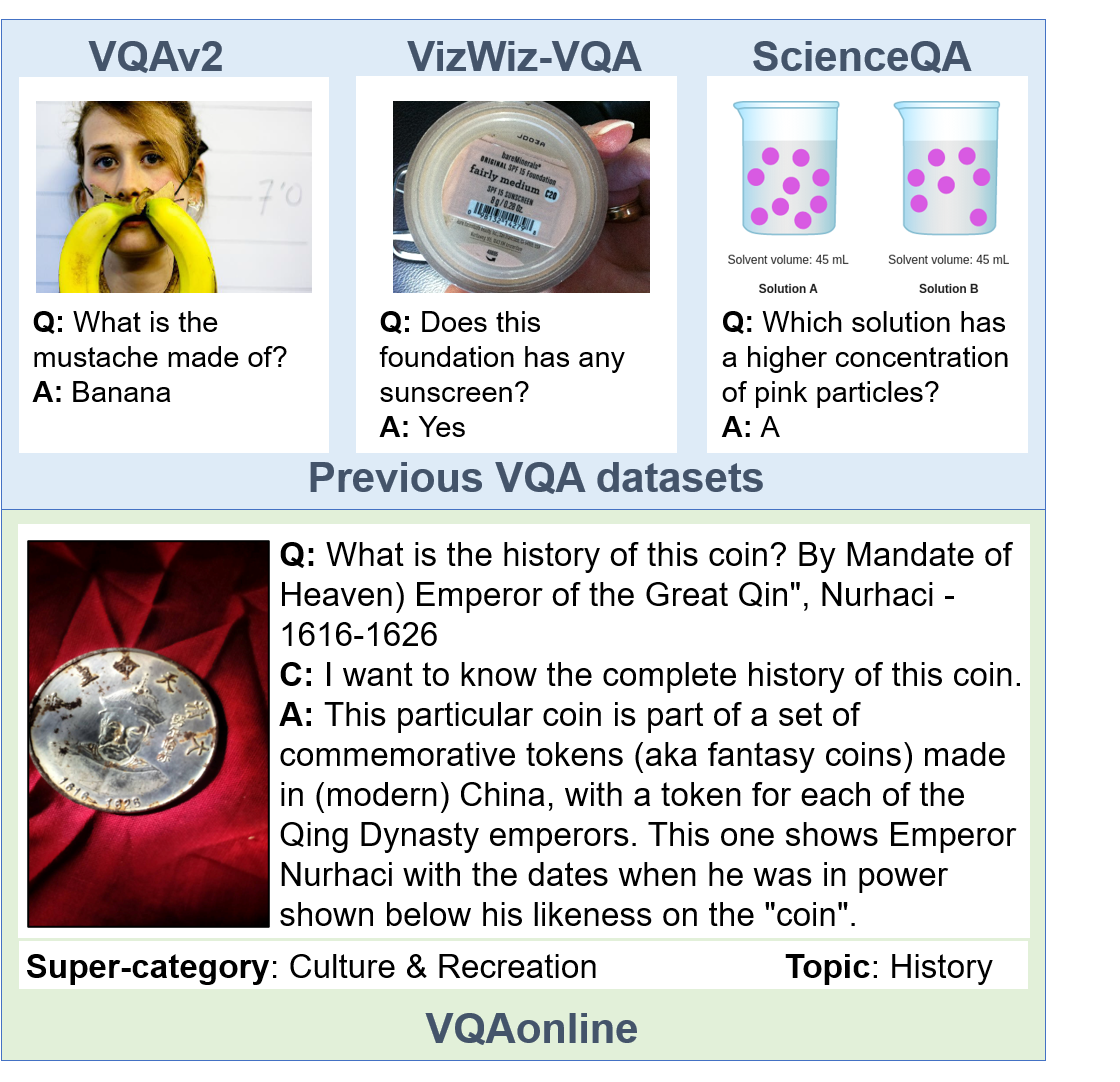
Visual Question Answering (VQA) entails answering questions about images. We introduce the first VQA dataset in which all contents originate from an authentic use case. Sourced from online question answering community forums, we call it VQAonline. We then characterize our dataset and how it relates to eight other VQA datasets. Observing that answers in our dataset tend to be much longer (e.g., with a mean of 173 words) and thus incompatible with standard VQA evaluation metrics, we next analyze which of the six popular metrics for longer text evaluation align best with human judgments. We then use the best-suited metrics to evaluate six state-of-the-art vision and language foundation models on VQAonline and reveal where they struggle most. The dataset can be found publicly at https://vqaonline.github.io/.
翻译:暂无翻译