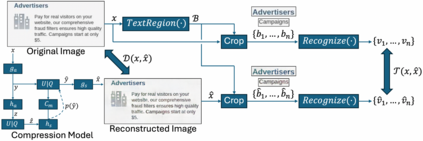
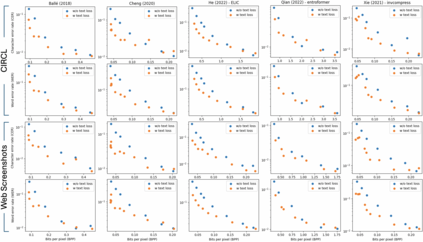
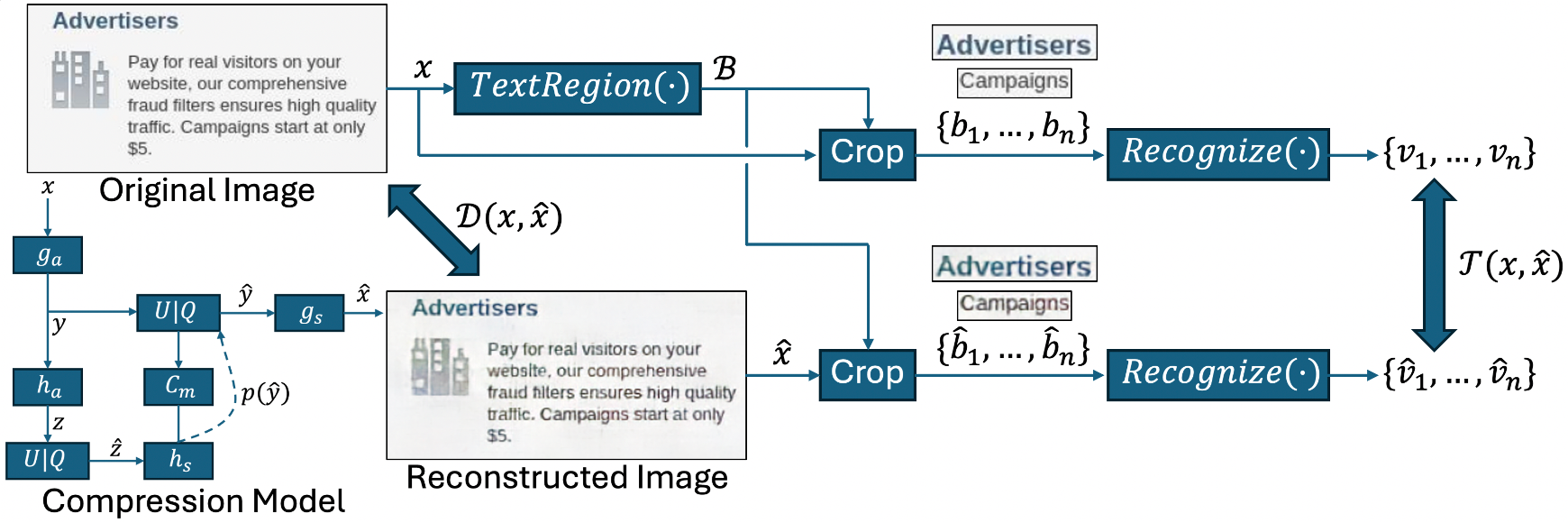
Learned image compression has gained widespread popularity for their efficiency in achieving ultra-low bit-rates. Yet, images containing substantial textual content, particularly screen-content images (SCI), often suffers from text distortion at such compressed levels. To address this, we propose to minimize a novel text logit loss designed to quantify the disparity in text between the original and reconstructed images, thereby improving the perceptual quality of the reconstructed text. Through rigorous experimentation across diverse datasets and employing state-of-the-art algorithms, our findings reveal significant enhancements in the quality of reconstructed text upon integration of the proposed loss function with appropriate weighting. Notably, we achieve a Bjontegaard delta (BD) rate of -32.64% for Character Error Rate (CER) and -28.03% for Word Error Rate (WER) on average by applying the text logit loss for two screenshot datasets. Additionally, we present quantitative metrics tailored for evaluating text quality in image compression tasks. Our findings underscore the efficacy and potential applicability of our proposed text logit loss function across various text-aware image compression contexts.
翻译:暂无翻译