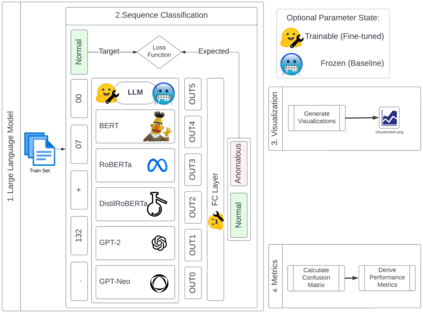
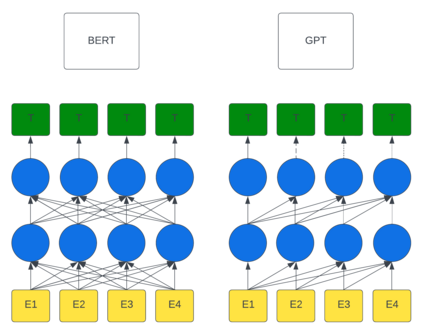
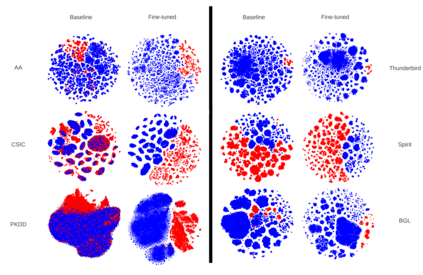
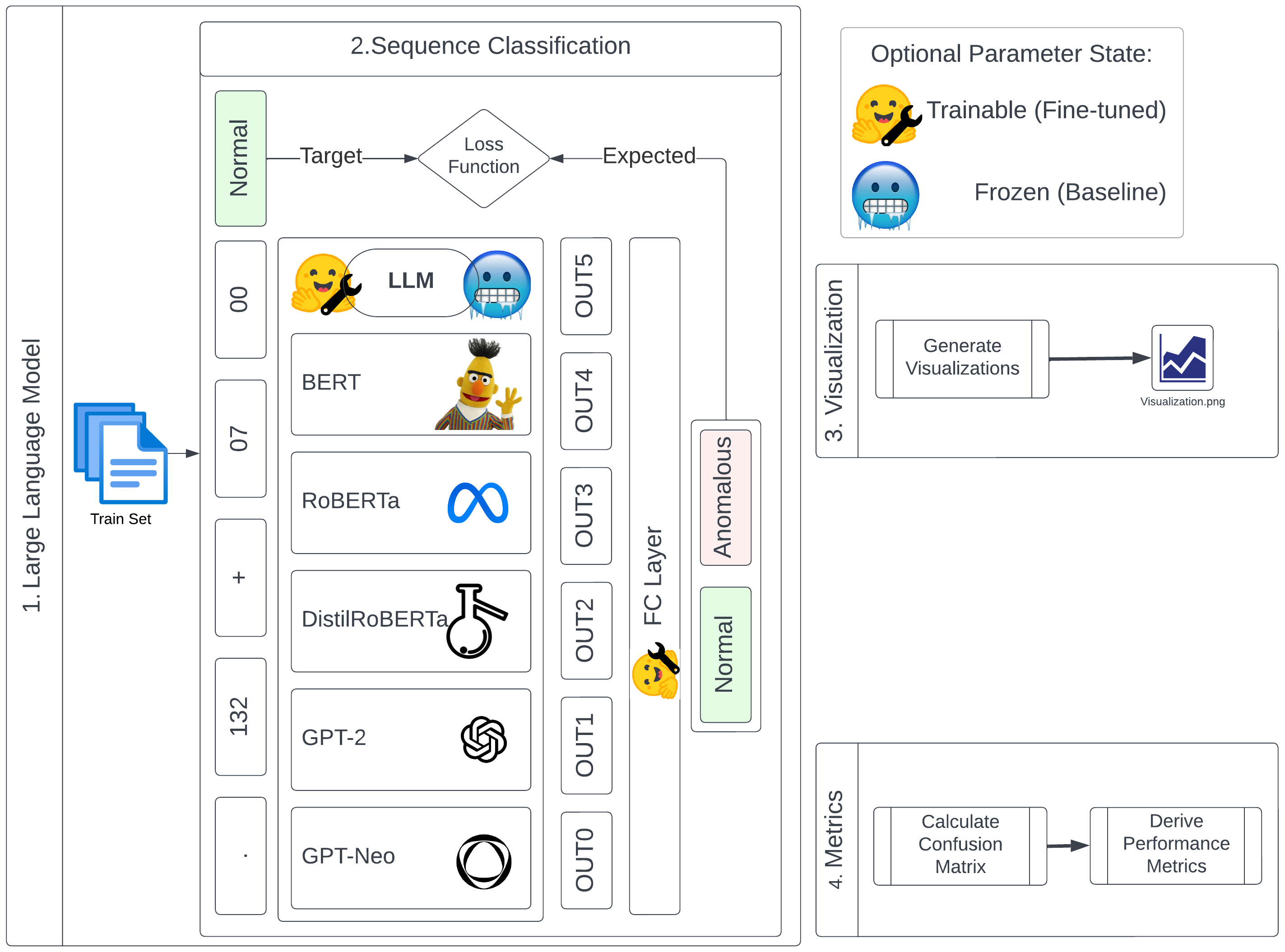
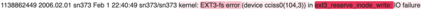Large Language Models (LLM) continue to demonstrate their utility in a variety of emergent capabilities in different fields. An area that could benefit from effective language understanding in cybersecurity is the analysis of log files. This work explores LLMs with different architectures (BERT, RoBERTa, DistilRoBERTa, GPT-2, and GPT-Neo) that are benchmarked for their capacity to better analyze application and system log files for security. Specifically, 60 fine-tuned language models for log analysis are deployed and benchmarked. The resulting models demonstrate that they can be used to perform log analysis effectively with fine-tuning being particularly important for appropriate domain adaptation to specific log types. The best-performing fine-tuned sequence classification model (DistilRoBERTa) outperforms the current state-of-the-art; with an average F1-Score of 0.998 across six datasets from both web application and system log sources. To achieve this, we propose and implement a new experimentation pipeline (LLM4Sec) which leverages LLMs for log analysis experimentation, evaluation, and analysis.
翻译:暂无翻译