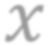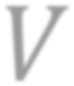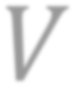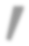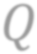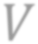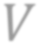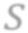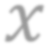While self-supervised learning has been shown to benefit a number of vision tasks, existing techniques mainly focus on image-level manipulation, which may not generalize well to downstream tasks at patch or pixel levels. Moreover, existing SSL methods might not sufficiently describe and associate the above representations within and across image scales. In this paper, we propose a Self-Supervised Pyramid Representation Learning (SS-PRL) framework. The proposed SS-PRL is designed to derive pyramid representations at patch levels via learning proper prototypes, with additional learners to observe and relate inherent semantic information within an image. In particular, we present a cross-scale patch-level correlation learning in SS-PRL, which allows the model to aggregate and associate information learned across patch scales. We show that, with our proposed SS-PRL for model pre-training, one can easily adapt and fine-tune the models for a variety of applications including multi-label classification, object detection, and instance segmentation.
翻译:虽然自我监督的学习已被证明有益于一些愿景任务,但现有技术主要侧重于图像操作,可能无法在补丁或像素级别上将图像操作推广到下游任务,此外,现有的SSL方法可能不足以描述和将上述表述在图像规模之内和之间联系起来。在本文件中,我们提议了一个自我监督的金字塔代表学习(SS-PRL)框架。拟议的SS-PRL旨在通过学习适当的原型在补丁层次上产生金字塔的表示方式,让更多的学习者在图像中观察和联系内在的语义信息。特别是,我们在SS-PRL中展示了跨尺度的跨层次的补丁级相关学习,使得该模型能够汇总和联系跨补丁尺度上获得的信息。我们表明,我们提议的SS-PRL用于模型预培训,可以很容易地调整和微调各种应用模式的模式,包括多标签分类、对象探测和实例分割。