
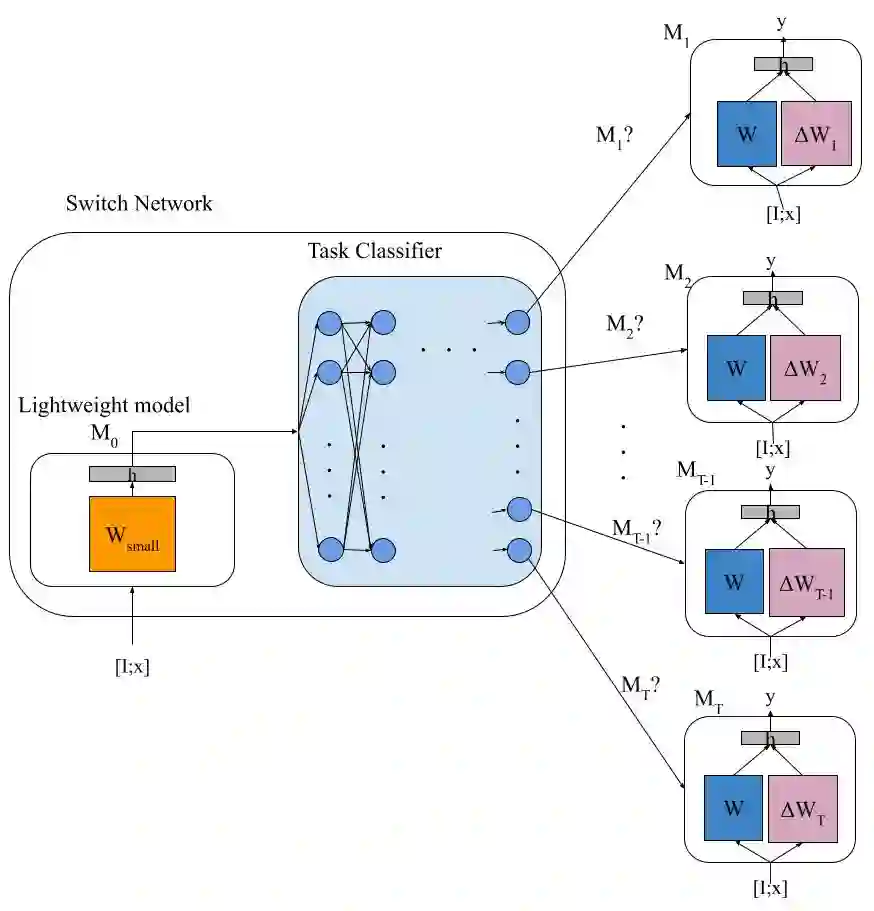
Large language models (LLMs) and multimodal models (MMs) have exhibited impressive capabilities in various domains, particularly in general language understanding and visual reasoning. However, these models, trained on massive data, may not be finely optimized for specific tasks triggered by instructions. Continual instruction tuning is crucial to adapt a large model to evolving tasks and domains, ensuring their effectiveness and relevance across a wide range of applications. In the context of continual instruction tuning, where models are sequentially trained on different tasks, catastrophic forgetting can occur, leading to performance degradation on previously learned tasks. This work addresses the catastrophic forgetting in continual instruction learning through a switching mechanism for routing computations to parameter-efficient tuned models. We demonstrate the effectiveness of our method through experiments on continual instruction tuning of different natural language generation tasks and vision-language tasks. We also showcase the advantages of our proposed method in terms of efficiency, scalability, portability, and privacy preservation.
翻译:暂无翻译
相关内容

Source: Apple - iOS 8

