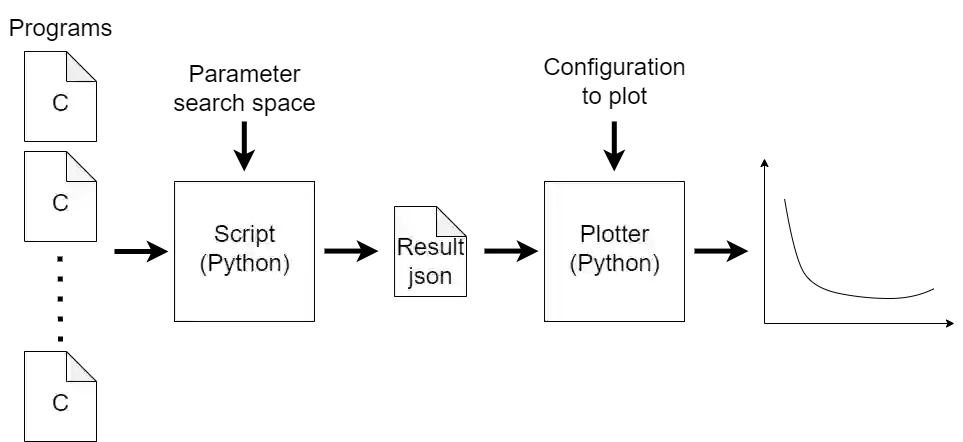
OpenMP is the de facto API for parallel programming in HPC applications. These programs are often computed in data centers, where energy consumption is a major issue. Whereas previous work has focused almost entirely on performance, we here analyse aspects of OpenMP from an energy consumption perspective. This analysis is accomplished by executing novel microbenchmarks and common benchmark suites on data center nodes and measuring the energy consumption. Three main aspects are analysed: directive-generated loop tiling and unrolling, parallel for loops and explicit tasking, and the policy of handling blocked threads. For loop tiling and unrolling, we find that tiling can yield significant energy savings for some, mostly unoptimised programs, while directive-generated unrolling provides very minor improvement in the best case and degenerates performance majorly in the worst case. For the second aspect, we find that parallel for loops yield better results than explicit tasking loops in cases where both can be used. This becomes more prominent with more fine-grained workloads. For the third, we find that significant energy savings can be made by not descheduling waiting threads, but instead having them spin, at the cost of a higher power consumption. We also analyse how the choice of compiler affects the above questions by compiling programs with each of ICC, Clang and GCC, and find that while neither is strictly better than the others, they can produce very different results for the same compiled programs. As a final step, we combine the findings of all results and suggest novel compiler directives as well as general recommendations on how to reduce energy consumption in OpenMP programs.
翻译:OpenMP 是用于 HPC 应用程序中平行编程的事实上的 API 。 这些程序通常在数据中心计算, 能源消耗是一个主要问题。 虽然先前的工作几乎完全侧重于绩效, 我们在这里从能源消耗的角度分析 OpenMP 的方方面面。 分析是通过在数据中心节点和能源消耗量测量方面执行新的微基准标志和共同基准套件完成的。 我们发现, 在使用两种方法的情况下, 与明确的任务环绕比明确的任务圈更相似, 并同时处理被封的线条。 对于环绕、 环绕和不滚动, 我们发现, 编织能为某些指令, 主要是不优化的程序带来巨大的节能节约, 而由指令生成的无节律则在最佳的情况下带来很小的改善, 而在最坏的情况下, 我们发现, 循环的平行的结果比明确的任务圈更明显地产生结果。 在使用这两种方法的情况下, 这更突出的是, 对于更精细的工作量。 第三, 我们发现, 我们发现, 大幅的节能可以通过不拖延的步伐来节省一些,, 主要是不精细的节线线, 而由指令产生的不精细的节制程序产生节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制的节制, 。