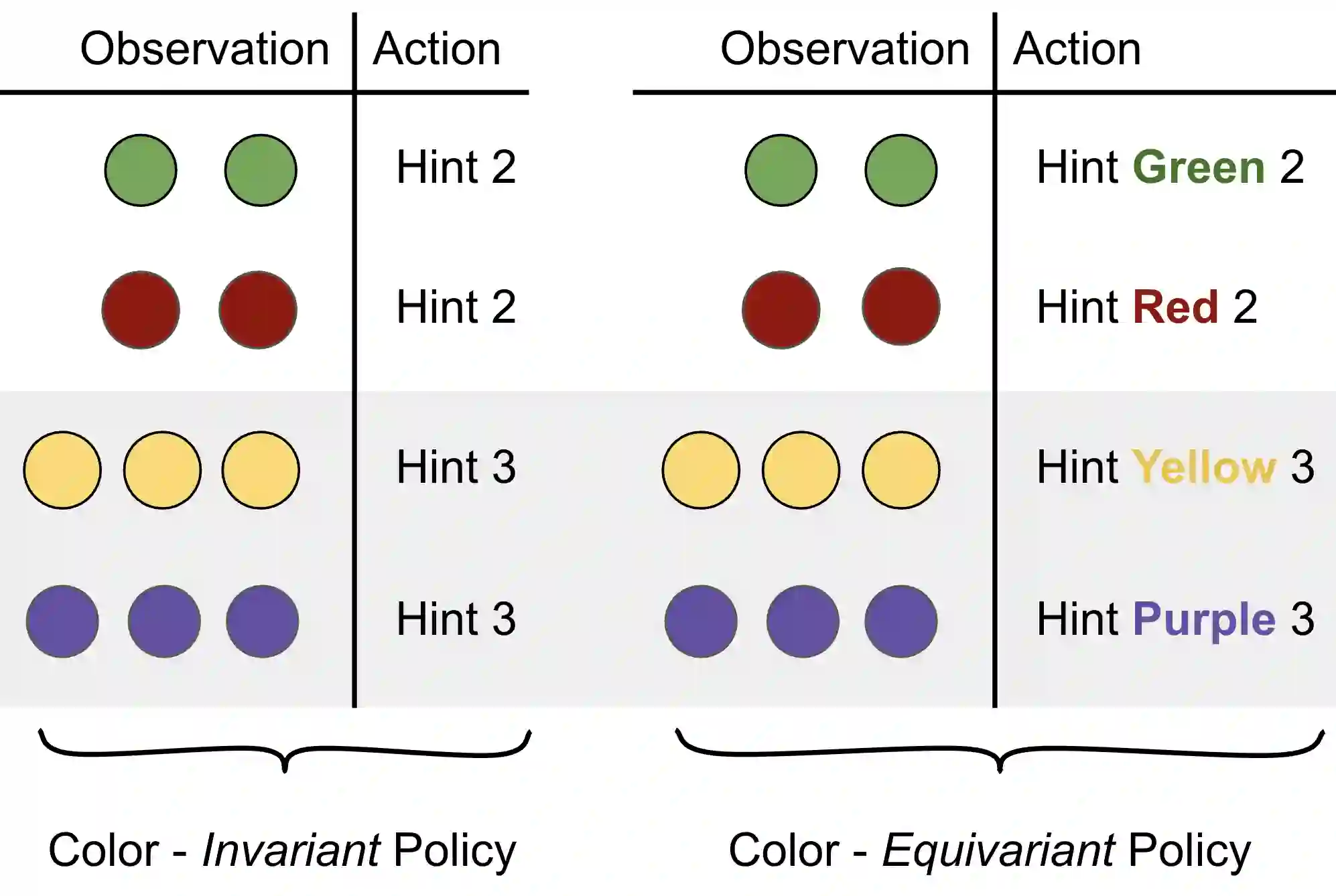
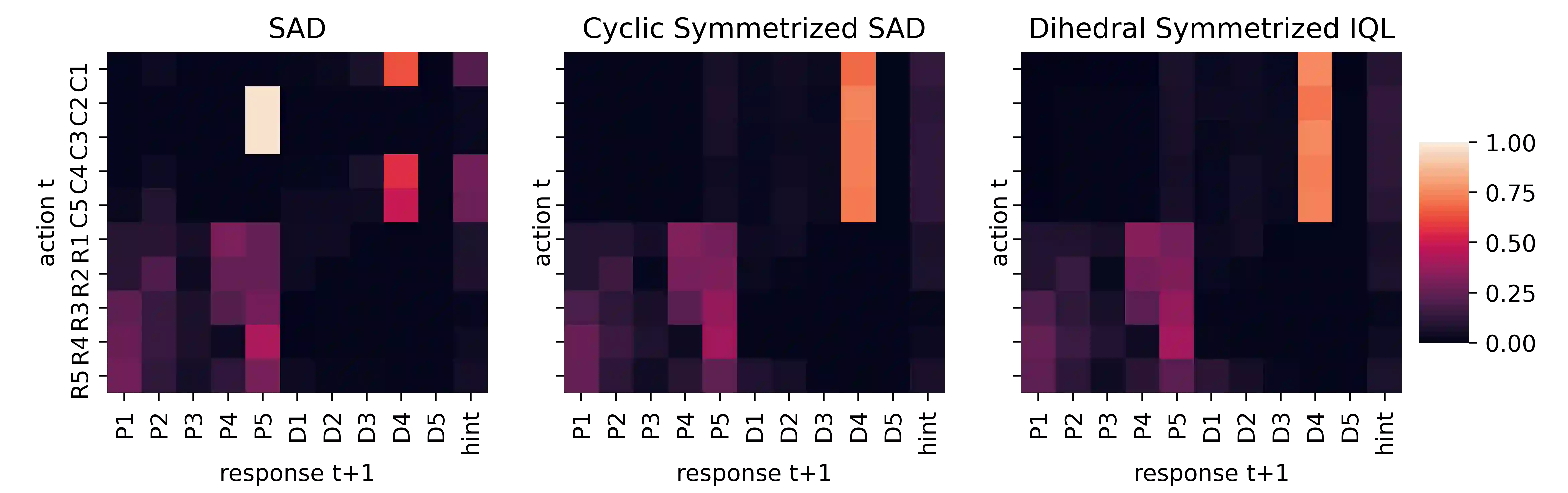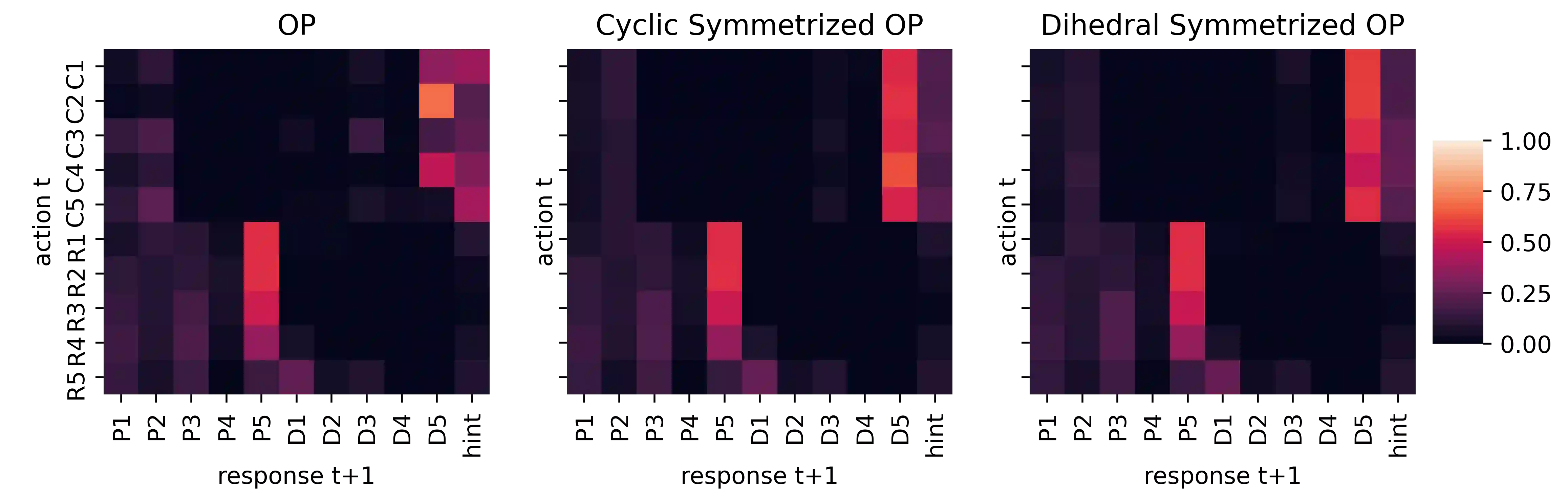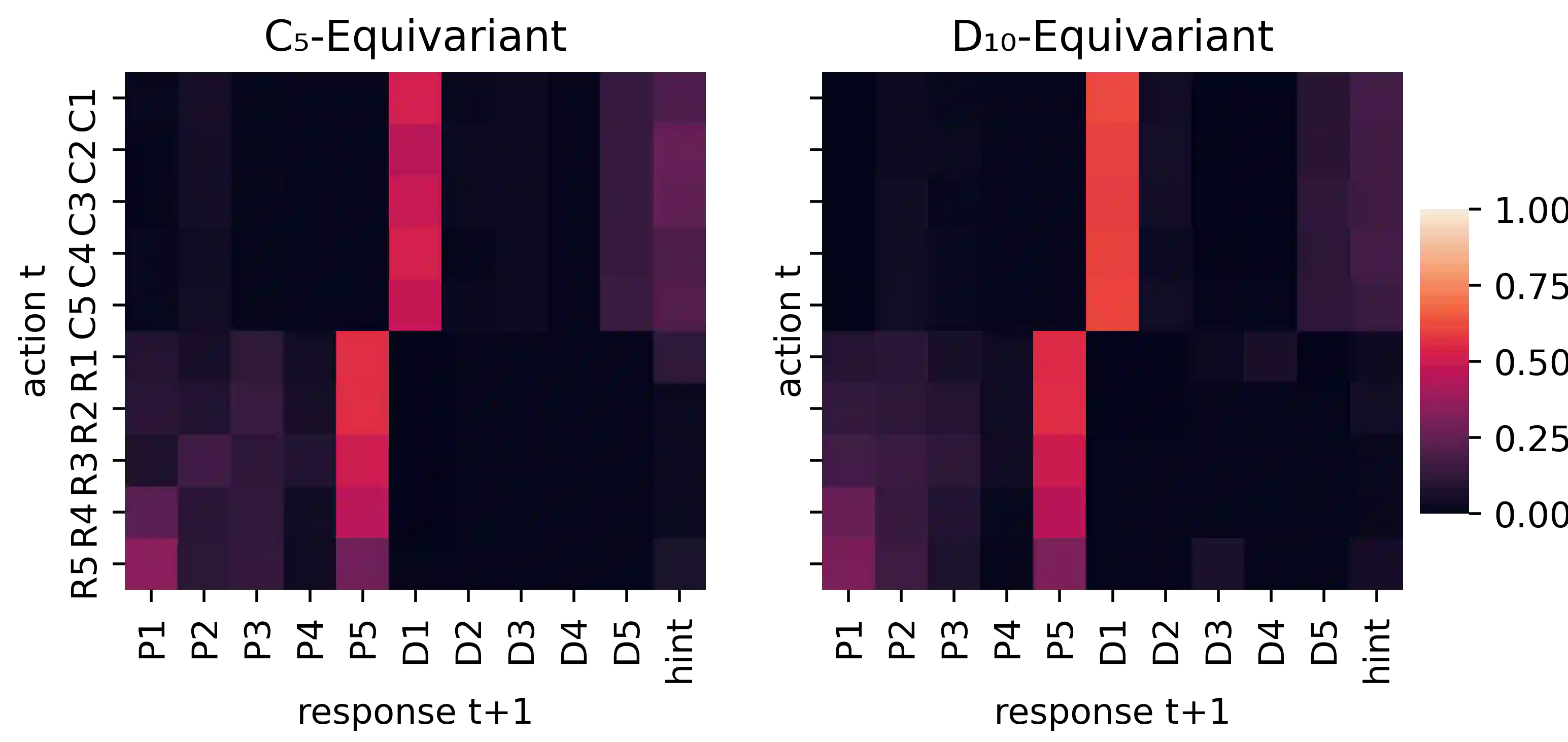Successful coordination in Dec-POMDPs requires agents to adopt robust strategies and interpretable styles of play for their partner. A common failure mode is symmetry breaking, when agents arbitrarily converge on one out of many equivalent but mutually incompatible policies. Commonly these examples include partial observability, e.g. waving your right hand vs. left hand to convey a covert message. In this paper, we present a novel equivariant network architecture for use in Dec-POMDPs that prevents the agent from learning policies which break symmetries, doing so more effectively than prior methods. Our method also acts as a "coordination-improvement operator" for generic, pre-trained policies, and thus may be applied at test-time in conjunction with any self-play algorithm. We provide theoretical guarantees of our work and test on the AI benchmark task of Hanabi, where we demonstrate our methods outperforming other symmetry-aware baselines in zero-shot coordination, as well as able to improve the coordination ability of a variety of pre-trained policies. In particular, we show our method can be used to improve on the state of the art for zero-shot coordination on the Hanabi benchmark.
翻译:在Dec-POMDPs中,成功的协调要求代理商为其合伙人采取强有力的策略和可解释的游戏风格。通常的失败模式是对称性打破,当代理商任意地将许多同等但互不相容的政策组合在一起时。这些通常的例子包括部分可观察性,例如挥舞你的右手对左手以传递隐藏信息。在本文中,我们展示了一种新的等同网络架构,供Dec-POMDPs使用,防止代理商学习打破对称的政策,比以前的方法更有效。我们的方法还作为通用的、预先训练的政策的“协调改进操作员”,因此可以与任何自玩算法一起在测试时应用。我们为我们的工作提供理论保证,并测试了Hanabi的AI基准任务,我们在那里展示了我们的方法比零光协调中其他的对称基线要好,并且能够提高各种预先训练的政策的协调能力。我们的方法还表明,我们的方法可以用来改进汉的零光基准的协调状态。