
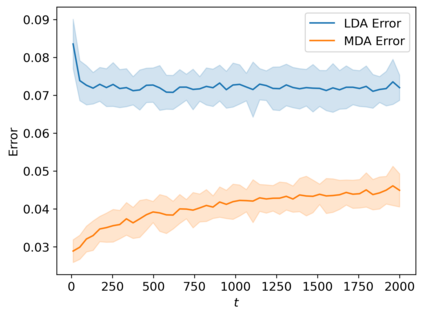
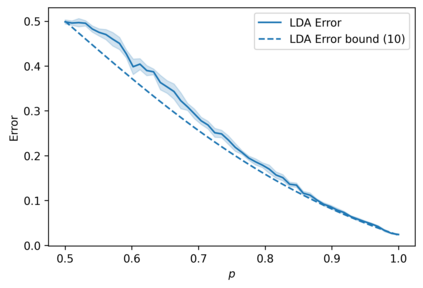
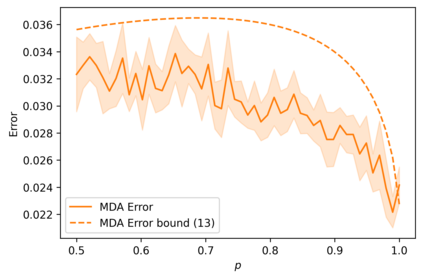
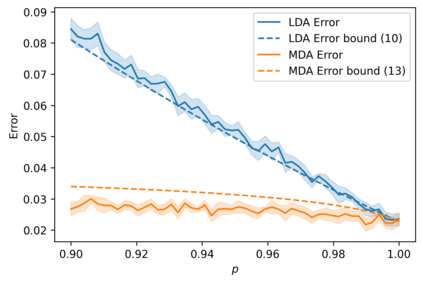
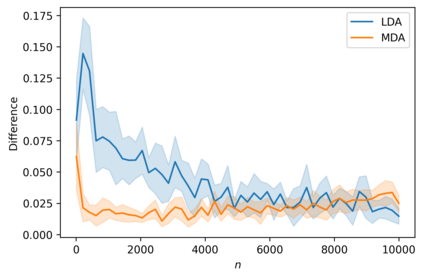
We suggest a simple Gaussian mixture model for data generation that complies with Feldman's long tail theory (2020). We demonstrate that a linear classifier cannot decrease the generalization error below a certain level in the proposed model, whereas a nonlinear classifier with a memorization capacity can. This confirms that for long-tailed distributions, rare training examples must be considered for optimal generalization to new data. Finally, we show that the performance gap between linear and nonlinear models can be lessened as the tail becomes shorter in the subpopulation frequency distribution, as confirmed by experiments on synthetic and real data.
翻译:暂无翻译










相关内容

专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日




相关VIP内容
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
相关资讯
相关论文