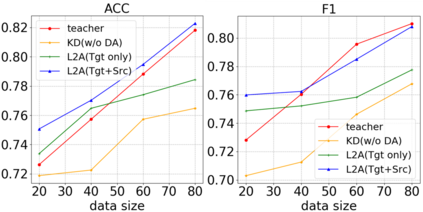
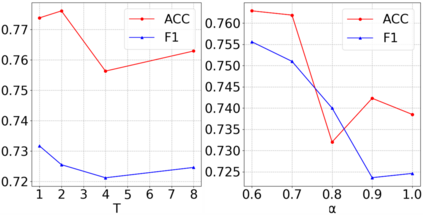
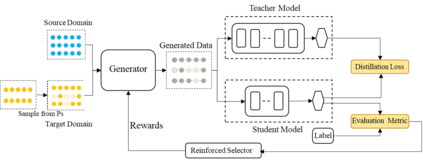Despite pre-trained language models such as BERT have achieved appealing performance in a wide range of natural language processing tasks, they are computationally expensive to be deployed in real-time applications. A typical method is to adopt knowledge distillation to compress these large pre-trained models (teacher models) to small student models. However, for a target domain with scarce training data, the teacher can hardly pass useful knowledge to the student, which yields performance degradation for the student models. To tackle this problem, we propose a method to learn to augment for data-scarce domain BERT knowledge distillation, by learning a cross-domain manipulation scheme that automatically augments the target with the help of resource-rich source domains. Specifically, the proposed method generates samples acquired from a stationary distribution near the target data and adopts a reinforced selector to automatically refine the augmentation strategy according to the performance of the student. Extensive experiments demonstrate that the proposed method significantly outperforms state-of-the-art baselines on four different tasks, and for the data-scarce domains, the compressed student models even perform better than the original large teacher model, with much fewer parameters (only ${\sim}13.3\%$) when only a few labeled examples available.
翻译:尽管诸如BERT等经过事先训练的语言模型在广泛的自然语言处理任务中取得了有吸引力的成绩,但它们在计算上却非常昂贵,需要实时应用。一种典型的方法是采用知识蒸馏法将这些经过训练的大型模型(教师模型)压缩成小型学生模型。然而,对于培训数据稀少的目标领域,教师几乎无法向学生传授有用的知识,从而导致学生模型的性能退化。为了解决这个问题,我们建议了一种方法,通过学习一种跨部操作方案,在资源丰富的来源域的帮助下自动扩大目标,从而学习一种跨部操作方案。具体地说,拟议方法生成了从目标数据附近的固定分布中获得的样本,并采用了一种强化的选择器,以便根据学生的成绩自动完善增强战略。广泛的实验表明,拟议的方法大大超出了四项不同任务的最新基线,而对于数据侵蚀域,压缩学生模型的表现甚至比原始的大型教师模型要好得多,只有少的参数(只有美元),只有很少的参数(只有美元=13*)。