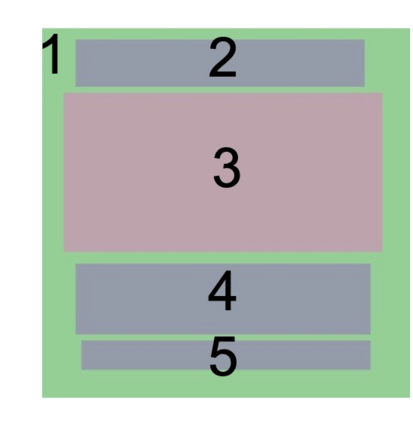
Creative workflows for generating graphical documents involve complex inter-related tasks, such as aligning elements, choosing appropriate fonts, or employing aesthetically harmonious colors. In this work, we attempt at building a holistic model that can jointly solve many different design tasks. Our model, which we denote by FlexDM, treats vector graphic documents as a set of multi-modal elements, and learns to predict masked fields such as element type, position, styling attributes, image, or text, using a unified architecture. Through the use of explicit multi-task learning and in-domain pre-training, our model can better capture the multi-modal relationships among the different document fields. Experimental results corroborate that our single FlexDM is able to successfully solve a multitude of different design tasks, while achieving performance that is competitive with task-specific and costly baselines.
翻译:创造性的图形文档生成工作流涉及到诸多复杂的相互关联的任务,例如对齐元素、选择适当的字体或采用美学协调的颜色。在这项工作中,我们试图构建一个全面性的模型,可以共同解决许多不同的设计任务。我们的模型被称为 FlexDM,将矢量图文档视为一组多模态元素,并学习使用统一的架构来预测掩码字段,例如元素类型、位置、样式属性、图像或文本。通过使用显式的多任务学习和领域内预训练,我们的模型可以更好地捕捉不同文档字段之间的多模态关系。实验结果证明,我们的单个 FlexDM 能够成功解决许多不同的设计任务,同时实现的性能与任务特定和成本高昂的基线相竞争。