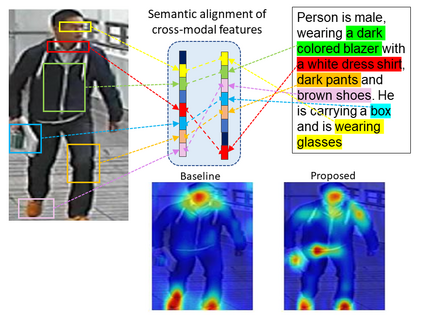
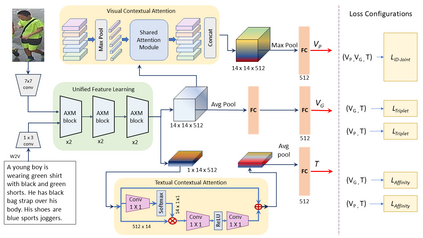
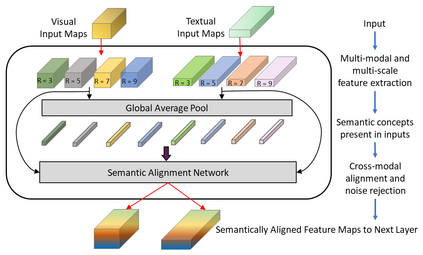
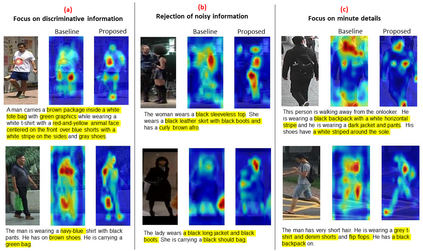
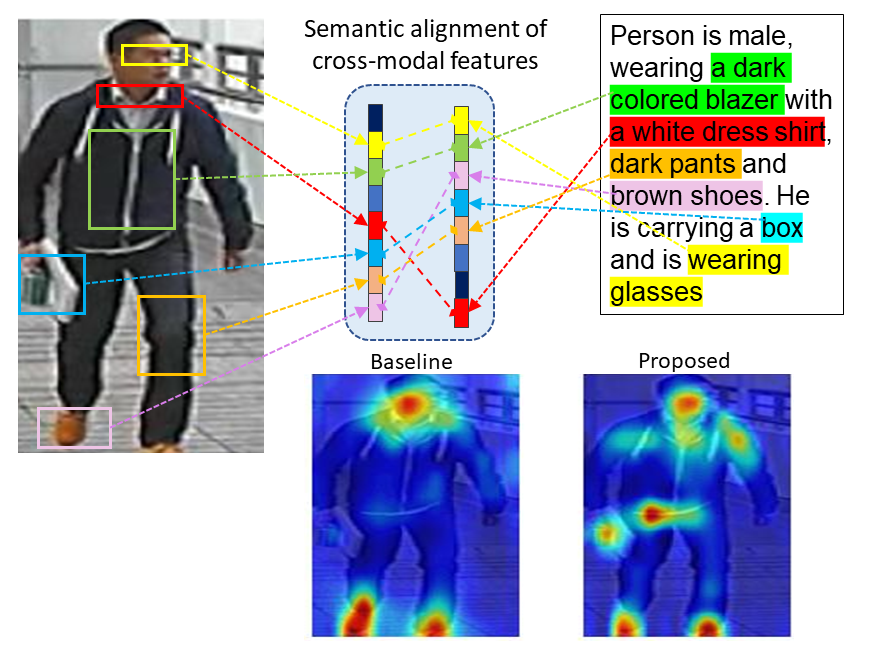
Cross-modal person re-identification (Re-ID) is critical for modern video surveillance systems. The key challenge is to align inter-modality representations according to semantic information present for a person and ignore background information. In this work, we present AXM-Net, a novel CNN based architecture designed for learning semantically aligned visual and textual representations. The underlying building block consists of multiple streams of feature maps coming from visual and textual modalities and a novel learnable context sharing semantic alignment network. We also propose complementary intra modal attention learning mechanisms to focus on more fine-grained local details in the features along with a cross-modal affinity loss for robust feature matching. Our design is unique in its ability to implicitly learn feature alignments from data. The entire AXM-Net can be trained in an end-to-end manner. We report results on both person search and cross-modal Re-ID tasks. Extensive experimentation validates the proposed framework and demonstrates its superiority by outperforming the current state-of-the-art methods by a significant margin.
翻译:现代视频监视系统的关键是跨式个人再识别(Re-ID),关键的挑战是如何根据一个人的语义信息调整不同模式的表达方式,忽略背景资料。在这项工作中,我们介绍了AXM-Net,这是一个以CNN为基础的新颖结构,旨在学习在语义上与视觉和文字上一致的表达方式。基本构件包括来自视觉和文字模式的多重特征地图流,以及一个新的可学习背景共享语义匹配网络。我们还提议了模式内补充性关注学习机制,以侧重于特征中更精细的本地细节,同时关注功能匹配的跨式亲和性损失。我们的设计是独特的,因为它能够隐含地从数据中学习特征的匹配。整个AXM-Net可以接受端对端培训。我们报告关于人搜索和跨式再开发任务的结果。广泛实验验证了拟议的框架,并通过显著的比照现有先进方法展示其优越性。