【行人识别】Deep Transfer Learning for Person Re-identification
Geng, Mengyue, et al. “Deep Transfer Learning for Person Re-identification.” arXiv preprint arXiv:1611.05244 (2016).
概述
本文解决行人的Re-Identification问题:判断两次出现的人是否是同一个人。在Market 1501竞赛中名列榜首,其Rank-1准确率比第二名高出约4%,和传统方法相比提升更是十分明显。
本文的亮点有三:
在网络结构方面,使用训练好的GoogleNet进行特征提取;同时使用Verification和Classification代价进行优化。
在训练时,分两步进行参数调优,使得小数据集的使用成为可能。
使用一种巧妙的非监督方法,利用未标定的大量视频数据。
网络结构
特征提取

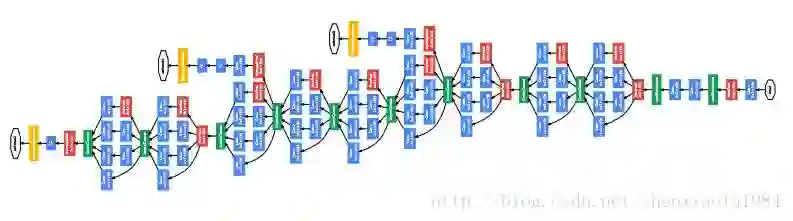
GoogleNet约有100层网络,其中由参数的只有22层(如果算pooling是27层),整体参数不超过10M。需要训练的参数少,也是作者选择GoogleNet的原因。
由于充分利用了大训练集上的预训练结果,本文的正确率比以往工作有了明显提升。
代价
同时考虑两个代价。
分类代价:将一个输入图像分类为已知的N个类别中的一类。

鉴别代价:判断两个图像是否为同一个人。特别注意,上下两路中的dropout层完全相同,保证略去的节点位置对应。
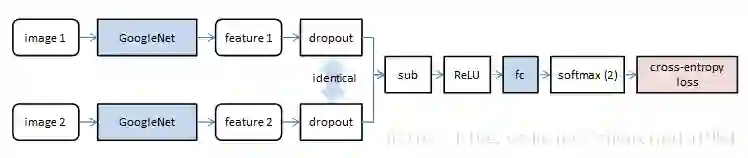
同时考虑两个代价,也是本文正确率高的原因之一。
需要特别声明的是,GoogleNet在不同阶段实际有三个输出。对这三个输出都同等地施加上述两个代价。
测试方法
在执行行人识别任务时,实际被利用的只有GoogleNet部分的网络。遵循如下规则。
预处理
计算所有gallery中人的特征
识别
对输入图像,计算其特征
与gallery中特征逐个比较,计算欧式距离
距离最小的,认定为识别结果
训练方法
监督学习
在监督学习场景下,数据库中的每个样本标定的人员身份。
初始化时,提取特征网络使用GoogleNet参数,softmax部分随机初始化。
训练分为两步完成:
固定其他参数,只训练softmax层
训练所有层参数
一个特别一点的情况是,用于训练的行人数据库有两个,一个包含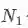
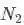
训练分为三步:
固定其他参数,在大库上训练输出为
的softmax层
固定其他参数,在小库上训练输出为
的softmax层
在小库上训练所有层参数
无监督学习
非监督学习场景下,人员身份未标定,但能够区分图像是否来自不同摄像机。为简洁起见,设有两个摄像机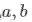
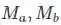
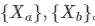
经过特征网络提取的特征记为
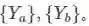
co-training
co-training方法可以从未标定的数据集中训练出监督模型。简略地表示如下:
设计两个具有互补性质的模型;
用模型1的结果,标定所有数据;
用当前数据训练模型2
用模型2的结果,标定所有数据;
重复上述过程2-3次即完成拟合
模型1
使用如下方式标定无监督数据


中的最近邻,将其标定位该最近邻的类别。
使用如上标记数据,更新网络参数。
注意,网络参数变化后,标定结果也会发生变化。
模型2

两个摄像机共拍摄了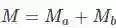
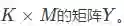
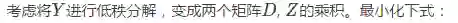
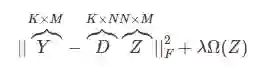

其中,第一项是Frobenious范数,定义为矩阵元素平方和的方根。
第二项是graph regularization,定义为:
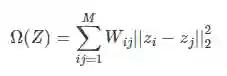

如果第i列和第j列对应的样本来自同一个摄像机,则权重
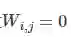
否则,设i来自相机ɑ,j来自相机b,查找i在b

这一项的意义是,要求新的表达z具有邻近特性。如果两个样本相似,则要求其表达也接近。
graph regularization求解
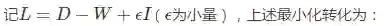
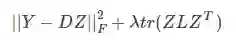

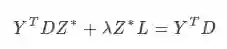
这是一个Sylvester等式,可以使用Bartels-Stewart算法求解,该方法在LAPACK中提供了实现。
数据组织
由于网络包含分类代价,类别数量不同会导致网络结构变化。所以使用如下方法构造minibatch:
每一次迭代,随机选择32个人
每个人,随机选择2个样本。每次将这64个样本载入GPU,构成一个minibatch。
生成所有“不同人”样本对,共2*32*2*31 = 3968对。
生成所有“相同人”样本对,并随机复制为同样数量的3968对2。
训练超参数
学习率:输出0.001,每40K迭代乘0.1
迭代数:直接使用大库的迭代数为40K/150K;从大库迁移到小库的迭代数为20K/20K/20K。
代价权重:verification和classification的权重比为3:1
co-training:
数据扩展:每个原始样本保持中心做随机2D变换,扩展为5个。
总结
实验部分十分丰富,此处只介绍结论。
使用在一般数据库上训练的GoogleNet,大大提升了了准确率,超出第二名约10%;
使用classfication+verification的复合损失,比单独损失提升准确率7%-9%,添加triplet loss不能提升准确率;
在verification中使用统一的dropout提升准确率3%;
分两步fine-tune提升准确率8.7%;
非监督方法比原有方法提升显著,准确率约在40%-60%;
非监督方法中的co-training提升准确率2%-3%;
使用在ImageNet上预训练的特征提取网络,能够值得提取的特征更具有“目标”语义。

Szegedy, Christian, et al. “Going deeper with convolutions.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.
此处待详。
经授权转自CSDNshenxiaolu1984的专栏,查看原文请点击阅读原文。
文章推荐:
论文笔记——CVPR 2017 Annotating Object Instances with a Polygon-RNN
CVPR 2017论文笔记— Dilated Residual Networks
PS. 如有想加入极市专业CV开发者微信群,请填写申请表(链接:http://cn.mikecrm.com/wcotd9)申请入群~




