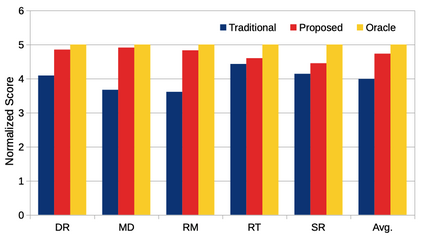
Instrument separation in an ensemble is a challenging task. In this work, we address the problem of separating the percussive voices in the taniavartanam segments of Carnatic music. In taniavartanam, a number of percussive instruments play together or in tandem. Separation of instruments in regions where only one percussion is present leads to interference and artifacts at the output, as source separation algorithms assume the presence of multiple percussive voices throughout the audio segment. We prevent this by first subjecting the taniavartanam to diarization. This process results in homogeneous clusters consisting of segments of either a single voice or multiple voices. A cluster of segments with multiple voices is identified using the Gaussian mixture model (GMM), which is then subjected to source separation. A deep recurrent neural network (DRNN) based approach is used to separate the multiple instrument segments. The effectiveness of the proposed system is evaluated on a standard Carnatic music dataset. The proposed approach provides close-to-oracle performance for non-overlapping segments and a significant improvement over traditional separation schemes.
翻译:将乐器分成一个组合是一个具有挑战性的任务。 在这项工作中,我们处理将卡纳蒂音乐的 taniavartanam 部分的震动声音分开的问题。 在 taniavartanam 中, 有一些震动仪器一起或一起运行。 在只有一次震动的区域, 仪器分离导致产出受到干扰和人工制品, 因为源分离算法假定整个音频段存在多重震动声音。 我们通过首先将taniavartanam 进行对称来阻止这一点。 这一过程的结果是, 由单一声音或多个声音组成的各部分形成一个单一的集群。 一组具有多个声音的部件使用高斯混合混合物模型( GMM)来识别, 后来进行源分离。 一种基于深层经常性神经网络( DRNNN) 的方法用来分离多个乐器段。 提议的系统的有效性是通过标准的卡纳蒂音乐数据集来评估的。 提议的方法为非重叠部分提供近触波和显著改进传统分离计划。