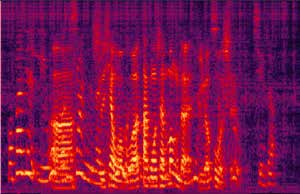
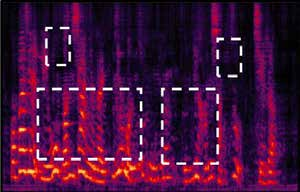
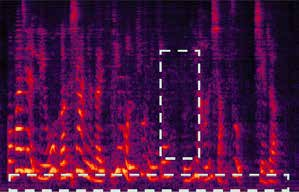
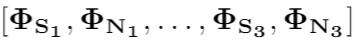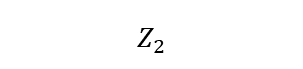Recently, our proposed recurrent neural network (RNN) based all deep learning minimum variance distortionless response (ADL-MVDR) beamformer method yielded superior performance over the conventional MVDR by replacing the matrix inversion and eigenvalue decomposition with two recurrent neural networks. In this work, we present a self-attentive RNN beamformer to further improve our previous RNN-based beamformer by leveraging on the powerful modeling capability of self-attention. Temporal-spatial self-attention module is proposed to better learn the beamforming weights from the speech and noise spatial covariance matrices. The temporal self-attention module could help RNN to learn global statistics of covariance matrices. The spatial self-attention module is designed to attend on the cross-channel correlation in the covariance matrices. Furthermore, a multi-channel input with multi-speaker directional features and multi-speaker speech separation outputs (MIMO) model is developed to improve the inference efficiency. The evaluations demonstrate that our proposed MIMO self-attentive RNN beamformer improves both the automatic speech recognition (ASR) accuracy and the perceptual estimation of speech quality (PESQ) against prior arts.
翻译:最近,我们提议的基于所有深度学习最低差异扭曲反应(ADL-MVDR-MVDR)的经常性神经网络(RNN)基于所有深层次学习最低差异扭曲反应(ADL-MVDR)光谱法,通过用两个经常性神经网络取代矩阵反转和半值分解,取得了优于常规MVDR的性能。在这项工作中,我们提出了一个自我强化的RNNN光谱,以便通过利用强大的自我注意示范能力来进一步改进我们以前的RNNN的光谱。提出了时空空间自控模块,以更好地从语音和噪音空间变异矩阵中学习光成形重量。时间自留模块可以帮助RNNNN学习关于共变矩阵的全球统计数据。空间自留模块旨在关注共变矩阵中的跨通道关联性。此外,还开发了一个多频导方向特征和多频调语音分离输出(IMIMO)的多频道输入模型,以提高推论效率。评价表明,我们提议的MIMO 自我强化语音和超频语音预估(RNNPESA)的自动识别)改进了发言质量。