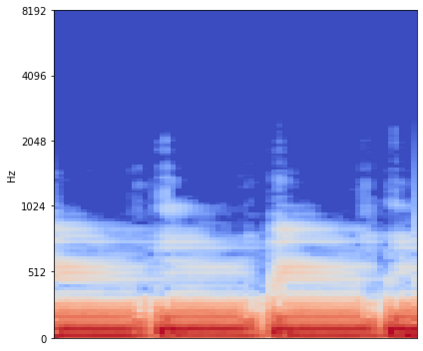
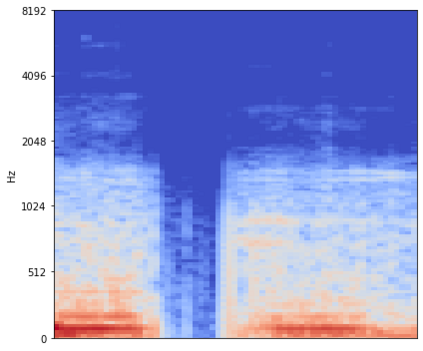
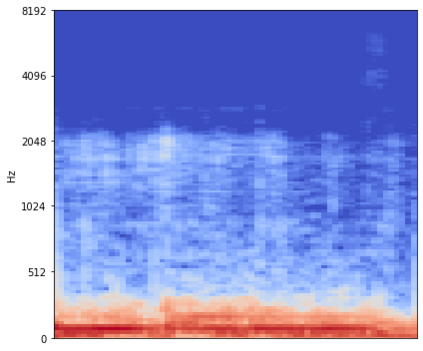
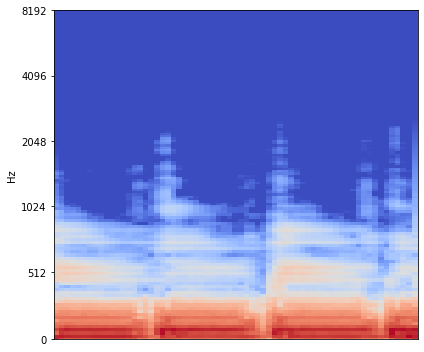
Source separation for music is the task of isolating contributions, or stems, from different instruments recorded individually and arranged together to form a song. Such components include voice, bass, drums and any other accompaniments.Contrarily to many audio synthesis tasks where the best performances are achieved by models that directly generate the waveform, the state-of-the-art in source separation for music is to compute masks on the magnitude spectrum. In this paper, we compare two waveform domain architectures. We first adapt Conv-Tasnet, initially developed for speech source separation,to the task of music source separation. While Conv-Tasnet beats many existing spectrogram-domain methods, it suffersfrom significant artifacts, as shown by human evaluations. We propose instead Demucs, a novel waveform-to-waveform model,with a U-Net structure and bidirectional LSTM.Experiments on the MusDB dataset show that, with proper data augmentation, Demucs beats allexisting state-of-the-art architectures, including Conv-Tasnet, with 6.3 SDR on average, (and up to 6.8 with 150 extra training songs, even surpassing the IRM oracle for the bass source).Using recent development in model quantization, Demucs can be compressed down to 120MBwithout any loss of accuracy.We also provide human evaluations, showing that Demucs benefit from a large advantagein terms of the naturalness of the audio. However, it suffers from some bleeding,especially between the vocals and other source.
翻译:音乐源的分离是分离贡献的任务, 或者从单个记录的不同乐器中分离出来, 并排列成歌。 这些组件包括声音、 低音、 鼓和其他任何伴奏。 这些组件包括声音、 低音、 鼓和任何其他伴奏。 在很多音频合成任务中, 直接产生波形的模型能取得最佳的性能。 我们提议代之以Demucs, 一种新型波形到波形的波形模型, 其U- Net 结构和双向LSTM。 本文中, 我们比较了两个波形域结构。 我们首先将Conv- Tasnet, 最初为语言源分离而开发的Conv- Tasnet 与音乐源分离的任务相匹配。 虽然Conv- Tasnet 击败了许多现有的音频谱- 法方法, 但正如人类评价所示, 它受了重要艺术合成的作品。 我们建议的是, 一个全新的波形到波形模型结构, 其从适当的数据增益, Demucs 将比所有现存的艺术结构结构结构,, 甚至Tasnet- dismetrinet, rualal dealalalalal deal dexal disal dreal debles, exal dexal dexal disl dism sreal sal sal sal be lexm sm sal sal sal bes, ex, lexm sal divation, lexmal sal sal sal sal sal divation, ex sal bes.