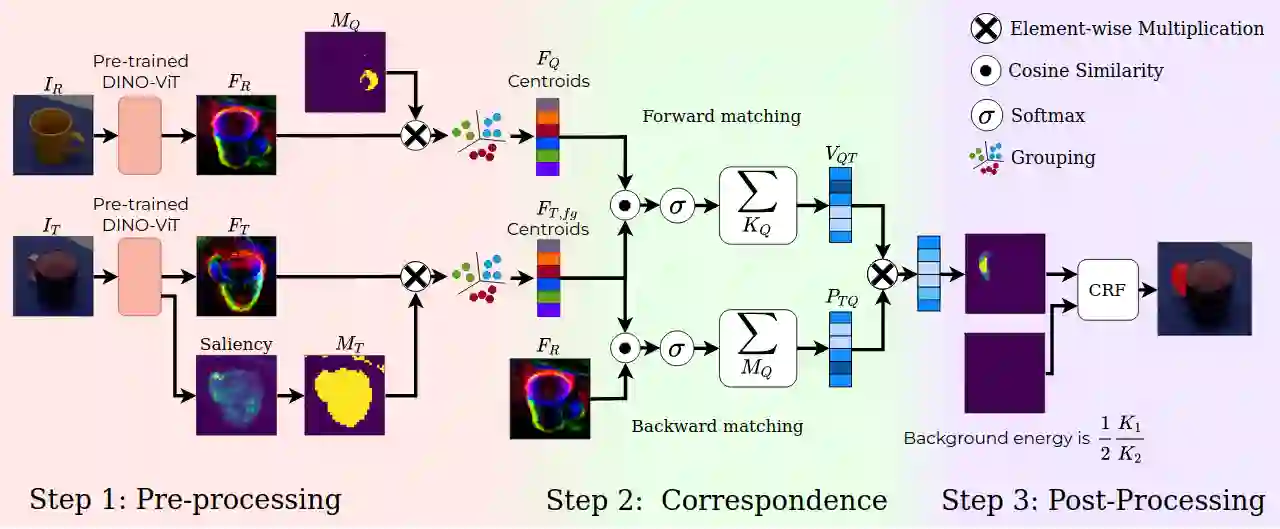
In this work, we tackle one-shot visual search of object parts. Given a single reference image of an object with annotated affordance regions, we segment semantically corresponding parts within a target scene. We propose AffCorrs, an unsupervised model that combines the properties of pre-trained DINO-ViT's image descriptors and cyclic correspondences. We use AffCorrs to find corresponding affordances both for intra- and inter-class one-shot part segmentation. This task is more difficult than supervised alternatives, but enables future work such as learning affordances via imitation and assisted teleoperation.
翻译:在这项工作中,我们处理对对象部件的一次性直观搜索。根据一个带有附加说明的附加说明的区域的物体的单一参考图像,我们在目标场景中将相应的部分分开。我们提出AffCorrs,这是一个未经监督的模型,将预先训练的DINO-ViT图像描述仪和周期性通信的特性结合起来。我们使用AffCorrs为分类内和分类间单向部分的分割找到相应的附加说明。这项任务比监督的替代方法更困难,但能够进行未来的工作,例如通过模仿和辅助电话操作学习支付能力。