
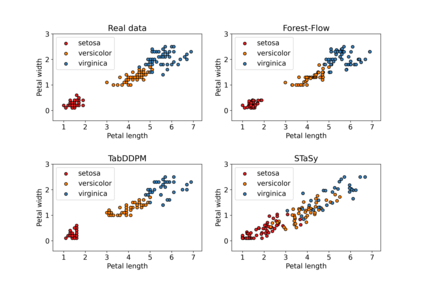
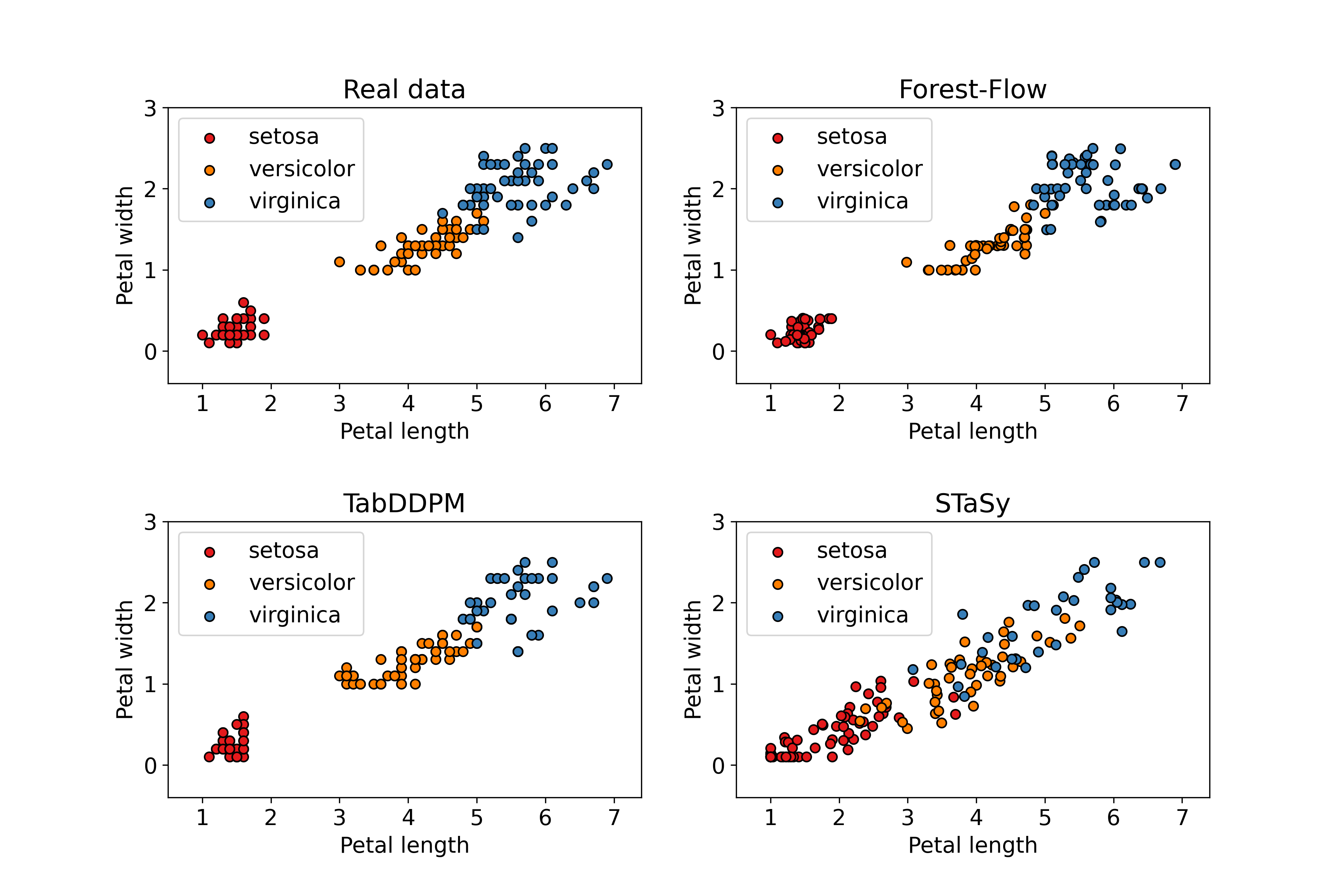
Tabular data is hard to acquire and is subject to missing values. This paper proposes a novel approach to generate and impute mixed-type (continuous and categorical) tabular data using score-based diffusion and conditional flow matching. Contrary to previous work that relies on neural networks as function approximators, we instead utilize XGBoost, a popular Gradient-Boosted Tree (GBT) method. In addition to being elegant, we empirically show on various datasets that our method i) generates highly realistic synthetic data when the training dataset is either clean or tainted by missing data and ii) generates diverse plausible data imputations. Our method often outperforms deep-learning generation methods and can trained in parallel using CPUs without the need for a GPU. To make it easily accessible, we release our code through a Python library on PyPI and an R package on CRAN.
翻译:暂无翻译
相关内容

Source: Apple - iOS 8



