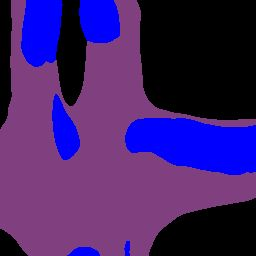
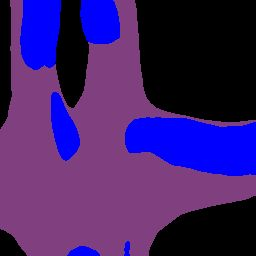
Efficient reasoning about the semantic, spatial, and temporal structure of a scene is a crucial prerequisite for autonomous driving. We present NEural ATtention fields (NEAT), a novel representation that enables such reasoning for end-to-end imitation learning models. NEAT is a continuous function which maps locations in Bird's Eye View (BEV) scene coordinates to waypoints and semantics, using intermediate attention maps to iteratively compress high-dimensional 2D image features into a compact representation. This allows our model to selectively attend to relevant regions in the input while ignoring information irrelevant to the driving task, effectively associating the images with the BEV representation. In a new evaluation setting involving adverse environmental conditions and challenging scenarios, NEAT outperforms several strong baselines and achieves driving scores on par with the privileged CARLA expert used to generate its training data. Furthermore, visualizing the attention maps for models with NEAT intermediate representations provides improved interpretability.
翻译:关于场景的语义、空间和时间结构的有效推理是自主驾驶的关键先决条件。 我们展示了神经感应场(NEAT),这是一个新型的表述方式,使得能够对端到端的模拟学习模型进行这种推理。 NEAT是一个连续的功能,用来绘制鸟类眼观(BEV)场景的位置,用中间注意的地图将路标和语义坐标定位到路标和语义,将迭代压缩高维2D图像特征的图案转换成一个紧凑的表示方式。这使我们的模型能够有选择地在输入中关注相关区域,同时忽略与驱动任务无关的信息,有效地将图像与BEV代表方式联系起来。在涉及不利环境条件和具有挑战性情景的新评价环境中,NEAT超越了几个强有力的基线,并实现了与用来生成其培训数据的特许CARLA专家相同的驱动分数。此外,将模型的注意度图与NEAT中间表述方式的图解性提供了改进。