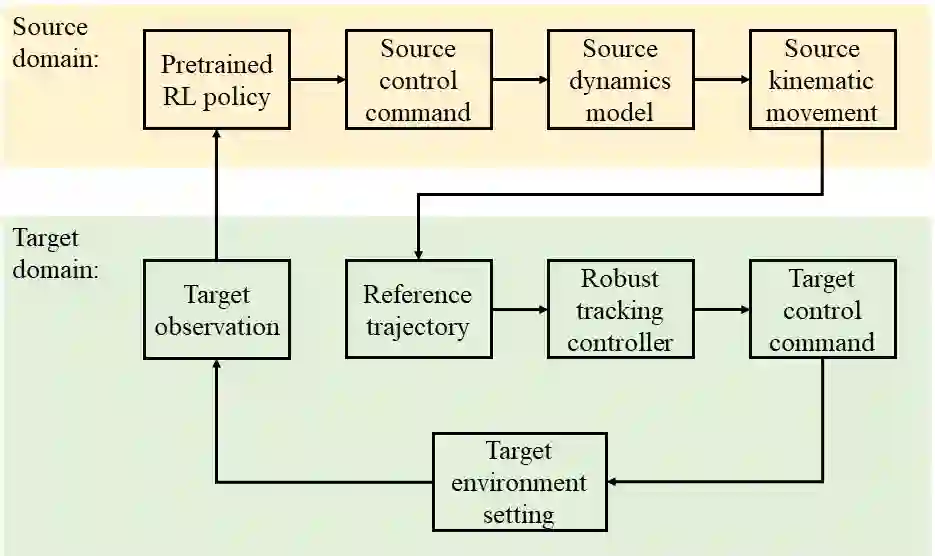
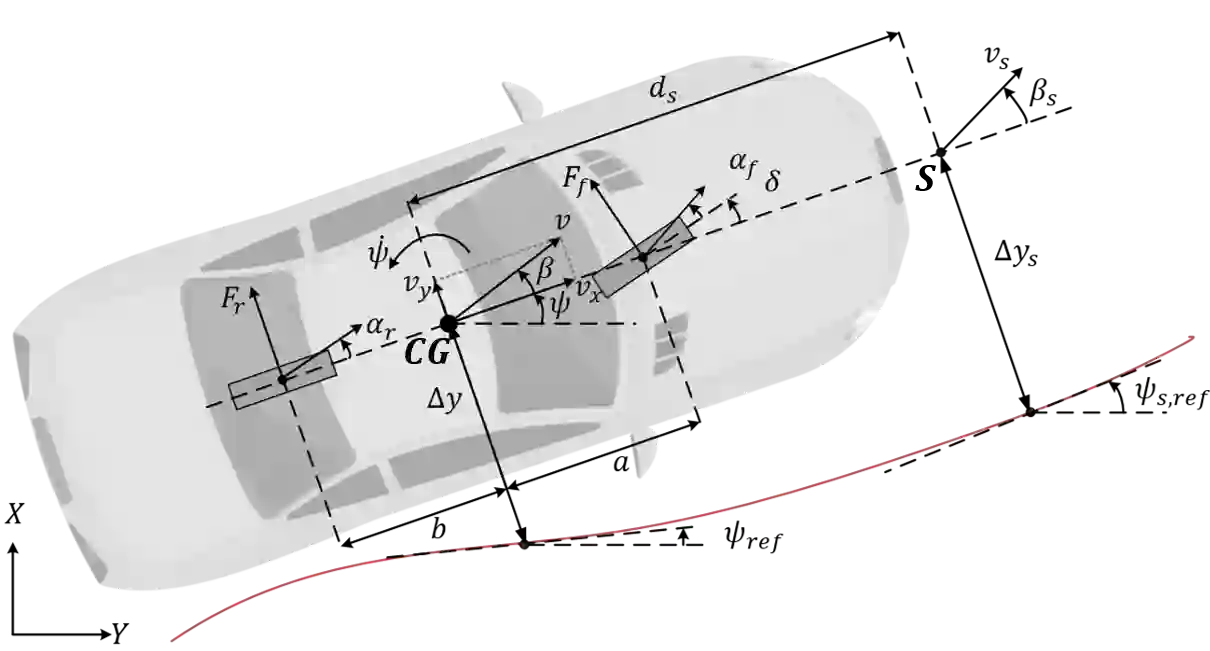
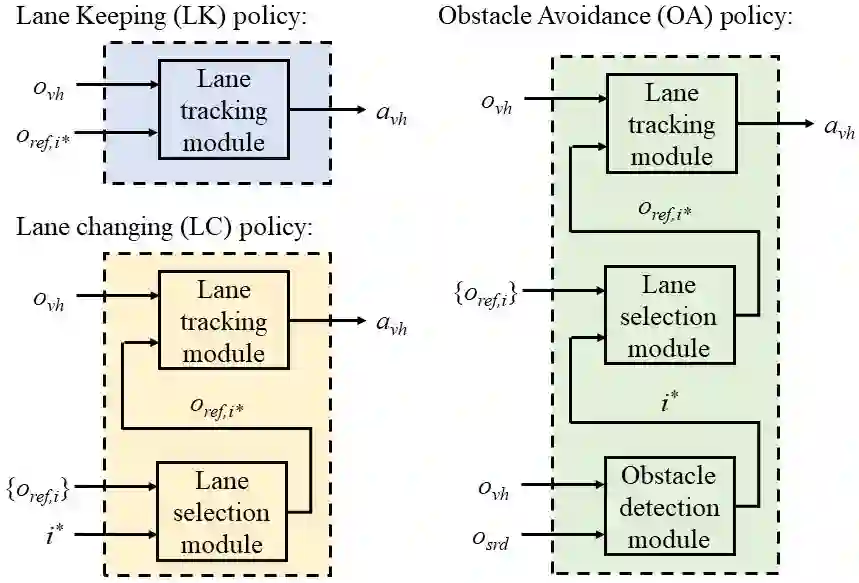
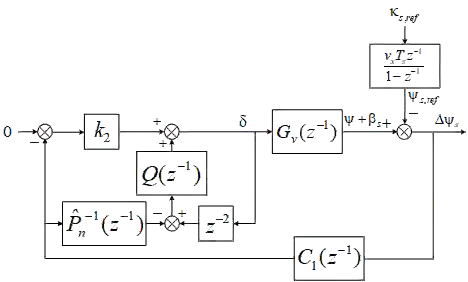
Although deep reinforcement learning (deep RL) methods have lots of strengths that are favorable if applied to autonomous driving, real deep RL applications in autonomous driving have been slowed down by the modeling gap between the source (training) domain and the target (deployment) domain. Unlike current policy transfer approaches, which generally limit to the usage of uninterpretable neural network representations as the transferred features, we propose to transfer concrete kinematic quantities in autonomous driving. The proposed robust-control-based (RC) generic transfer architecture, which we call RL-RC, incorporates a transferable hierarchical RL trajectory planner and a robust tracking controller based on disturbance observer (DOB). The deep RL policies trained with known nominal dynamics model are transfered directly to the target domain, DOB-based robust tracking control is applied to tackle the modeling gap including the vehicle dynamics errors and the external disturbances such as side forces. We provide simulations validating the capability of the proposed method to achieve zero-shot transfer across multiple driving scenarios such as lane keeping, lane changing and obstacle avoidance.
翻译:虽然深强化学习(深RL)方法有许多优点,如果适用于自主驾驶,则这些办法具有许多优点,但是,由于源(培训)域和目标(部署)域之间的建模差距,自动驾驶的实际深RL应用程序因源(培训)域和目标(部署)域之间的建模差距而放慢。与目前的政策转移办法不同,目前的政策转移办法通常限制使用无法解释的神经网络表示方式作为转移的特征,我们提议在自主驾驶中转让混凝土运动量。我们称之为RL-RC的基于稳健控制的通用转移结构(RC)包括一个可转移的RL轨迹规划仪和一个基于扰动观察员(DOB)的强力跟踪控制器。用已知名义动态模型模型模型模型模型培训的深RL政策直接转移到目标域,以DOB为基础的强力跟踪控制用于解决模型差距,包括车辆动态误差和侧力等外部扰动。我们模拟了拟议方法在诸如车道保持、航道改变和障碍避免等多种驱动情景下实现零发式转移的能力。