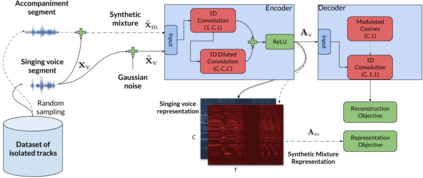
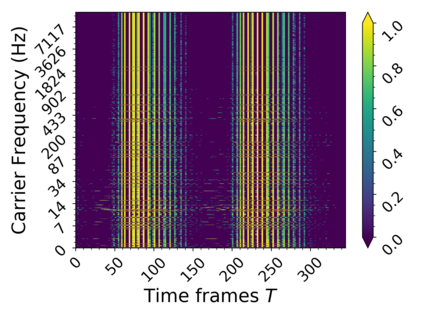
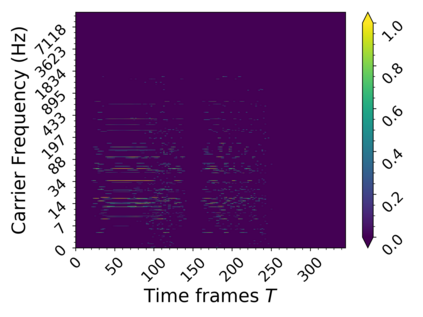
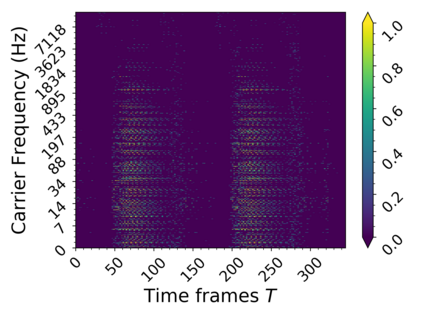
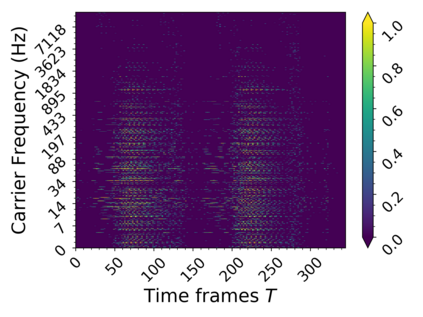
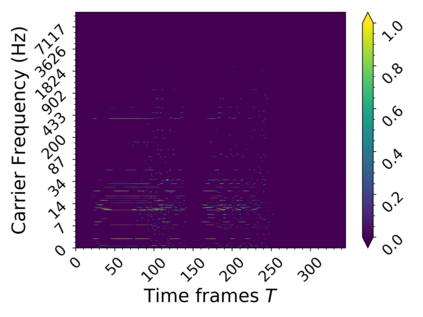
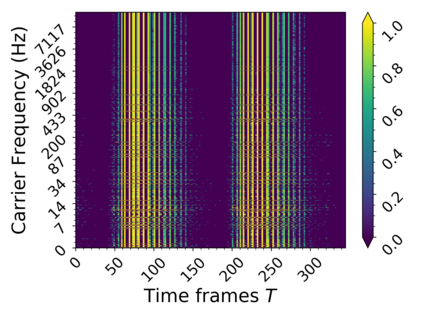
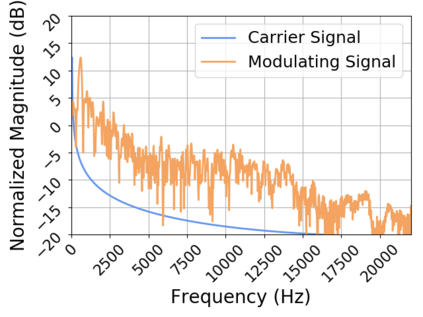
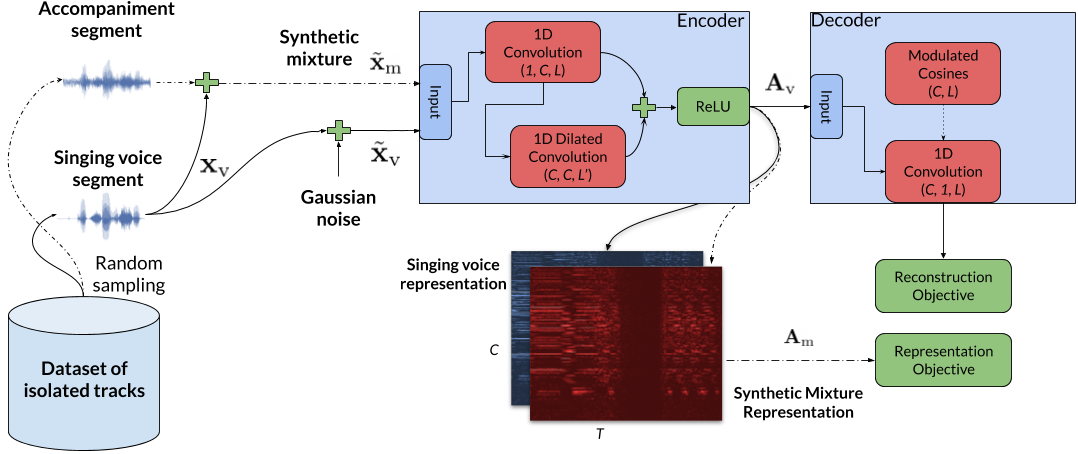
In this work we present a method for unsupervised learning of audio representations, focused on the task of singing voice separation. We build upon a previously proposed method for learning representations of time-domain music signals with a re-parameterized denoising autoencoder, extending it by using the family of Sinkhorn distances with entropic regularization. We evaluate our method on the freely available MUSDB18 dataset of professionally produced music recordings, and our results show that Sinkhorn distances with small strength of entropic regularization are marginally improving the performance of informed singing voice separation. By increasing the strength of the entropic regularization, the learned representations of the mixture signal consists of almost perfectly additive and distinctly structured sources.
翻译:在这项工作中,我们提出了一个不受监督地学习音频演示的方法,重点是歌声分离的任务;我们以先前提出的一种方法为基础,学习时间区音乐信号的演示,同时使用重新校正的去硝化自动编码器,通过使用Sinkhorn距离的家庭和昆虫正规化加以扩展;我们评估了我们关于专业制作的音乐录音可免费获得的MUSDB18数据集的方法;我们的结果显示,带有微弱的昆虫调频,其微弱强度使有意识的歌声分离的性能稍有改进。通过增强昆虫正规化的强度,混合信号的学术表达由几乎完全的添加和结构分明的来源组成。