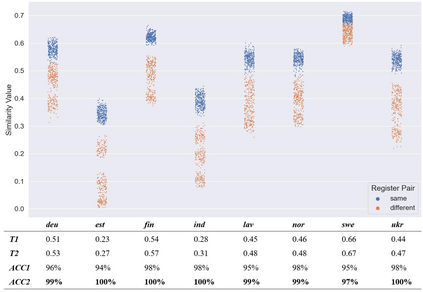
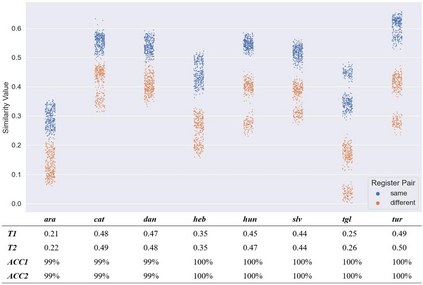
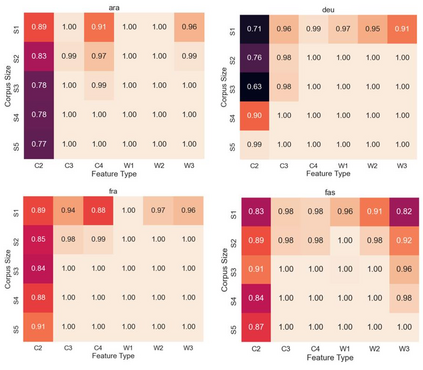
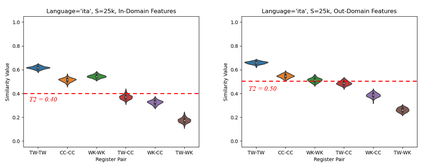
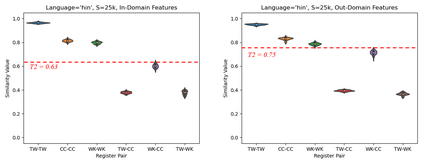
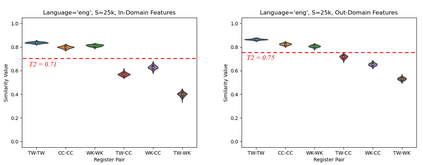
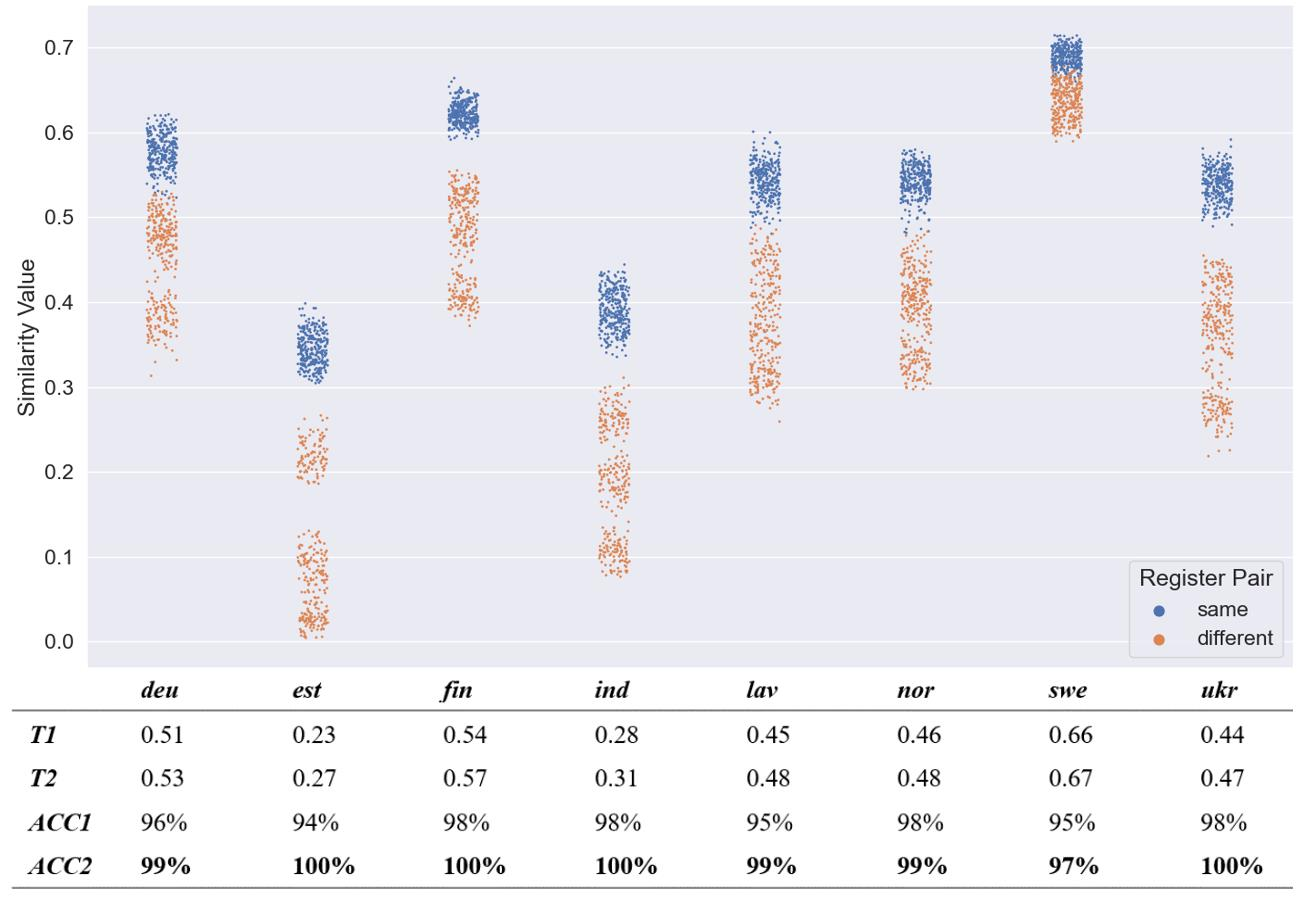
This paper experiments with frequency-based corpus similarity measures across 39 languages using a register prediction task. The goal is to quantify (i) the distance between different corpora from the same language and (ii) the homogeneity of individual corpora. Both of these goals are essential for measuring how well corpus-based linguistic analysis generalizes from one dataset to another. The problem is that previous work has focused on Indo-European languages, raising the question of whether these measures are able to provide robust generalizations across diverse languages. This paper uses a register prediction task to evaluate competing measures across 39 languages: how well are they able to distinguish between corpora representing different contexts of production? Each experiment compares three corpora from a single language, with the same three digital registers shared across all languages: social media, web pages, and Wikipedia. Results show that measures of corpus similarity retain their validity across different language families, writing systems, and types of morphology. Further, the measures remain robust when evaluated on out-of-domain corpora, when applied to low-resource languages, and when applied to different sets of registers. These findings are significant given our need to make generalizations across the rapidly increasing number of corpora available for analysis.
翻译:使用登记预测任务,用39种语言进行基于频率的实验,对39种语言进行基于频谱的类似措施。目的是量化(一) 不同团体与同一语言之间的距离,和(二) 个体团体的同质性。这两个目标对于衡量基于实体的语言分析如何从一个数据集向另一个数据集的概括性至关重要。问题在于,先前的工作侧重于印欧语言,提出了这些措施是否能够在多种语言之间提供强有力的概括性的问题。本文使用登记预测任务来评估39种语言的相竞措施:它们能够如何区分代表不同生产背景的社团?每个实验都比较了三种单一语言的社团,而所有语言共有三个相同的数字登记册:社交媒体、网页和维基百科。结果显示,在对不同语言家庭、书写系统和形态学类型进行类似措施的有效性。此外,在对外部社团进行评价时,这些措施仍然很健全,用于低资源语言,以及用于不同登记册时,这些措施如何区分?这些结果对单一语言的三个社团进行了比较,而三个数字登记册是共享的:社交媒体、网页和维基百科。结果显示,不同语言的类似措施仍然有效。我们迅速进行总体分析需要。