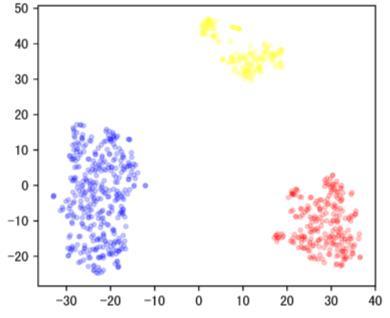
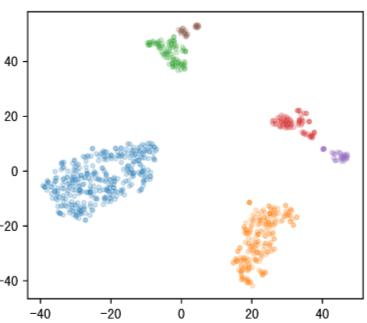
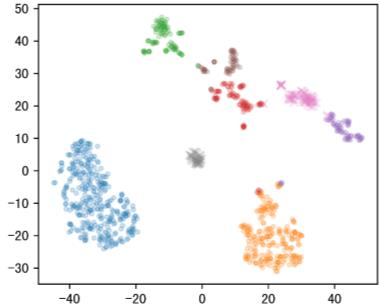
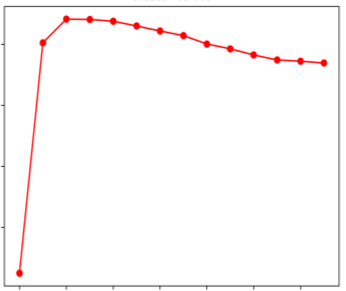
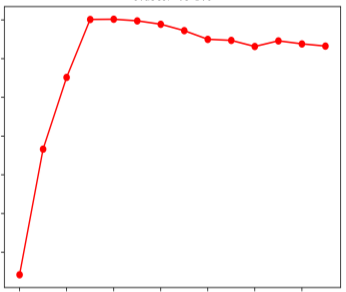
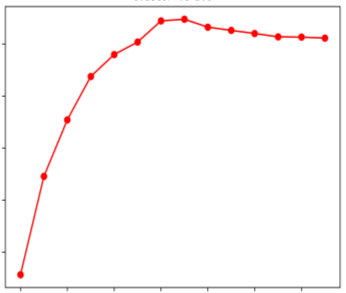
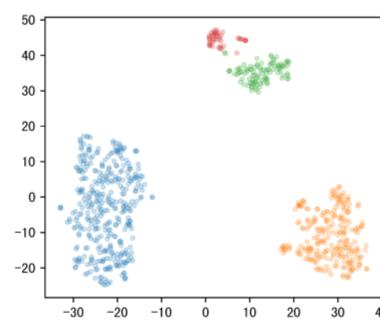
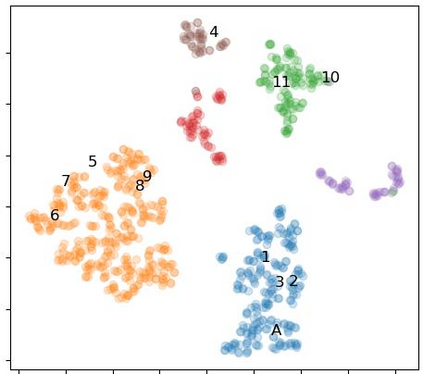
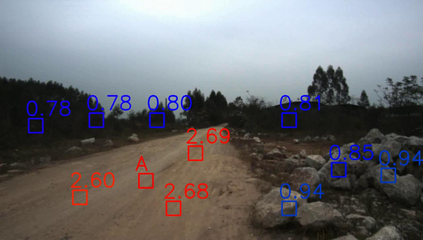
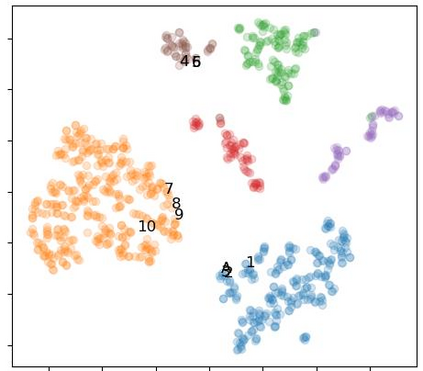
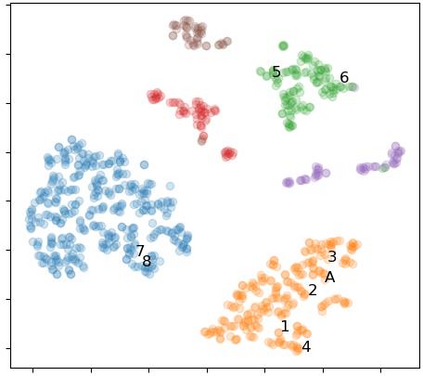
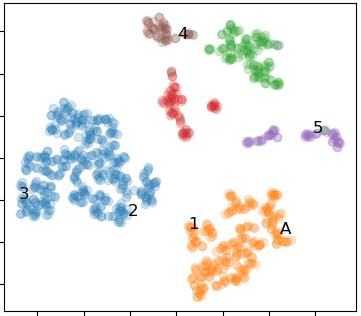
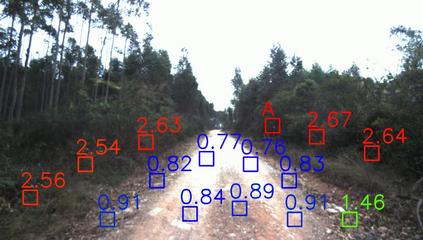
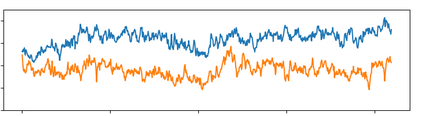
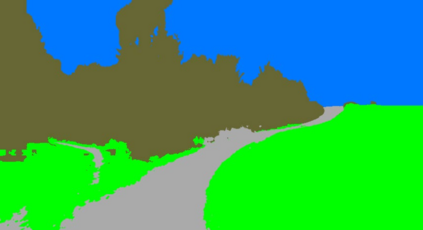
Off-road semantic segmentation with fine-grained labels is necessary for autonomous vehicles to understand driving scenes, as the coarse-grained road detection can not satisfy off-road vehicles with various mechanical properties. Fine-grained semantic segmentation in off-road scenes usually has no unified category definition due to ambiguous nature environments, and the cost of pixel-wise labeling is extremely high. Furthermore, semantic properties of off-road scenes can be very changeable due to various precipitations, temperature, defoliation, etc. To address these challenges, this research proposes an active and contrastive learning-based method that does not rely on pixel-wise labels, but only on patch-based weak annotations for model learning. There is no need for predefined semantic categories, the contrastive learning-based feature representation and adaptive clustering will discover the category model from scene data. In order to actively adapt to new scenes, a risk evaluation method is proposed to discover and select hard frames with high-risk predictions for supplemental labeling, so as to update the model efficiently. Experiments conducted on our self-developed off-road dataset and DeepScene dataset demonstrate that fine-grained semantic segmentation can be learned with only dozens of weakly labeled frames, and the model can efficiently adapt across scenes by weak supervision, while achieving almost the same level of performance as typical fully supervised baselines.
翻译:使用细微标记的自动车辆必须了解驾驶场景,因为粗糙的测深路面无法用各种机械性能满足越野车辆,因此,独立车辆必须了解驾驶场景,因为粗糙的测深路面无法用各种机械性能满足越野车辆。由于性质环境模糊,在越野场面的精细测析分解通常没有统一的分类定义,而像素标签的成本极高。此外,由于降水、温度和脱色等各种降水,越野场景的语义特性可能非常可变。为了应对这些挑战,本研究提出了一种积极和反差的典型学习法,不依赖像素标签,而只依靠基于补丁基的薄弱说明进行模型学习。不需要预先界定的语义性能分类,反差的学习特征表和适应性组合将从现场数据中找到分类模型模型模型。为了积极适应新场景,建议采用一种风险评估方法发现和选择带有高风险预测的硬框来补充标签,以便有效地更新模型。在几乎按像素的标签性标定的模型上进行实验,而只是用我们自己所学会的低级的基线化的模型,然后才能进行自我测试,然后才能进行自我研判析地展示,然后才能进行自我研判析制数据,然后才能进行自我研订制,然后才能进行自我研订制,然后才能在深度制的深制的基底制的基底部制数据。