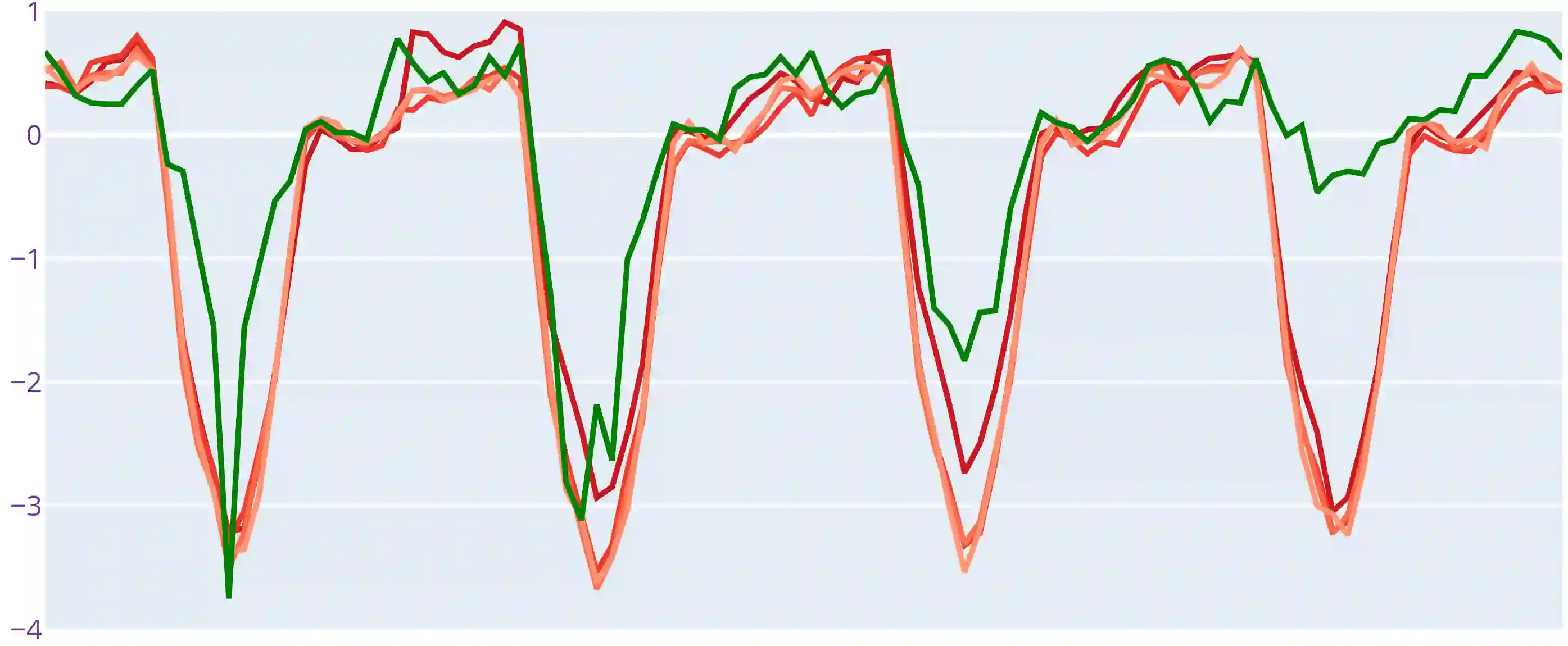
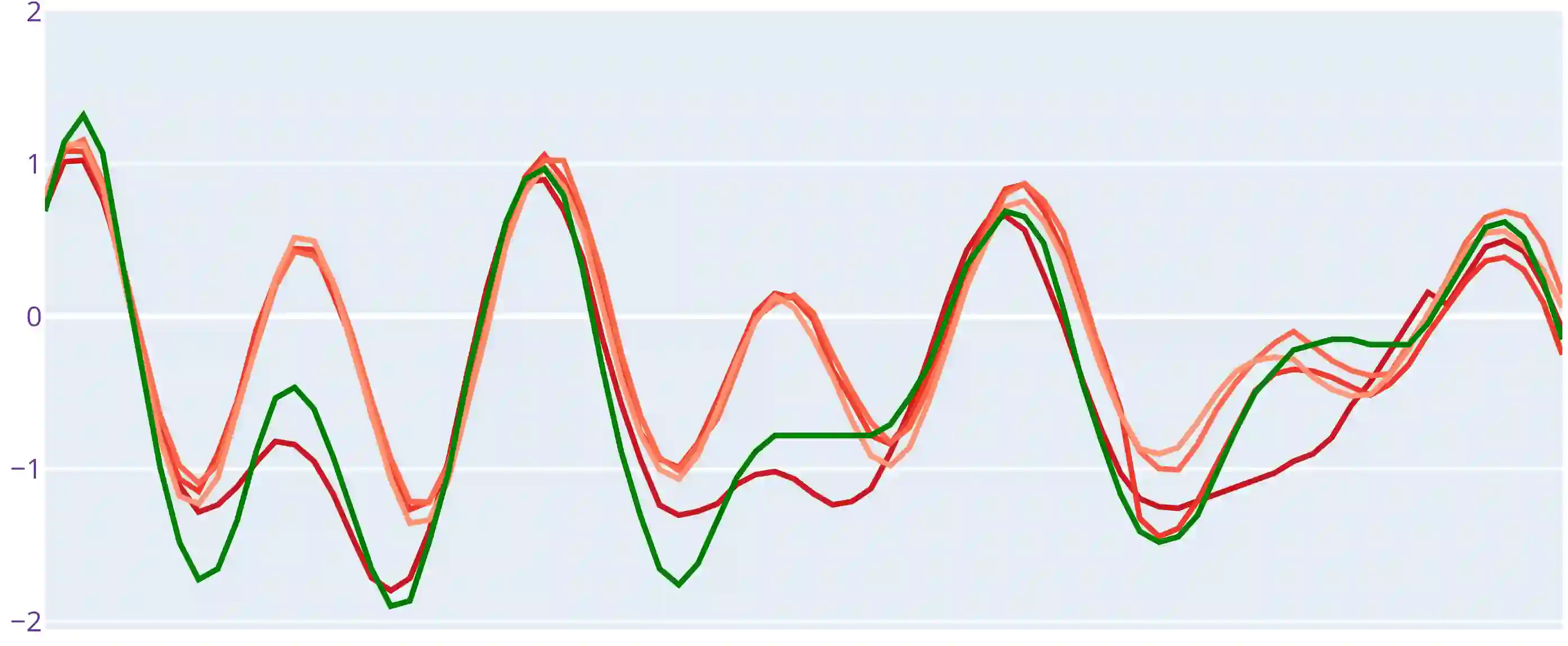
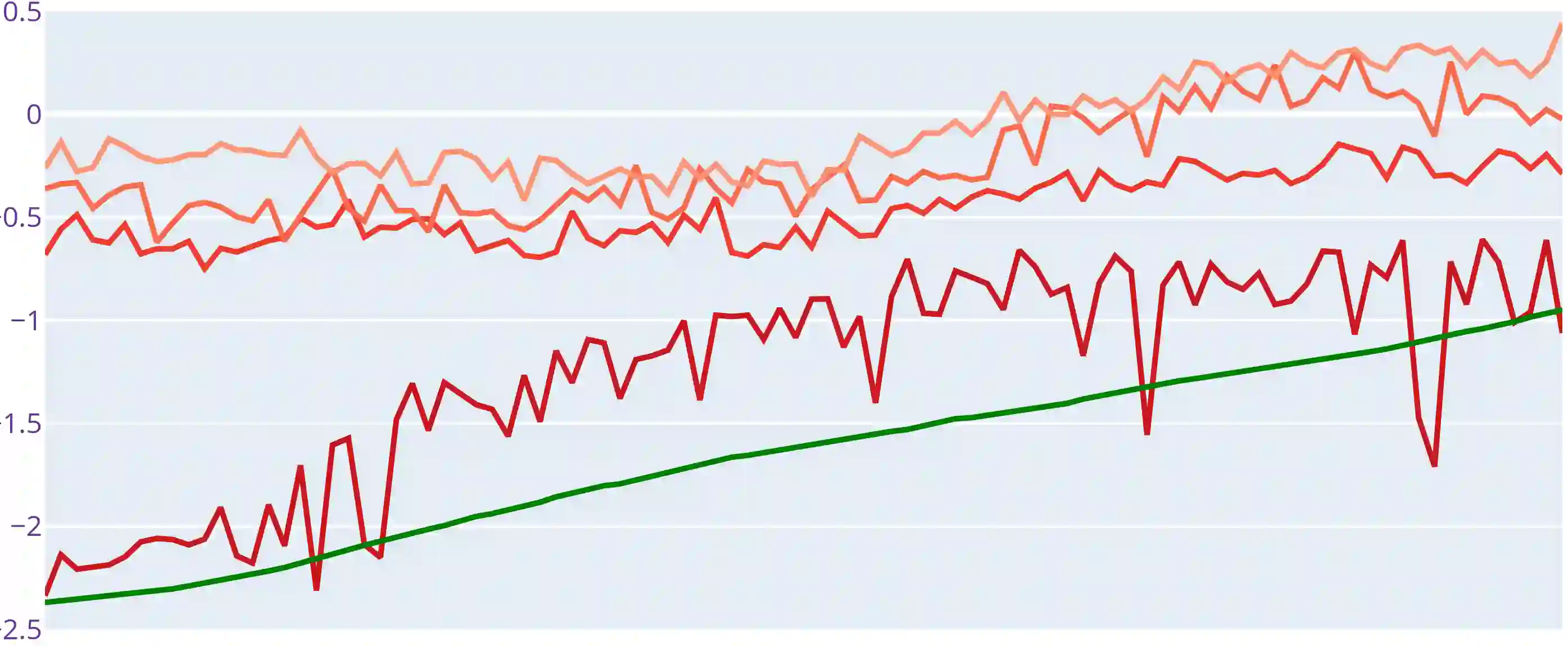
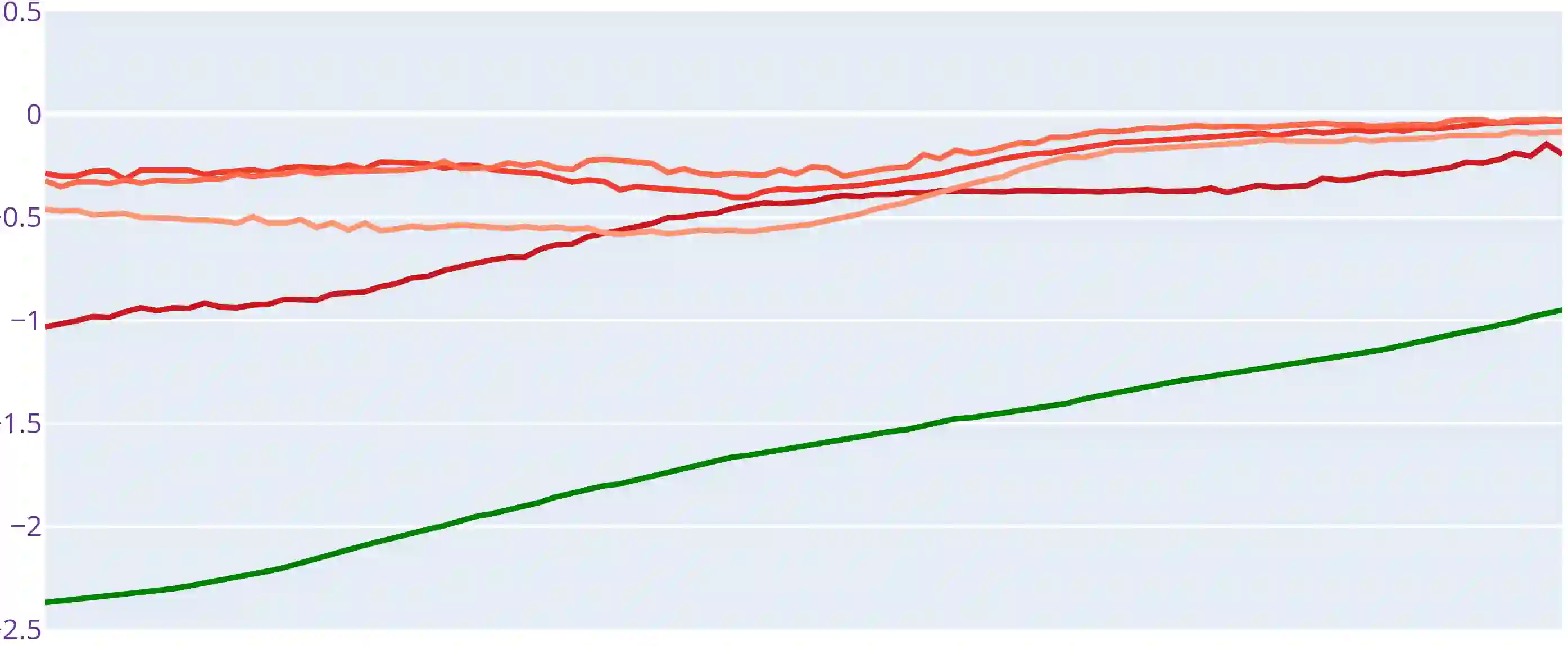
The Transformer is a highly successful deep learning model that has revolutionised the world of artificial neural networks, first in natural language processing and later in computer vision. This model is based on the attention mechanism and is able to capture complex semantic relationships between a variety of patterns present in the input data. Precisely because of these characteristics, the Transformer has recently been exploited for time series forecasting problems, assuming a natural adaptability to the domain of continuous numerical series. Despite the acclaimed results in the literature, some works have raised doubts about the robustness and effectiveness of this approach. In this paper, we further investigate the effectiveness of Transformer-based models applied to the domain of time series forecasting, demonstrate their limitations, and propose a set of alternative models that are better performing and significantly less complex. In particular, we empirically show how simplifying Transformer-based forecasting models almost always leads to an improvement, reaching state of the art performance. We also propose shallow models without the attention mechanism, which compete with the overall state of the art in long time series forecasting, and demonstrate their ability to accurately predict time series over extremely long windows. From a methodological perspective, we show how it is always necessary to use a simple baseline to verify the effectiveness of proposed models, and finally, we conclude the paper with a reflection on recent research paths and the opportunity to follow trends and hypes even where it may not be necessary.
翻译:暂无翻译