6 月 18 日至 22 日,计算机视觉领域顶级盛会之一国际计算机视觉与模式识别会议(CVPR 2023)将在加拿大温哥华举行。CVPR(Computer Vision and Pattern Recognition,计算机视觉与模式识别)会议是计算机视觉与模式识别、人工智能领域的国际顶级会议,是中国计算机学会(CCF)推荐的A类国际学术会议。本届会议录用率为25.78%。
来自Tel Aviv University, Google,Hugging Face给出了《视觉中的理解和解释注意力》教程,值得关注!

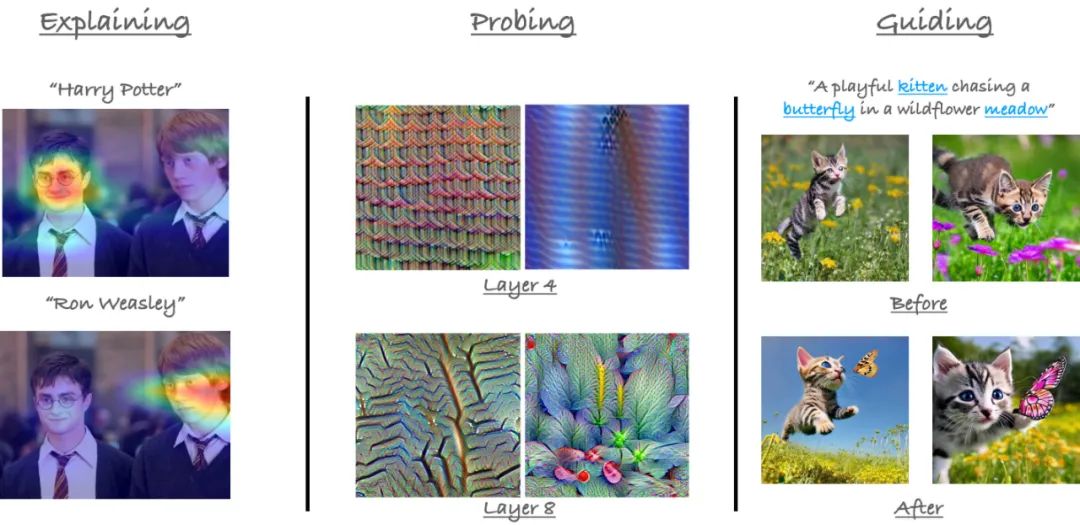
在这个教程中,我们探讨了在视觉中使用注意力的方法。从左到右:(i) 注意力可以用来解释模型的预测(例如,对于图像-文本对的CLIP)(ii) 探测基于注意力模型的示例 (iii) 多模态模型的交叉注意力图可以用来指导生成模型(例如,缓解在稳定扩散中的忽视)。
Overview of typical ways of interpreting CNNs - GradCAM, LRP, grad x input, SHAP, LIME, Integrated Gradients
Transformers 导论 Short introduction to Transformers
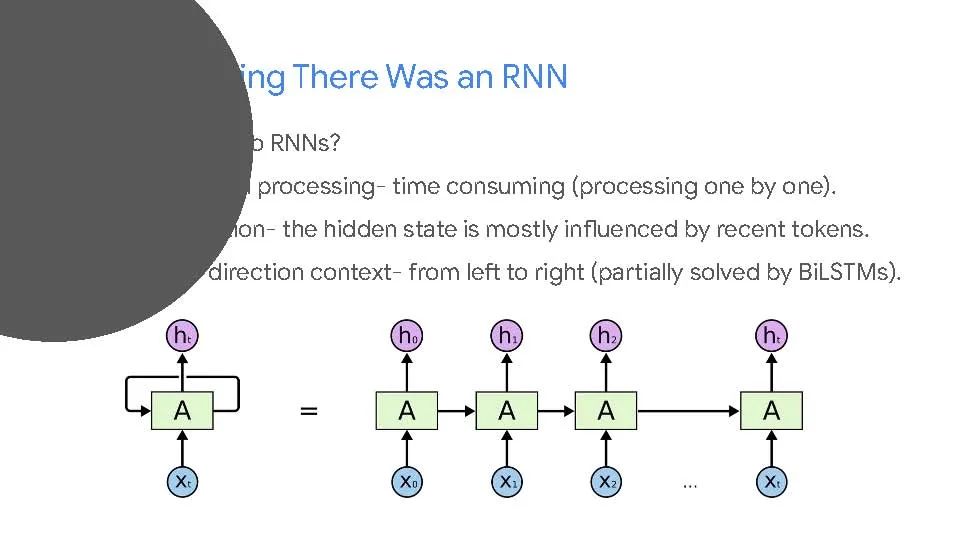
The attention mechanism Positional encoding Integrating attention maps from different modalities via cross-attention Probing Transformers: understanding what Transformers learn from images [1, 2, 3, 4, 5]
Mean attention distance (relative receptive field) Centered kernel alignment The role of skip connections Why do we need different methods to interpret Transformers?
Is attention an explanation? If so, under what conditions? Explaining predictions made by Transformers (XAI) Algorithms to explain attention
Attention rollout [6] Attention flow (shortly since it’s computationally expensive) [6] Transformer Interpretability Beyond Attention Visualization [7] Understanding what Transformers learn from multiple modalities [8] Attention as explanation
Class attention [10] Attention for semantic segmentation (DINO, [11]) Leveraging attention for downstream tasks
Ron Mokady sharing his seminal research on employing attention for text-based image editing ([12, 13]) Using cross-attention to guide text-to-image generation models ([14]) Open questions
How do we evaluate these explainability methods? Are smaller Transformer models better than the larger ones as far as explainability is concerned? Is attention a good way to interpret Transformers in the first place? Why do methods for CNNs not perform well on Transformers? (e.g. the adaptation of GradCAM to Transformers does not seem to work, even though the intuition is rather similar) * Conclusion and Q&A
参考文献:
[1] Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers, Chefer et al. [2] Do Vision Transformers See Like Convolutional Neural Networks?, Raghu et al. [3] What do Vision Transformers Learn? A Visual Exploration, Ghiasi et al.[4] Quantifying Attention Flow in Transformers, Abnar et al. [5] Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models, Chefer et al. [6] Prompt-to-Prompt Image Editing with Cross-Attention Control, Hertz et al. [7] NULL-text Inversion for Editing Real Images using Guided Diffusion Models, Mokady et al.