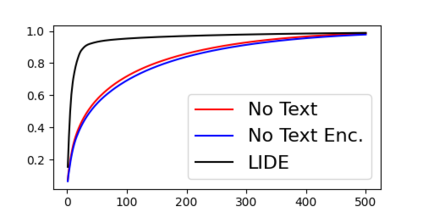
Humans can obtain the knowledge of novel visual concepts from language descriptions, and we thus use the few-shot image classification task to investigate whether a machine learning model can have this capability. Our proposed model, LIDE (Learning from Image and DEscription), has a text decoder to generate the descriptions and a text encoder to obtain the text representations of machine- or user-generated descriptions. We confirmed that LIDE with machine-generated descriptions outperformed baseline models. Moreover, the performance was improved further with high-quality user-generated descriptions. The generated descriptions can be viewed as the explanations of the model's predictions, and we observed that such explanations were consistent with prediction results. We also investigated why the language description improved the few-shot image classification performance by comparing the image representations and the text representations in the feature spaces.
翻译:人类可以从语言描述中获得关于新视觉概念的知识,因此,我们使用微小图像分类任务来调查机器学习模型能否具备这种能力。我们提议的模型LIDE(从图像和删除中学习)有一个文本解码器来生成描述和文本编码器,以获得机器或用户生成描述的文字表述。我们确认,由机器生成描述的LIDE比机器生成描述的基线模型要好。此外,通过高质量的用户生成描述,其性能得到了进一步的改进。生成的描述可以被视为模型预测的解释,我们发现这些解释与预测结果一致。我们还调查了语言描述为什么通过比较特征空间的图像描述和文本表达方式来改进少量图像分类的性能。