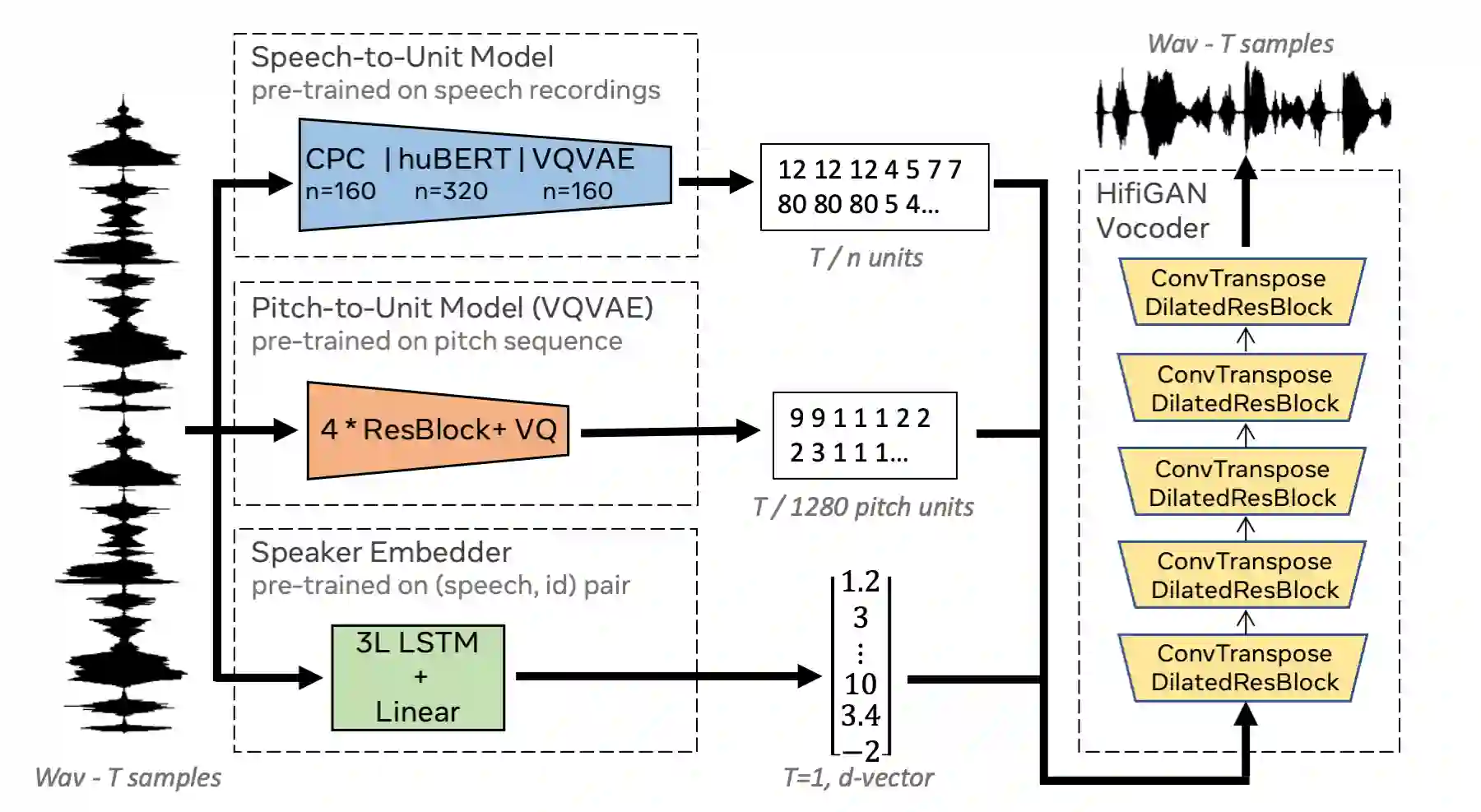
We propose using self-supervised discrete representations for the task of speech resynthesis. To generate disentangled representation, we separately extract low-bitrate representations for speech content, prosodic information, and speaker identity. This allows to synthesize speech in a controllable manner. We analyze various state-of-the-art, self-supervised representation learning methods and shed light on the advantages of each method while considering reconstruction quality and disentanglement properties. Specifically, we evaluate the F0 reconstruction, speaker identification performance (for both resynthesis and voice conversion), recordings' intelligibility, and overall quality using subjective human evaluation. Lastly, we demonstrate how these representations can be used for an ultra-lightweight speech codec. Using the obtained representations, we can get to a rate of 365 bits per second while providing better speech quality than the baseline methods. Audio samples can be found under https://resynthesis-ssl.github.io/.
翻译:我们建议使用自我监督的离散表达方式来完成语音合成任务。 为了产生分解的表达方式, 我们分别提取低位表达方式, 用于表达内容、 预想信息和发言者身份。 这样可以以可控制的方式合成语音。 我们分析各种最先进的自我监督的表达方式, 并在考虑重建质量和分解特性的同时, 阐明每种方法的优点。 具体地说, 我们用主观的人类评价来评估F0重建、 语音识别性能( 重复和声音转换)、 录音的智能性以及总体质量。 最后, 我们展示这些表达方式如何用于超轻量语言代码。 使用所获得的表达方式, 我们可以达到每秒365位, 同时提供比基线方法更好的语言质量。 音频样本可以在 https://resynthes-sl.github.io/ 下找到 。