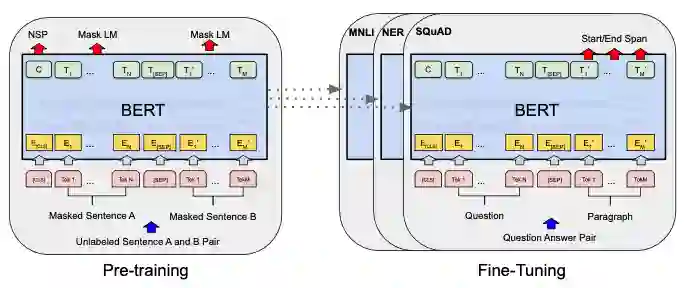
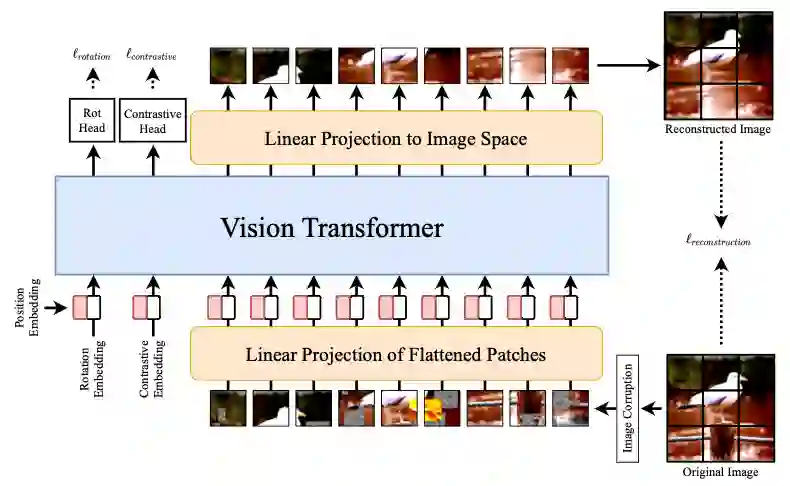
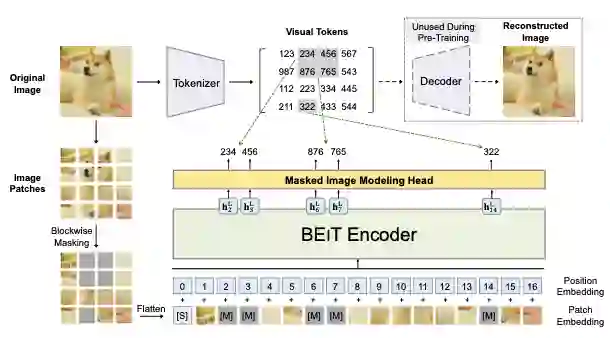
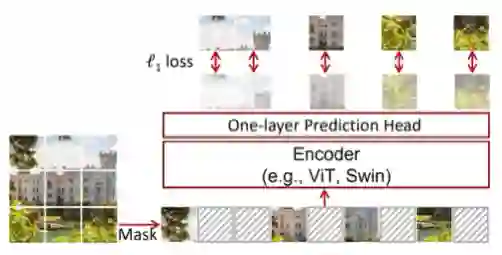
Self-supervised learning (SSL) methods such as masked language modeling have shown massive performance gains by pretraining transformer models for a variety of natural language processing tasks. The follow-up research adapted similar methods like masked image modeling in vision transformer and demonstrated improvements in the image classification task. Such simple self-supervised methods are not exhaustively studied for object detection transformers (DETR, Deformable DETR) as their transformer encoder modules take input in the convolutional neural network (CNN) extracted feature space rather than the image space as in general vision transformers. However, the CNN feature maps still maintain the spatial relationship and we utilize this property to design self-supervised learning approaches to train the encoder of object detection transformers in pretraining and multi-task learning settings. We explore common self-supervised methods based on image reconstruction, masked image modeling and jigsaw. Preliminary experiments in the iSAID dataset demonstrate faster convergence of DETR in the initial epochs in both pretraining and multi-task learning settings; nonetheless, similar improvement is not observed in the case of multi-task learning with Deformable DETR. The code for our experiments with DETR and Deformable DETR are available at https://github.com/gokulkarthik/detr and https://github.com/gokulkarthik/Deformable-DETR respectively.
翻译:自监督的学习方法,如隐形语言模型等,通过各种自然语言处理任务的预培训变压器模型显示,通过各种自然语言处理任务的预培训变异器变异器变异器变异器模型的巨大性能收益。后续研究调整了类似方法,如在视觉变异器变异器中蒙面图像模型和图像分类任务的改进。这种简单的自监督方法对于物体探测变异器(DETR、变形变异的DETR)模块而言,并没有进行彻底研究,因为其变异器变异器变异器模块在聚合神经网络(CNN)提取的特性空间而不是像一般的图像变异器一样的图像空间,显示出巨大的性能效益。然而,CNN 特征图仍然维持着空间关系,我们利用这一属性设计了自我监督的学习方法,设计了在预培训和多任务学习环境中的物体探测变异器变异变器的编码器。我们探索了基于图像重建、遮蔽图像模型建模的通用的自我监督方法。iSAIDDRADTRK/Decomkar在前和多任务学习设置中都观察到了类似的改进。