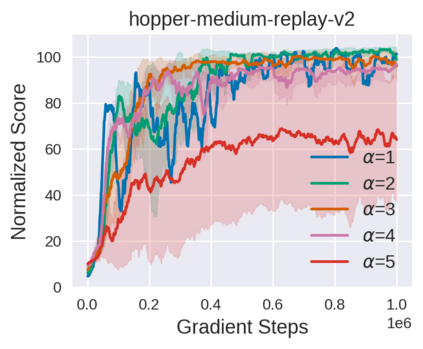
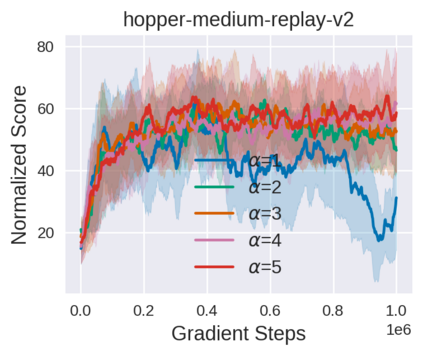
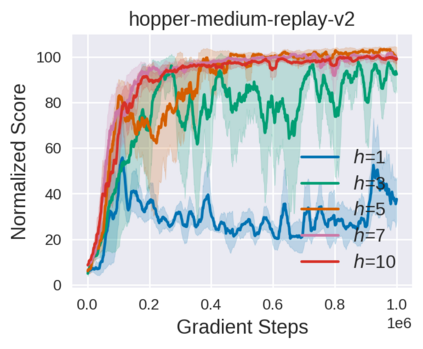
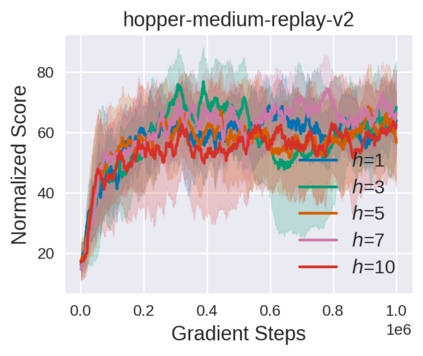
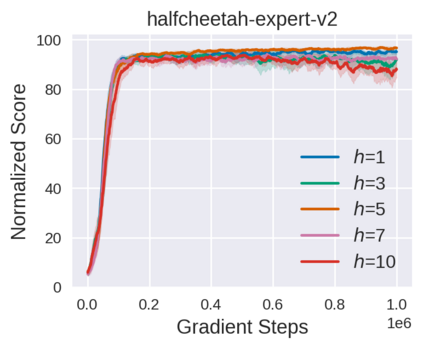
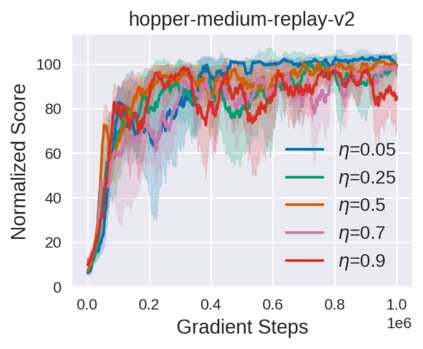
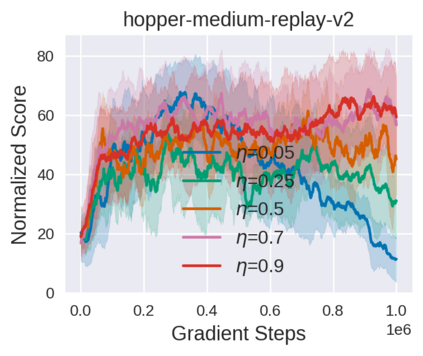
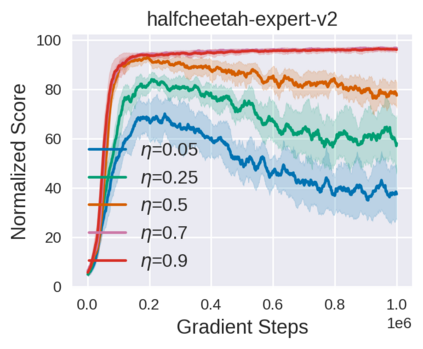
Equipped with the trained environmental dynamics, model-based offline reinforcement learning (RL) algorithms can often successfully learn good policies from fixed-sized datasets, even some datasets with poor quality. Unfortunately, however, it can not be guaranteed that the generated samples from the trained dynamics model are reliable (e.g., some synthetic samples may lie outside of the support region of the static dataset). To address this issue, we propose Trajectory Truncation with Uncertainty (TATU), which adaptively truncates the synthetic trajectory if the accumulated uncertainty along the trajectory is too large. We theoretically show the performance bound of TATU to justify its benefits. To empirically show the advantages of TATU, we first combine it with two classical model-based offline RL algorithms, MOPO and COMBO. Furthermore, we integrate TATU with several off-the-shelf model-free offline RL algorithms, e.g., BCQ. Experimental results on the D4RL benchmark show that TATU significantly improves their performance, often by a large margin.
翻译:配备已训练好的环境动力学模型,模型基离线强化学习算法通常可以从固定大小的数据集中成功学习到良好的策略,即使一些数据集的质量较差。然而,可以不能保证从训练好的动力学模型生成的样本是可靠的(例如,一些合成样本可能位于静态数据集的支持区域之外)。为了解决这个问题,我们提出具有不确定性的轨迹截断(Trajectory Truncation with Uncertainty,TATU),如果沿轨迹累积的不确定性过大,则自适应地截断合成轨迹。我们从理论上证明了TATU的性能上限,以证明它的优点。为了实证TATU的优势,我们首先将其与两种经典的模型基离线强化学习算法MOPO和COMBO相结合。此外,我们将TATU与几种现成的无模型离线RL算法(例如,BCQ)结合起来。在D4RL基准测试上的实验结果表明,TATU显着提高了它们的性能,通常大幅提升。