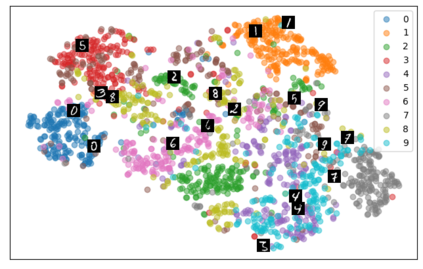
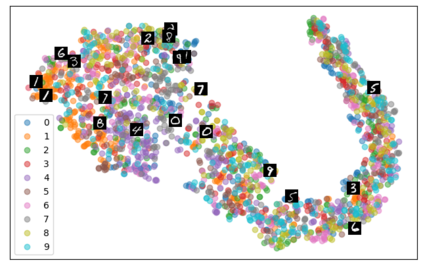
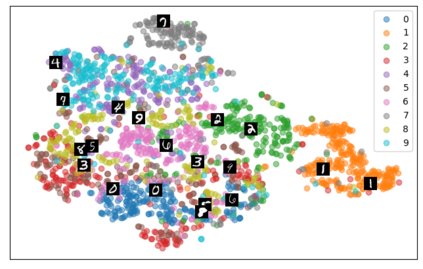
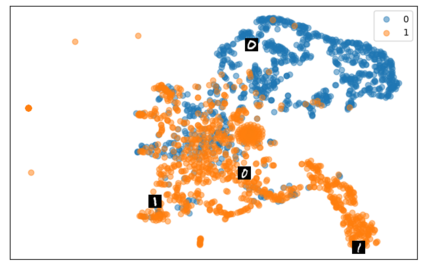
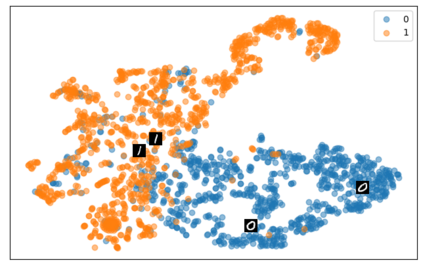
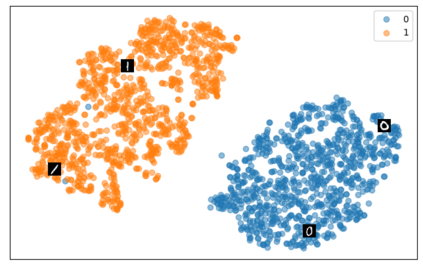
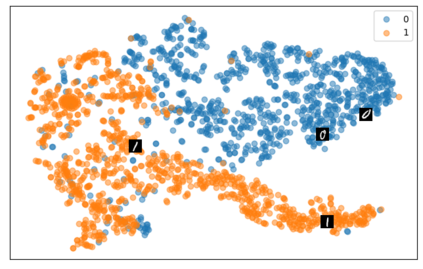
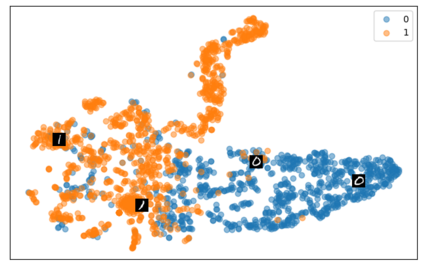
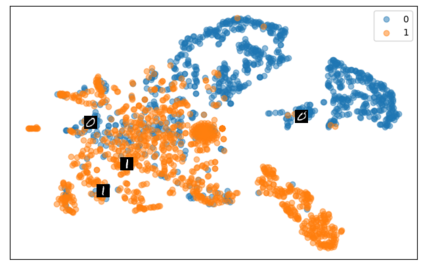
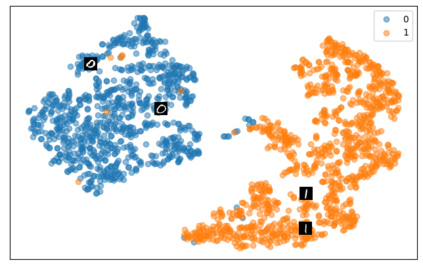
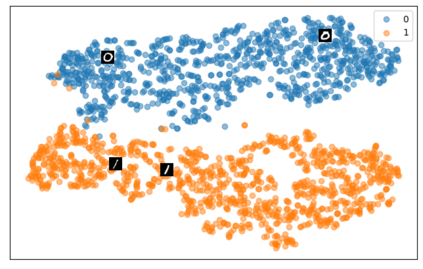
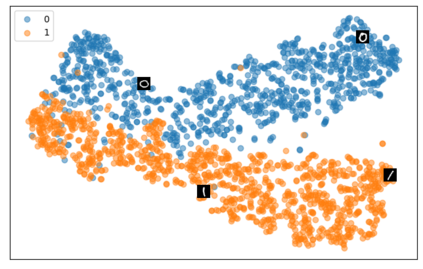
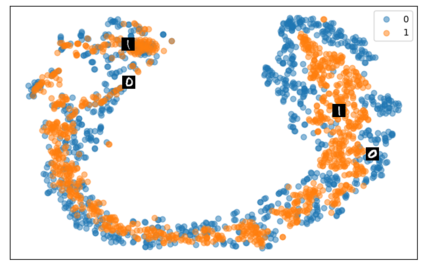
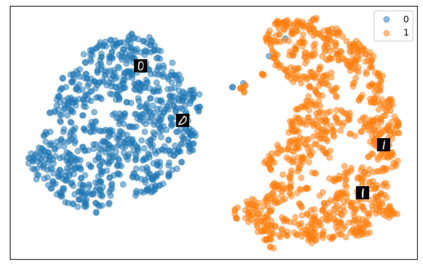
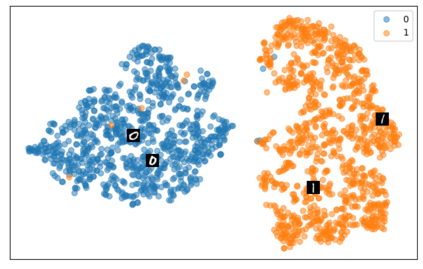
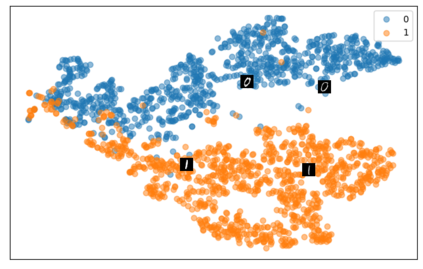
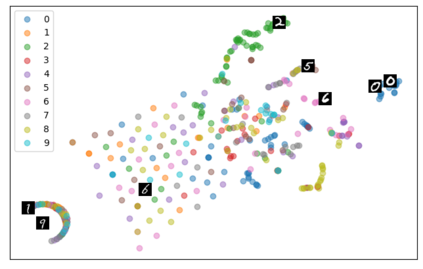
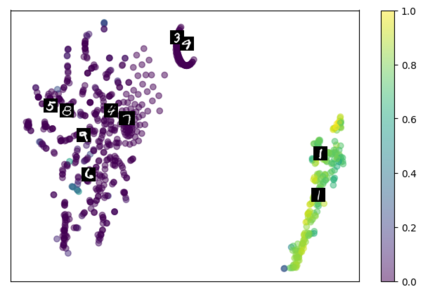
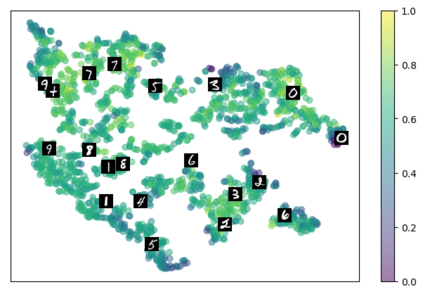
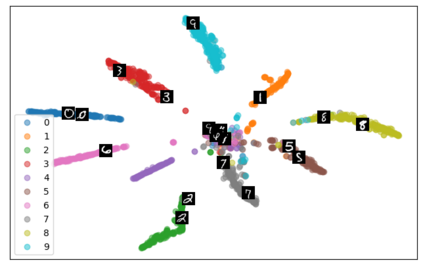
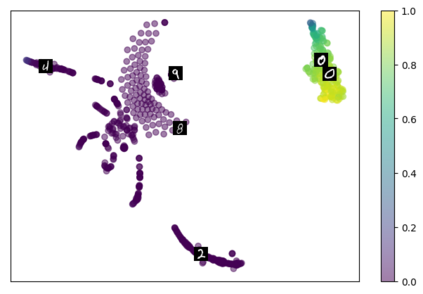
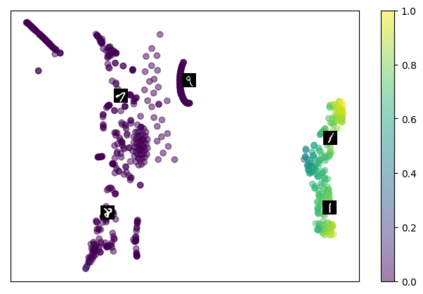
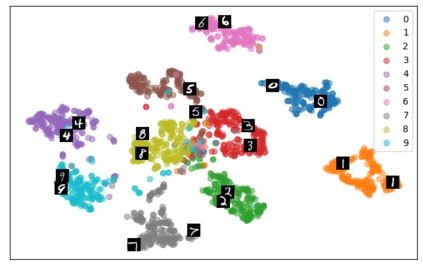
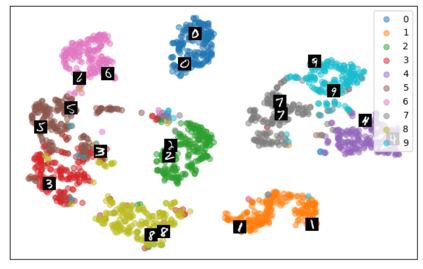
Self-supervised representation learning has seen remarkable progress in the last few years, with some of the recent methods being able to learn useful image representations without labels. These methods are trained using backpropagation, the de facto standard. Recently, Geoffrey Hinton proposed the forward-forward algorithm as an alternative training method. It utilizes two forward passes and a separate loss function for each layer to train the network without backpropagation. In this study, for the first time, we study the performance of forward-forward vs. backpropagation for self-supervised representation learning and provide insights into the learned representation spaces. Our benchmark employs four standard datasets, namely MNIST, F-MNIST, SVHN and CIFAR-10, and three commonly used self-supervised representation learning techniques, namely rotation, flip and jigsaw. Our main finding is that while the forward-forward algorithm performs comparably to backpropagation during (self-)supervised training, the transfer performance is significantly lagging behind in all the studied settings. This may be caused by a combination of factors, including having a loss function for each layer and the way the supervised training is realized in the forward-forward paradigm. In comparison to backpropagation, the forward-forward algorithm focuses more on the boundaries and drops part of the information unnecessary for making decisions which harms the representation learning goal. Further investigation and research are necessary to stabilize the forward-forward strategy for self-supervised learning, to work beyond the datasets and configurations demonstrated by Geoffrey Hinton.
翻译:暂无翻译