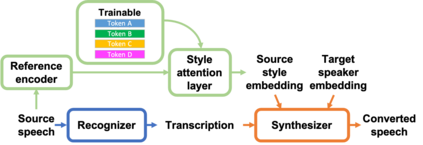
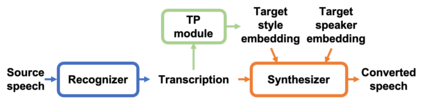
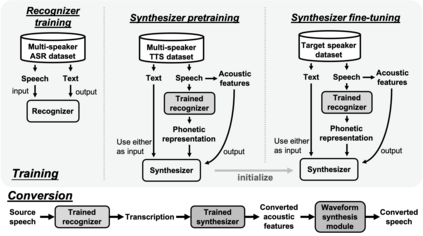
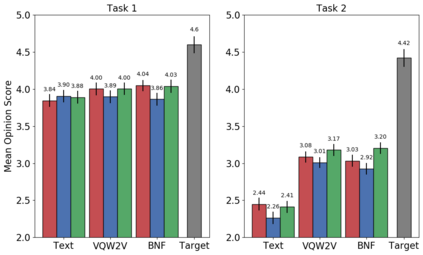
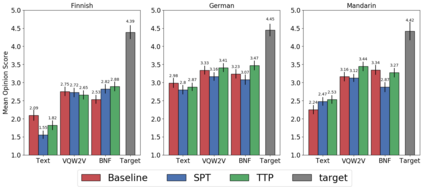
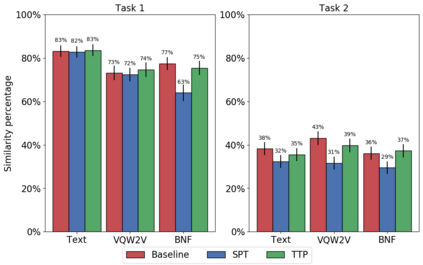
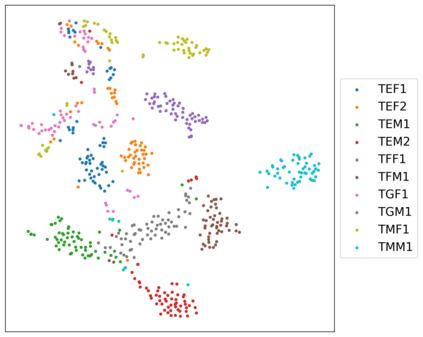
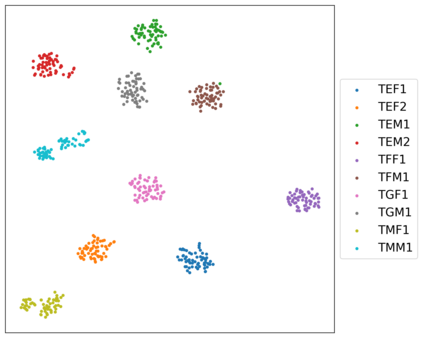
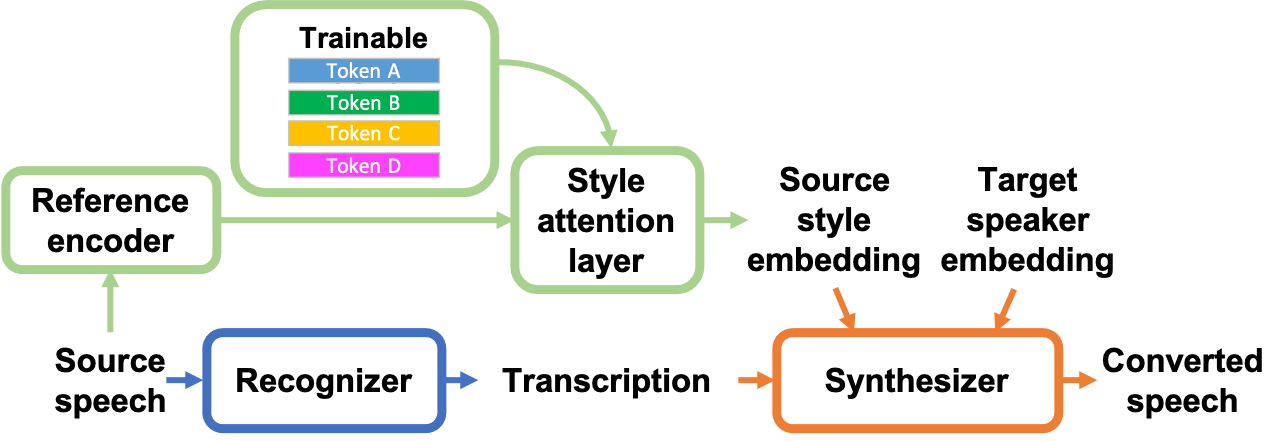
In voice conversion (VC), an approach showing promising results in the latest voice conversion challenge (VCC) 2020 is to first use an automatic speech recognition (ASR) model to transcribe the source speech into the underlying linguistic contents; these are then used as input by a text-to-speech (TTS) system to generate the converted speech. Such a paradigm, referred to as ASR+TTS, overlooks the modeling of prosody, which plays an important role in speech naturalness and conversion similarity. Although some researchers have considered transferring prosodic clues from the source speech, there arises a speaker mismatch during training and conversion. To address this issue, in this work, we propose to directly predict prosody from the linguistic representation in a target-speaker-dependent manner, referred to as target text prediction (TTP). We evaluate both methods on the VCC2020 benchmark and consider different linguistic representations. The results demonstrate the effectiveness of TTP in both objective and subjective evaluations.
翻译:在语音转换(VC)中,一种在最新的语音转换挑战(VCC)2020中显示有希望结果的方法是,首先使用自动语音识别(ASR)模式,将源语言内容转换成基本语言内容;然后,这些内容作为文字对语音转换(TTS)系统的投入,以生成转换的语音。这种模式被称为ASR+TTS, 忽略了在语言转换(VCC20)和转换相似性中发挥重要作用的手动模式。虽然一些研究人员已经考虑从源语言演讲中传递预断线索,但在培训和转换期间出现了发言者不匹配的问题。为了解决这一问题,我们提议直接预测语言表达方式的偏重于目标语言表达方式(TTP),称为目标文本预测(TTP)。我们评估了VCC20基准的两种方法,并考虑了不同的语言表达方式。结果表明TTP在客观和主观评价中的有效性。