业界 | 带有韵律的合成语音:谷歌展示基于Tacotron的新型TTS方法
选自Google Blog
作者:Yuxuan Wang、RJ Skerry-Ryan
机器之心编译
参与:黄小天、李亚洲、李泽南
神经网络文本转语音(TTS)是自然语言处理领域的重要方向,很多谷歌的产品(如 Google Assistant、搜索、地图)都内置了这样的功能。目前的系统已经可以产生接近人声的语音,但仍然显得不够自然。在最近发表的两篇论文中,谷歌为自己的 Tacotron 系统加入了对韵律学的建模,以帮助人们利用自己的声音进行个性化语音合成。
最近,谷歌在基于神经网络的文本转语音(TTS)的研究上取得重大突破,尤其是端到端架构,比如去年推出的 Tacotron 系统,可以同时简化语音构建通道并产生自然的语音。这有助于更好地实现人机交互,比如会话式语音助手、有声读物朗诵、新闻阅读器和语音设计软件。但是为了实现真正像人一样的发音,TTS 系统必须学习建模韵律学(prosody),它包含语音的所有表达因素,比如语调、重音、节奏等。最新的端到端系统,包括 Tacotron 在内,并没有清晰地建模韵律学,这意味着它们无法精确控制语音的发声。这致使语音听起来很单调,尽管模型是在字词发音有明显变化的极具表现力的数据集上训练的。今天,谷歌共享了两篇新论文,有助于解决上述问题。
谷歌 Tacotron 的第一篇论文《Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron》介绍了「韵律学嵌入」(prosody embedding)的概念。我们加强了附有韵律学编码器的 Tacotron 架构,可以计算人类语音片段(参考音频)中的低维度嵌入。
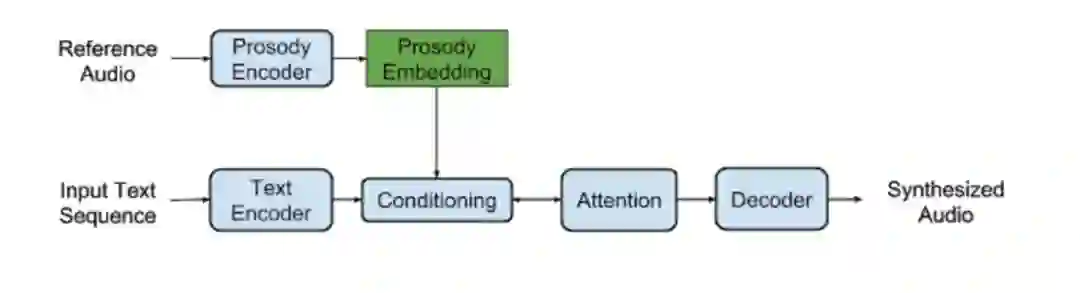
我们为 Tacotron 增加了一个韵律学编码器。上图的下半部分是原始的 Tacotron 序列到序列模型。技术细节请详见我们的第一篇论文。
该嵌入捕捉独立于语音信息和特殊的说话者特质的音频特征,比如重音、语调、语速。在推理阶段,我们可以使用这一嵌入执行韵律学迁移,根据一个完全不同的说话者的声音生产语音,但是体现了参考音频的韵律。

嵌入也可以将时间对齐的精确韵律从一个短语迁移到稍微不同的短语,尽管当参考短语和目标短语的长度和结构相似时,该技术效果最好。

令人激动的是,甚至当 Tacotron 训练数据不包含说话者的参考音频时,我们也可以观察到韵律迁移。
这是一个很有希望的结果,它为语音交互设计者利用自己的声音自定义语音合成铺平了道路。你可以从网页上试听所有的音频。
Demo 链接:https://google.github.io/tacotron/publications/end_to_end_prosody_transfer/。
尽管有能力迁移带有高保真度的韵律,上述论文中的嵌入并没有将参考音频片段中的韵律与内容分开。(这解释了为什么迁移韵律对相似结构和长度的短语效果最佳)此外,它们在推断时需要一个参考音频片段。这引起了一个自然的问题:我们可以开发一个富有表现力的语音模型来缓解这些问题吗?
这正是我们在第二篇论文《Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis》中所要做的。在第一篇论文的架构之上,我们提出了一种建模潜在语音「因素」的无监督新方法。这一模型的关键是其学习的是较高层的说话风格模式而不是时间对齐的精确的韵律学元素,前者可在任意不同的短语之中迁移。
通过向 Tacotron 多增加一个注意机制,使得它将任何语音片段的韵律嵌入表达为基础嵌入固定集合的线性组合。我们把这种嵌入称之为 Global Style Tokens (GST),且发现它们能学习一个声纹风格中的文本无关变化(柔软、高音调、激烈等)——不需要详细的风格标签。
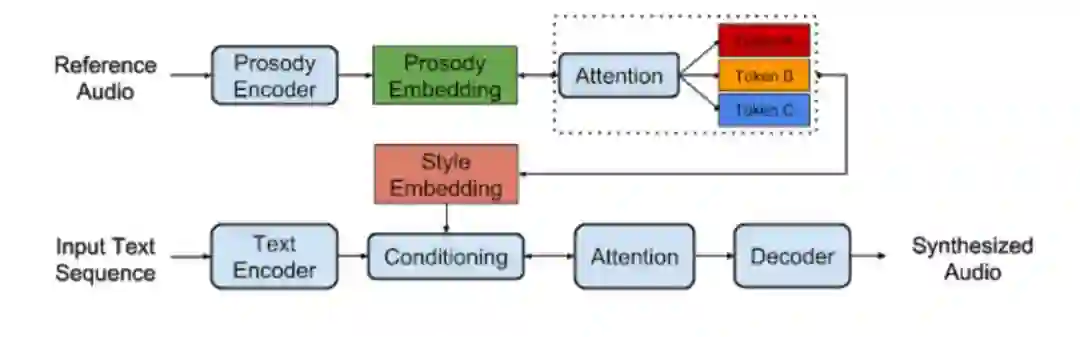
Global Style Tokens 的模型架构。韵律嵌入被分解成了「style tokens」,从而做到无监督的风格控制和迁移。更多技术细节,请查看文后论文。
在推理时间,我们可以选择或者调整 tokens 的结合权重,让我们能够迫使 Tacotron 使用特定的说话风格,不需要参考语音片段。例如,使用 GST,我们能创造出语音长度多样化的不同语句,更为「活泼」、「气愤」、「悲伤」等:

GST 文本无关的特性使得它们能更理想的做风格迁移,采用特定风格的语音片段,将其风格转换为我们选择的任意目标语句。为了做到这一点,我们首先推理预测我们想要模仿风格的 GST 组合权重。然后,把这些组合权重馈送到模型,从而合成完整的不同语句,即使长度、结构不同,但风格一样。
最后,我们的论文表明,Global Style Tokens 不只能建模说话风格。当从 YouTube 未标记声纹的噪声语音上训练时,带有 GST 的 Tacotron 系统能学习表示噪声源,把不同声纹区分成独立 tokens。这意味着通过选择在推理中使用的 GST,我们能合成没有背景噪声的语音,或者合成数据集中特定未标记声纹的语音。这一激动人心的成果为我们打开了一条通向高延展且稳健的语音合成之路。详情可参见论文:Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis。
对以上介绍的两种研究的潜在应用和机遇,我们非常兴奋。同时,也有很多重要的研究问题亟待解决。我们期望把第一篇论文中的技术扩展到在目标声纹的天然音域范围中支持韵律迁移。我们也希望开发一种技术能够自动从语境中选择合适的韵律或者说话风格,例如结合 NLP 和 TTS。最后,虽然第一篇论文提出了一种做韵律迁移的客观与主观标准,但我们想要进一步的开发,从而帮助简历韵律评估的普遍可接受方法。
论文 1:Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron

论文链接:https://google.github.io/tacotron/publications/end_to_end_prosody_transfer/Towards%20End%20to%20End%20Prosody%20Transfer%20for%20Expressive%20Speech%20Synthesis%20with%20Tacotron.pdf
在此论文中,我们提出了对 Tacotron 语音合成架构的扩展,让它能够从包含想要韵律的声学表征中学习韵律的隐藏嵌入空间。我们表明,即使参照声纹与合成声纹不同,这种条件的 Tracotron 学习嵌入空间合成的语音在时间细节上极其匹配参照信号。此外,我们在文中展示了可使用参照韵律嵌入来合成不同于参照语句的文本。我们定义了多种定量以及主观性的度量标准,来评估韵律迁移,且随韵律迁移任务中的 Tacotron 模型采样自单个说话人和 44 个说话人的语音样本一起报告了结果。
论文 2:Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis

论文链接:https://google.github.io/tacotron/publications/global_style_tokens/Style%20Tokens%20Unsupervised%20Style%20Modeling%20Control%20and%20Transfer.pdf
在此研究中,我们提出了 global style tokens」(GST),一个由 Tacotron 共同训练的嵌入库——后者是目前业内最佳的端到端语音合成系统。该嵌入的训练没有明确的标签,但仍然为相当广泛的语音表达能力进行了建模。GST 引出了一系列重要结果,其生成的软可解释「标签」可以用于以全新的方式控制合成,如独立于文本长度地合成不同速度与讲话语调的声音。它们也可以用于进行风格迁移,从单一语音剪辑中复制出说话风格,并用于整段长文本语料中。在经过充满噪音、无标签的数据训练之后,GST 可以学会区分噪音和说话人的声音,该研究为高度可扩展且具有鲁棒性的语音合成打开了道路。
同时,谷歌也将自己的语音合成技术在 Google Cloud 平台上开放,我们现在可以在多种应用中植入 Cloud Text-to-Speech,如让物联网设备对人类的指令做出应答,或制作自己的有声读物。
链接:https://cloud.google.com/text-to-speech/
目前,该服务包含 32 种音色,支持 12 种语言。谷歌宣称其服务对 1 秒钟时长的语音反应速度仅为 50 毫秒,而价格为每处理 100 万字 16 美元。

原文链接:https://research.googleblog.com/2018/03/expressive-speech-synthesis-with.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



